ゆるい均衡を使った構築評価 -最適でない構築の強さを定量化する-
目的
ポケモン等の複雑なゲームにおいて、すべての構築をナッシュ均衡の枠組みだけで評価することは困難です。本記事では、厳密な均衡に含まれない多くの構築が「どの程度均衡に近いのか」を測る尺度を導入し、構築を改善するための指針を得る方法について解説します。
この記事でわかること
- ナッシュ均衡(最強)に含まれない多くの構築を、公平に評価するための考え方
- 期待値の計算だけで「その構築がどれだけ環境に適応しているか」を数値化できるシンプルな指標
- その指標(環境乖離度)が、数学的にどのような裏付け(ゆるい均衡)を持っているのかという根拠
この記事でわからないこと
- 具体的なゲーム(ポケモン等)の環境分析や、特定の構築に対する具体的な評価値の提示
- 算出された指標をもとに、具体的にどう構築を改善すべきかという実践的なノウハウ
- この指標を実際の対戦シーンで活用した際の、具体的な成功事例やエピソードの紹介
ナッシュ均衡による評価の限界と「ゆるい」評価の必要性
ポケモン対戦では、ポケモンの種類、技、努力値などの組み合わせにより、無数の構築が作成可能です。しかし、ゲーム理論における「ナッシュ均衡」という条件は非常に厳しく、これらの膨大な構築のうち、最上位と呼べるごく少数の構築しか評価の土俵に上がることができません。
例えば、実際の計算実験では以下のような場面が見られます。
- 100構築で均衡を計算しても、均衡解で確率が非ゼロ(採用圏内)になったのはわずか 8個 だけだった。 ポケモンの見せ合い選出のナッシュ均衡 part08 Double Oracleアルゴリズムの実装【PokéAI】
- 1292通りの候補に対してナッシュ均衡を計算しても、わずか 9個 の構築(純粋戦略)からなる均衡しか得られなかった。 いやしのはどう1on1の最適解をシミュレーションで求める【ポケモンバトル仲間大会】
このように、ナッシュ均衡に含まれるかどうかだけで評価すると、残りの圧倒的多数の構築はすべて「一律でダメ(使用率0)」という扱いになってしまいます。これでは、自分の構築をどのように改善していけばいいのか、そのグラデーションを捉えることができず、カジュアルに分析を楽しむには非常に不便です。
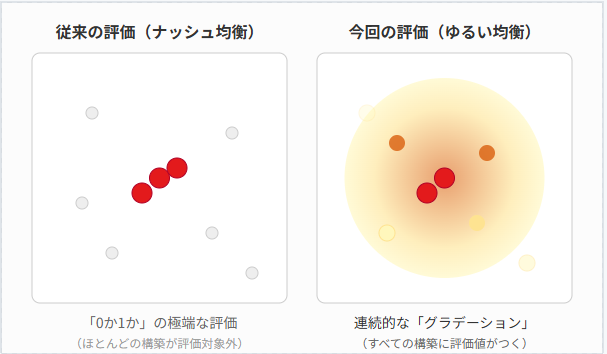 評価方法の比較
評価方法の比較
実用上、後から振り返れば最適ではなかった状態からでも、少しずつ良くしていくためには、現在の構築が「どれくらいマシなのか」を測る指標が不可欠です。
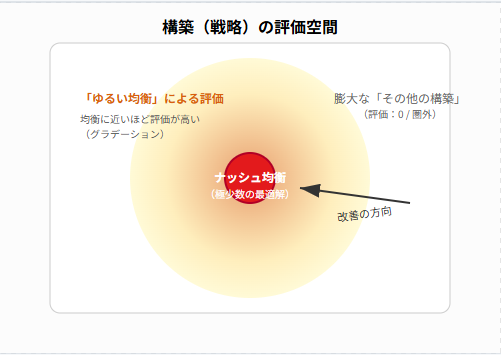 構築の評価空間のイメージ
構築の評価空間のイメージ
今回の指標は、少数しかないナッシュ均衡そのものを目指すためのものではなく、数多ある「まだ最適ではない構築」の中で、どれが比較的マシなのかを可視化し、改善のステップを明確にするために導入します。
上の図に示した「グラデーション」を具体的にどうやって数値にするのか、その考え方のエッセンスを整理してみましょう。
方法・方針
ナッシュ均衡(最適解)ではない構築を評価するために、本記事では「その構築が環境に存在することで、環境全体がどれだけ均衡から引き剥がされるか」という逆転の発想をとってみます。
ある構築が均衡で採用されていないということは、その構築を無理に使おうとすると、環境全体にはどうしても「無理」や「歪み」が生じてしまいます。この歪みの小ささを比べることで、均衡から少ししかずれていない構築は「弱い」構築の中でも比較的マシ、大きな歪みを生む場合は環境に馴染みにくい構築、と評価できそうです。
具体的には、以下のようなステップで考えていきます。
- 環境の「歪み」を定義する:
まず、現在の環境(みんなが使っている構築の比率)が、ナッシュ均衡からどれだけズレているかを「誤差」として定義します。 - 特定の構築を「無理やり」使ってみる:
評価したい構築を、あえて一定の割合(例えば1%だけ)強制的に環境に混ぜてみます。 - 環境全体の反応を最小化する:
その構築が混ざった状態で、自分も相手もできるだけ全体の誤差が小さくなるように振る舞ったとき、どうしても残ってしまう「最小の歪み」を計算します。
この「どうしても残る歪み」が小さいほど、その構築は現在の環境に馴染みやすく、強い(あるいは改善の余地が近い)とみなすことができそうです。
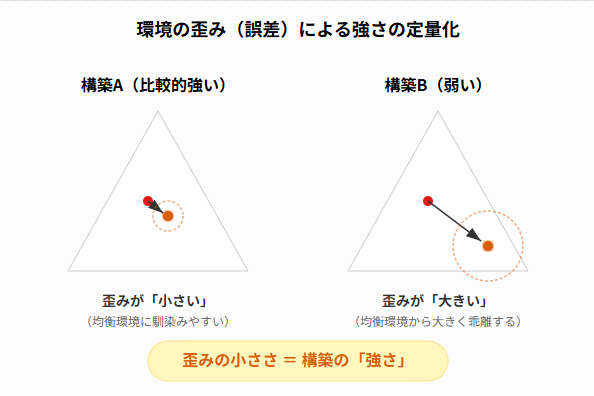 環境の歪みによる強さの定量化
環境の歪みによる強さの定量化
このようにして強さを測定するアプローチを、次章では数学的な定義へと落とし込み、驚くほどシンプルな計算式が導かれる様子を見ていきます。
計算
全体の方針
本章では、ナッシュ均衡に限定されない一般的な構築の採用率(混合戦略)の評価尺度として「ゆるい均衡」を定義し、そこから特定の構築(純粋戦略)の強さを表す「環境乖離度」を導出します。
まず、任意の構築の採用率の組 $(s, s')$ に対して、互いにどれだけ最適応答から外れているかを示す誤差 $\epsilon$ を定義します。次に、特定の構築 $i$ を一定の割合で使用することを強制したときに、環境全体(自分と相手の最適な応答)で生じる最小の誤差をその構築の「強さ」とみなします。最後に、この定義を線形近似することで、実用上非常に計算しやすい「均衡環境における評価」へと帰着することを数学的に示します。
ゆるい均衡の定義
二人零和ゲームにおいて、自分と相手の構築の採用率の組 $(s, s')$ がどれだけナッシュ均衡に近いかを表す尺度として、$\epsilon$-ナッシュ均衡の考え方を導入します。
プレイヤーの利得関数を $u(s, s')$ とし、対称なゲーム($u(s, s') = -u(s', s)$)を想定します。このとき、ゲームの値は $g^* = 0$ です。構築の採用率の組 $(s, s')$ における「ズレの大きさ」 $\epsilon(s, s')$ を以下のように定義します。
$$ \epsilon(s, s') = \max \{ \max_{t} u(t, s') - u(s, s'), u(s, s') - \min_{t'} u(s, t') \} $$
ここで、第1項は「相手の構築の採用率 $s'$ に対して、自分が採用する構築 $t$ を変更することで得られる利得の最大改善幅」を、第2項は「自分の構築の採用率 $s$ に対して、相手が採用する構築 $t'$ を変更することで得られる利得の最大改善幅(自分の利得の最大減少幅)」を表します。
ナッシュ均衡 $(s^*, s^*)$ においては、どちらのプレイヤーも利得を改善できないため、$\epsilon(s^*, s^*) = 0$ となります。
構築の強さ(環境乖離度)の定義
ある特定の構築(純粋戦略) $i$ が、環境においてどの程度「強い」のかを評価するために、環境乖離度 $\kappa_i$ を定義します。
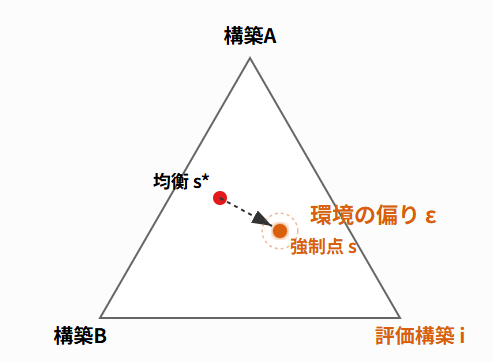 環境乖離度の定義イメージ
環境乖離度の定義イメージ
構築 $i$ を微小な割合 $\delta$ だけ強制的に採用率(混合戦略) $s$ に組み込んだとき、自分と相手が互いに最適な応答(=誤差 $\epsilon$ を最小化するような採用率の選択)をとったとしても避けられない最小の誤差を考えます。この誤差 $\epsilon$ は、$\delta$ が十分小さい範囲で $\epsilon \approx \kappa_i \delta$ のように $\delta$ に比例することが期待されるため、その比例係数を環境乖離度と呼ぶことにします。
