[ラビットチャレンジ] 深層学習day4 レポート
はじめに
本稿は、E資格の受験資格の取得を目的としたラビットチャレンジの受講に伴うレポート記事である。
Section1:強化学習
強化学習とは
強化学習とは、教師あり学習、教師なし学習に並ぶ機械学習の一分野である。
与えられた環境のなかで報酬を最大化できるような行動を選択するよう、エージェントを学習させることを指す。行動の結果として与えられる利益をもとに、行動を決定する原理を改善していく仕組みを構築する。
教師あり学習、教師なし学習では、データに含まれるパターンを見つけ出すおよびそのデータから予測することが目標であるが、強化学習では、優れた方策を見つけることが目標である。
強化学習にとって冬の時代があったが、計算速度の進展により大規模な状態をもつ場合の、強化学習を可能としつつある。
強化学習の全体像と応用例
全体的なイメージは以下の図の通り。
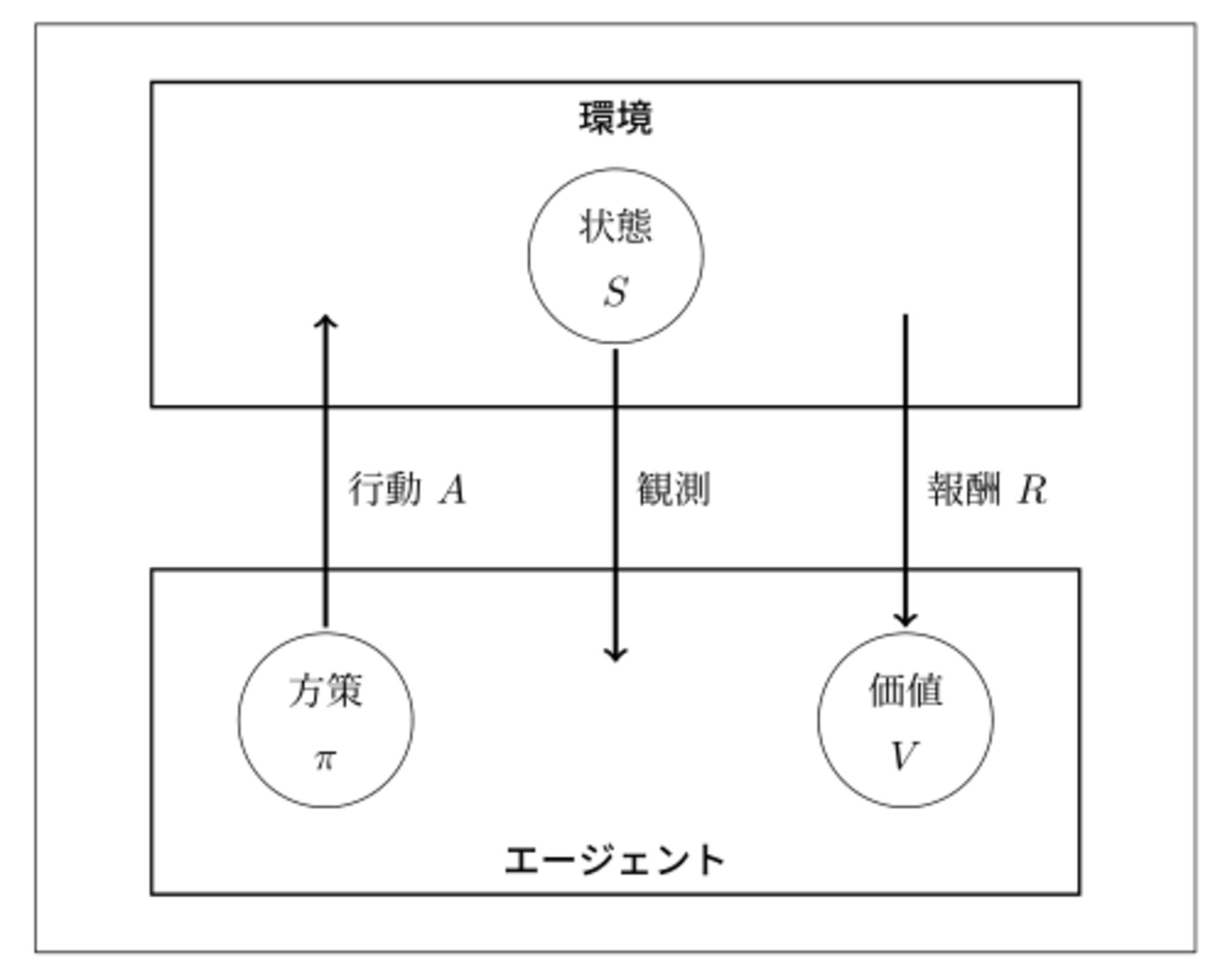 全体的なイメージ
全体的なイメージ
強化学習に必要な概念は以下の通り。
状態:エージェントが環境において置かれた状態のことを指す。行動によって状態は変化する。
方策:状態を踏まえ、エージェントがどのように行動するのかを定めたルールのことを指す。
価値:その時点で貰える利益ではなく、(将来に渡り得られる)利益を指す。
行動:エージェントが環境に働きかける内容を指す。エージェントは複数の方策の中から1つを選択する。
報酬:エージェントがある状態において、ある行動を起こした結果として、得られた利益のことを指す。
マーケティングを例にとると、以下が考えられる。
- 環境:会社の販売促進部
- エージェント : プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアである。
- 行動 : 顧客ごとに送信、非送信のふたつの行動を選ぶことになる。
- 報酬 : キャンペーンのコストという負の報酬とキャンペーンで生み出されると推測される売上という正の報酬を受ける。
探索と利用のトレードオフ
以下のように、探索と利用にはトレードオフの関係性がある。
- 探索が足りない状態
「過去のデータで、ベストとされる行動」のみを常に取り続けると、他にもっとベストな行動を見つけることはできない。 - 利用が足りない状態
未知の行動のみを常に取り続ければ、過去の経験が活かせない。
評価に用いる関数
価値関数
価値関数とは、その名の通り、価値を評価する関数のことを指す。
- 状態価値関数$V^{\pi}(s)$ : ある状態の価値に注目するときに用いる。状態$s \in S$により価値が決定する。
- 行動価値関数 $Q^{\pi}(s,a)$: 状態と価値を組み合わせた価値に注目するときに用いる。状態$s \in S$と行動$a \in A$から価値が決定する。
方策関数
方策関数$\pi(s) = a$とは、方策ベースの強化学習手法において、ある状態でどのような行動を採るのかの確率を与える関数のことを指す。
計算手法