この定義は、上の図のように「その構築を使いつつ、環境全体が最も均衡に近い状態(ゆるい均衡)に落ち着いた場合に、どれだけの歪み(誤差)が残るか」を意味しています。
$$ \kappa_i = \lim_{\delta \to 0} \frac{1}{\delta} \min_{s: s_i \ge \delta, s'} \epsilon(s, s') $$
線形近似による導出
定義に基づき、$\kappa_i$ の具体的な値を導出します。ナッシュ均衡における構築の採用率を $s^*$ とします。ここでは、構築 $i$ はナッシュ均衡に含まれていない($s^*_i = 0$)場合を想定します。
$\delta$ が微小であるとき、最小値を与える構築の採用率 $s$ は $s^*$ の近傍にあると考えられます。そこで、変数を以下のように取り直します。
$$ s = s^* + \delta e_i + \Delta s $$
ここで、$\sum_j s_j = 1$ かつ $s_i \ge \delta$ という条件から、$\Delta s$ は以下の制約を満たします。
- $\sum_j \Delta s_j = -\delta$
- $\Delta s_i \ge 0$ (簡単のため $\Delta s_i = 0$ としても一般性を失いません)
- $s^* + \delta e_i + \Delta s \ge 0$ (各成分が非負)
また、対称零和ゲームの利得関数 $u(s, s') = s^T A s'$ ($A$ は交代行列、$A^T = -A$)に対し、ある構築の採用率 $x$ に対する最適応答利得を $f(x) = \max_{t} u(t, x) = \max_k (Ax)_k$ と定義します。
このとき、誤差関数は以下のように書けます。
$$ \epsilon(s, s') = \max \{ f(s') - s^T A s', f(s) + s^T A s' \} $$
任意の $A, B$ に対して $\max(A, B) \ge \frac{A+B}{2}$ が成り立つため、
$$
\epsilon(s, s') \ge \frac{f(s) + f(s')}{2}
$$
となります。
この下限は、自分と相手が誤差を等分に引き受ける($s^T A s' = \frac{1}{2}(f(s') - f(s))$ となる)ように $s, s'$ が調整されたときに達成されます。環境全体での最小誤差を求めるため、まず制約のない $s'$ について最小化すると、$\min_{s'} f(s') = g^* = 0$ ($s' = s^*$ のとき)であることから、
$$
\min_{s, s'} \epsilon(s, s') = \frac{1}{2} \min_{s} f(s)
$$
となります。
次に、この値を最小化する $\Delta s$ を探します。
$f(s) = \max_k (As)_k$ は、任意の構築の採用率(混合戦略)による重み付き平均以上の値をとります。
特にナッシュ均衡における構築の採用率 $s^*$ による重み付き平均を考えると、
$$
\begin{aligned}
f(s) &\ge (s^*)^T A s \\
&= (s^*)^T A (s^* + \delta e_i + \Delta s) \\
&= (s^*)^T A s^* + \delta (s^*)^T A e_i + (s^*)^T A \Delta s
\end{aligned}
$$
ここで、$(s^*)^T A s^* = g^* = 0$ です。