- Q学習 : 行動価値関数を、行動する毎に更新することにより学習を進める方法のこと。
- 関数近似法 : 価値関数や方策関数を関数近似する手法のこと。
これらを組み合わせた手法が開発された。
方策勾配法
方策をモデル化して、最適化する方法を指す。
\begin{align}
\theta^{(t+1)} = \theta^{(t)} + \epsilon \nabla J(\theta)
\end{align}
この$J$は方策のよさを示す関数で、定義する必要がある(期待報酬という)。$\theta$は重みパラメータ、$\epsilon$は学習率である。
\begin{align} \nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}}[\nabla_{\theta} \log \pi_{\theta}(a|s) Q^{\pi}(s, a)] \end{align}
Section2:AlphaGo
Google DeepMindによって開発された強化学習によるコンピュータ囲碁プログラムである。2016年3月9日、世界最強の韓国囲碁棋士を4勝1敗で倒したことによりニュースに度々取り挙げられた。
ここでは、以下の2つを取り扱う。
- AlphaGo (Lee)
David Silver「Mastering the game of Go with deep neural networks and tree searchnature」27 January 2016
https://www.nature.com/articles/nature16961 - AlphaGo Zero
David Silver「Mastering the game of Go without human knowledgenature」 18 October 2017
https://www.nature.com/articles/nature24270Section2
AlphaGo Lee
AlphaGo Leeの学習ステップ
AlphaGo Leeの学習は以下のステップで行われる。
- 教師あり学習によるRollOutPolicyとPolicyNetの学習
- 強化学習によるPolicyNetの学習
- 強化学習によるValueNetの学習
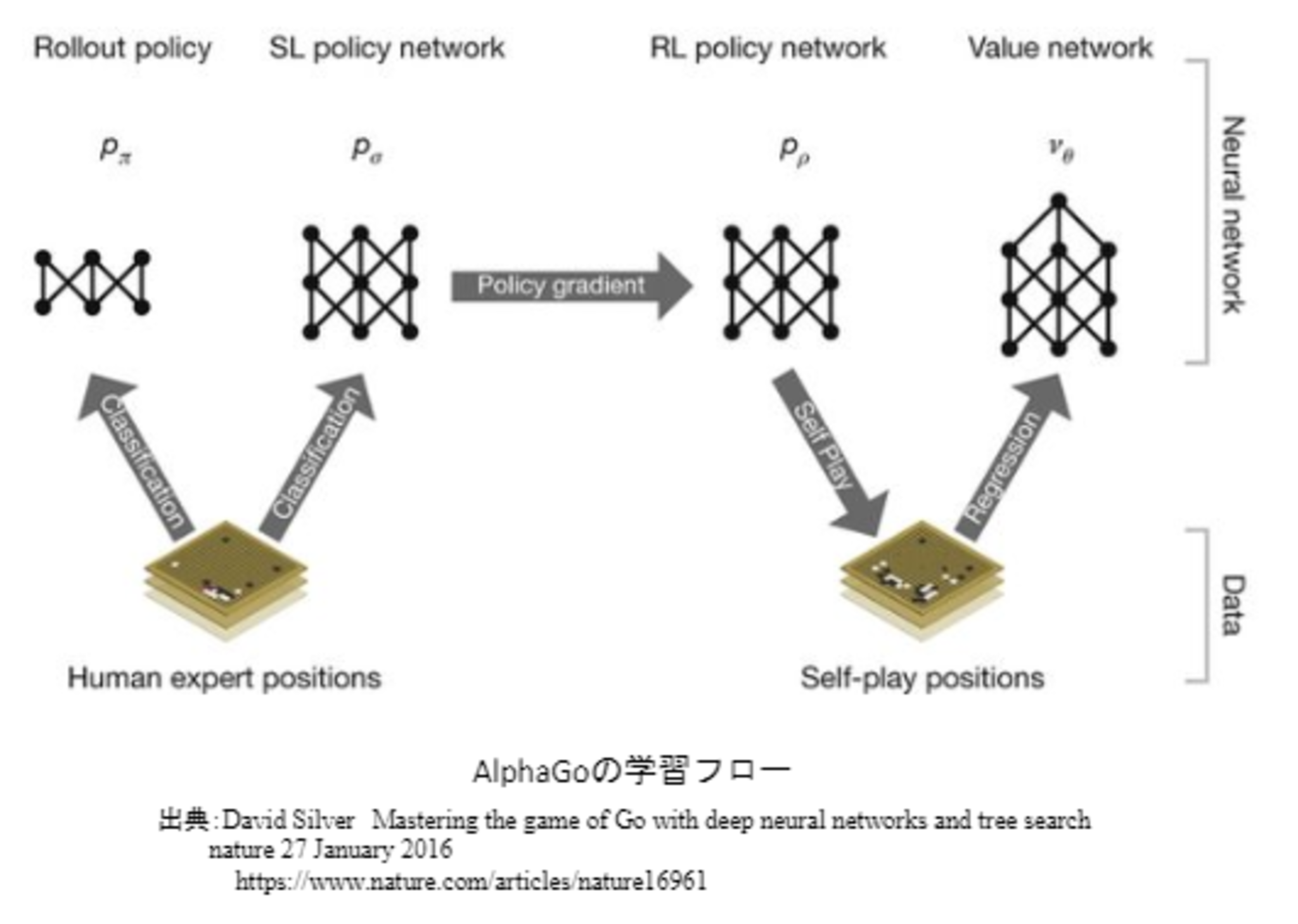
PolicyNet、ValueNetいずれも畳み込みニューラルネットワークである。
RollOutPolicy
- ニューラルネットワークではなく線形の方策関数。
- 探索中に高速に着手確率を出すために使用される。
- 特徴が19×19マス分あり、出力はそのマスの着手予想確率となる。
PolicyNet(教師あり学習)
- KGS Go Server(ネット囲碁対局サイト)の棋譜データから3000万局面分の教師を用意し、教師と同じ着手を予測できるよう学習を行った。
- 教師が着手した手を1とし残りを0とした19×19次元の配列を教師とし、それを分類問題として学習した。
この学習で作成したPolicyNetは57%ほどの精度であった。
PolicyNet(方策関数)の強化学習

- 入力は、19x19マスの盤面特徴(48チャンネル)。
- 盤面特徴は48チャンネル持っている(通常のカラー画像ではRGBの3チャンネル)。
- 出力として、ソフトマックス関数によって19x19の着手予想確率(どこに打つと良いか)が得られる。
ValueNet(価値関数)
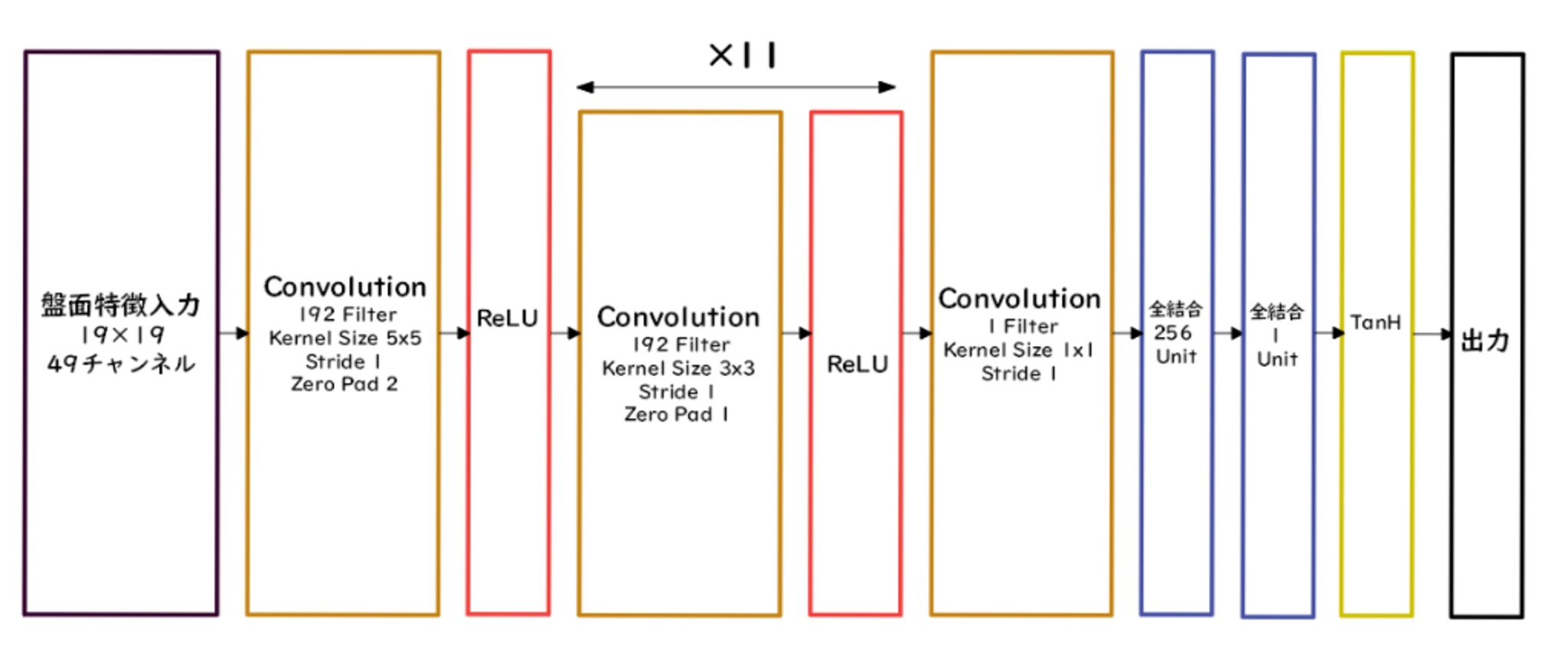
- 入力は19x19マスだけの盤面の特徴。
- 手番というチャンネルが増えているだけでほかはPolicyNetと同じ。
- 出力はtanh関数によって現局面の勝率を-1~1の範囲で得られる。
PolicyNetと違うのは、出力は2次元ではなく1次元(単一値)であるため平滑化(Flatten)をした点。
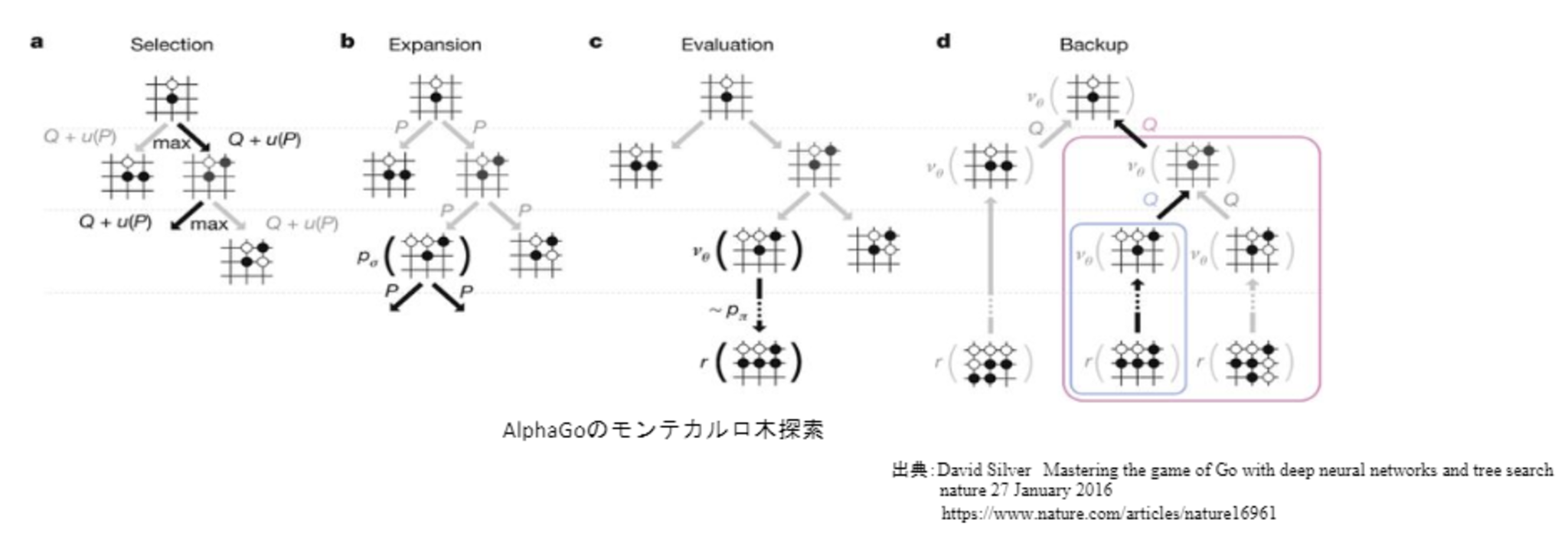
モンテカルロ木探索
強化学習の手法の1つで、価値観数を学習する時に使用する。
コンピュータ囲碁ソフトでは現在もっとも有効とされている探索法であり、理論的にも有効性が認められている。
AlphaGoのモンテカルロ木探索は選択、評価、バックアップ、成長という4つのステップで構成される。
AlphaGo Zero
AlphaGo LeeとAlphaGo Zeroの違い
- AlphaGo Leeは教師あり学習も併用するが、AlphaGo Zeroは強化学習のみで作成した。
- 特徴入力からヒューリスティックな要素を排除し、石の配置のみにした。