また、交代行列の性質より $(s^*)^T A e_i = -e_i^T A s^* = -g_i$ です。
第3項については、
$$
(s^*)^T A \Delta s = -\Delta s^T A s^* = - \sum_{j} \Delta s_j (As^*)_j
$$
となります。
ナッシュ均衡の性質から、すべての $j$ に対して $(As^*)_j \le g^* = 0$ であり、特に $s^*$ のサポート(使用率が正の構築)においては $(As^*)_j = 0$ です。
したがって、$\Delta s$ の成分を $s^*$ のサポート内に限定して選ぶことで、$\sum \Delta s_j (As^*)_j = 0$ となり、下限を実現できます。
具体的には $\Delta s = -\delta s^*$ と置くことで、合計を $1$ に保ちつつ $i$ 成分以外の比率を維持したまま、下限である
$$
f(s) \ge \delta (g^* - g_i)
$$
を達成できます。
したがって、環境乖離度は以下のようになります。
$$
\kappa_i = \lim_{\delta \to 0} \frac{1}{\delta} \cdot \frac{1}{2} \delta (g^* - g_i) = \frac{1}{2} (g^* - g_i)
$$
結論
以上の導出により、「特定の構築を含んだ時に、環境全体がどれだけ均衡からズレるか」という環境乖離度の定義が、単に「その構築をナッシュ均衡環境で使った時の損失($g^* - g_i$)の半分」という極めてシンプルな値に一致することが示されました。
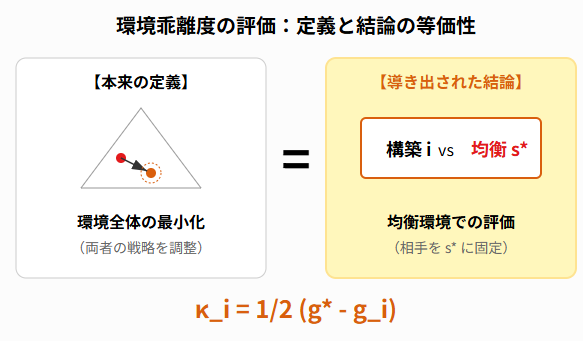 環境乖離度の等価性
環境乖離度の等価性
本来、ある構築の評価を行うには「その構築が環境に混ざった時の周囲の反応」まで考慮して最小化問題を解く必要があります。しかし、驚くべきことに、その結果は「相手の戦略をナッシュ均衡 $s^*$ に固定して、その構築を使った時の期待値を測るだけ」という非常にシンプルな計算に帰着します。
これにより、複雑な再計算を行うことなく、現在の環境に対する各構築の期待値を計算するだけで、その構築の「環境への適応度」を理論的に正当な形で評価できることが保証されます。
まとめ
ある構築(純粋戦略)のその環境における強さを表す指標として $i$ の環境乖離度 $\kappa_i$ を定義し計算しました。計算の結果、「ナッシュ均衡におけるゲームの値 $g^*$ と、その構築を均衡環境にぶつけた時の利得 $g_i$ との差の半分」に等しいことが導かれました。
対称零和ゲーム($g^* = 0$)においては、単に構築 $i$ がどれだけ負け越しているかの半分($-g_i / 2$)がそのままその構築の「弱さ(環境からの離れ具合)」の指標となります。
あとがき
お疲れ様です。
ナッシュ均衡になる時の使用率を求める計算は教科書的な例題としてそれなりに取り上げられますが、均衡から零れるような弱い構築に対しても評価できると便利なので強さの指標を導入してみました。
定義そのものはややこしめになっていますが、計算してみたらとても単純に均衡に対する利得を考えるだけでよくなったのでビックリでした。
今回の結果を使って構築一つ一つに「強さ」的なものを定義したら、それがどういう時に大きくなるかを計算することで構築を改善するための指針とすることが出来ます。ごく一部の構築以外、「ナッシュ均衡での使用率0%」とグラデーションなく塗りつぶされていた現状から前進できそうです。
これを使うと具体的にどんな良いことがあるのか、みたいな話題はまた別途記事を作成したいと思います。乞うご期待です。
ではまた~~~。