- PolicyNetとValueNetを1つのネットワークに統合した。
- Residual Networkを導入した。
- モンテカルロ木探索からRollOutシミュレーションをなくした。
※ヒューリスティックは、一般的な「経験的な」「発見的な」と言う意味ではなく、「探索を効率化するのに有効な」と言う意味で用いる。
PolicyValueNet
PolicyValueNetは、PolicyNetとValueNetが統合されたものである。ただし、方策関数と価値観数の出力をそれぞれ得ることができるようにするために、ニューラルネットワークを途中で枝分かれさせている。
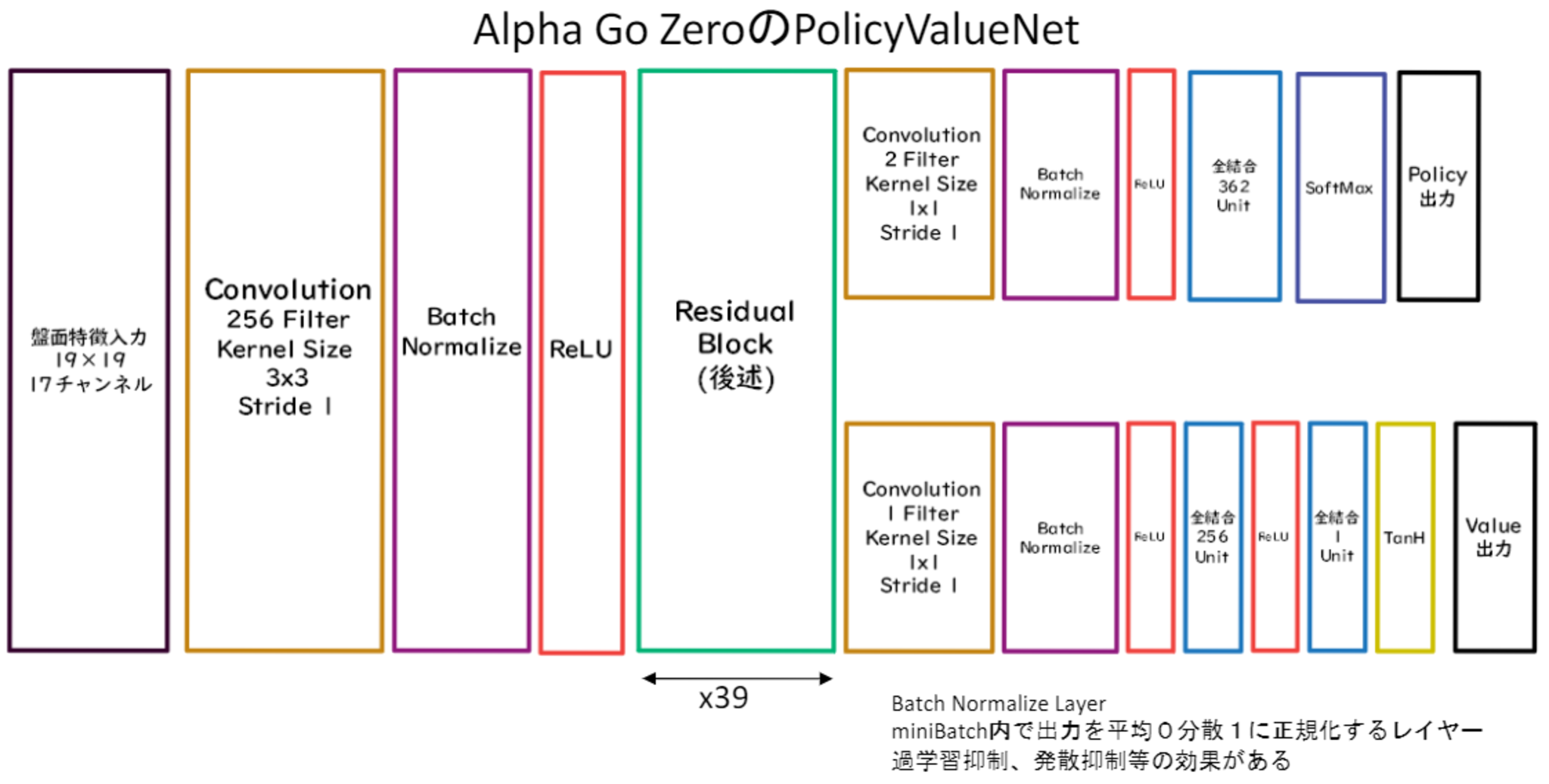
Residula Network
ネットワークにショートカット構造を追加して、勾配の爆発、消失を抑える効果を狙ったもの。
- Residula Networkを使うことにより、100層を超えるネットワークでの安定した学習が可能となった。
- 基本構造はConvolution→BatchNorm→ReLU→Convolution→BatchNorm→Add→ReLUのBlockを1単位にして積み重ねる形となる。
- Resisual Networkを使うことにより層数の違うNetworkのアンサンブル効果が得られているという説もある。
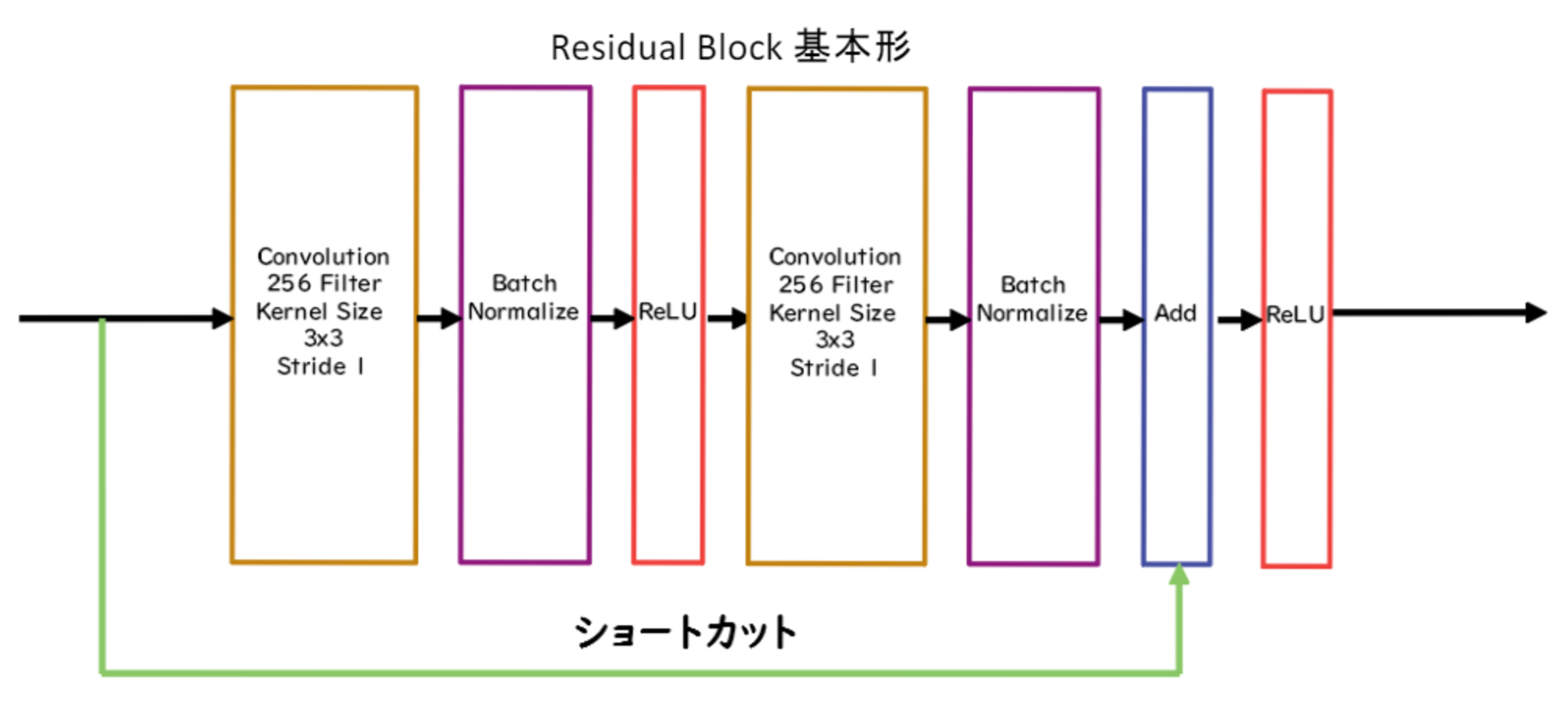
AlphaGo Zeroの学習法
AlphaGoの学習は自己対局による教師データの作成、学習、ネットワークの更新の3ステップで構成される。
- 自己対局による教師データの作成
現状のネットワークでモンテカルロ木探索を用いて自己対局を行う。まず30手までランダムで打ち、そこから探索を行い勝敗を決定する。自己対局中の各局面での着手選択確率分布と勝敗を記録する。教師データの形は(局面、着手選択確率分布、勝敗)が1セットとなる。 - 学習
自己対局で作成した教師データを使い学習を行う。NetworkのPolicy部分の教師に着手選択確率分布を用い、Value部分の教師に勝敗を用いる。損失関数はPolicy部分はCrossEntropy、Value部分は平均二乗誤差。 - ネットワークの更新
学習後、現状のネットワークと学習後のネットワークとで対局テストを行い、学習後のネットワークの勝率が高かった場合、学習後のネットワークを現状のネットワークとする。
Section3:軽量化・高速化技術
はじめに
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。そこで、以下のようなアプローチが考えられる。
- 複数の計算資源(ワーカー)を使用し、並列的なニューラルネットの構成
- データ並列化
- モデル並列化
- 高速化技術
- GPU
- モバイル,IoT 機器との相性向上となるモデルの軽量化
- 量子化
- 蒸留
- プルーニング
データ並列
親モデルを各ワーカーに子モデルとしてコピーする。そして、データを分割し、各ワーカーごとに計算させる方法をデータ並列化という。
データ並列化は各モデルのパラメータの合わせ方で、同期型か非同期型か決まる。
同期型のパラメータ更新の流れ

- 各ワーカーが計算が終わるのを待つ。
- 全ワーカーの勾配が出たところで勾配の平均を計算する。
- 親モデルのパラメータを更新する。
非同期型のパラメータ更新の流れ
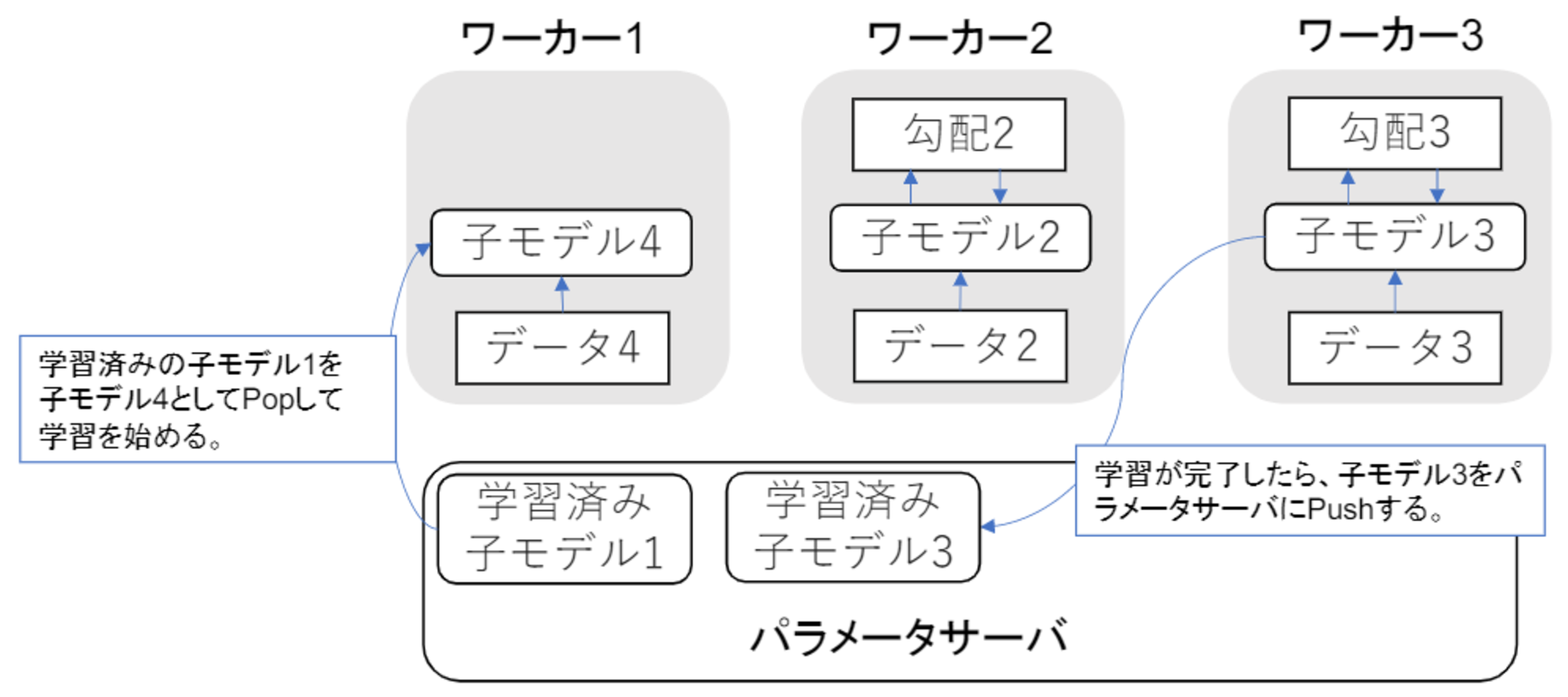
- 各ワーカーはお互いの計算を待たず、各子モデルごとに更新を行う。
- 学習が終わった子モデルはパラメータサーバにPushされる。
- 新たに学習を始める時は、パラメータサーバからPopしたモデルに対して学習していく。
同期型と非同期型の比較
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。(Stale Gradient Problem)
環境によって求められる条件が異なるため、それに応じて使い分けられている。
モデル並列
親モデルを各ワーカーに分割し、それぞれのモデルを学習させ、全てのデータで学習が終わった後で、1つのモデルに復元する方法。
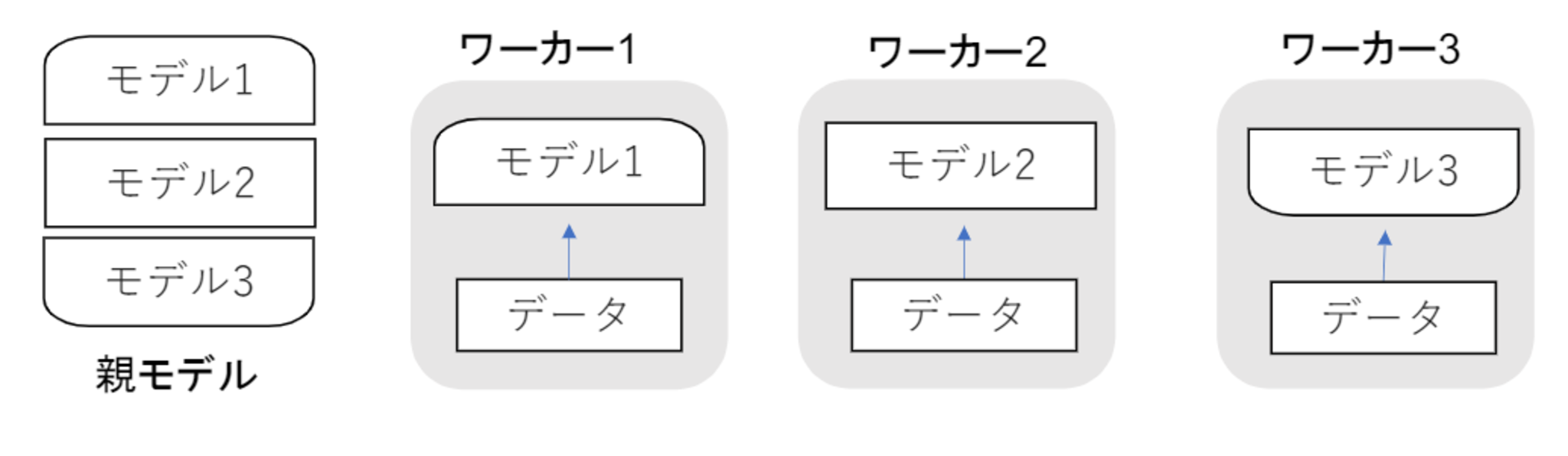
- モデルが大きい時はモデル並列化を、データが大きい時はデータ並列化をすると良い。
- モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
GPU
CPUとGPU
- CPU
- 高性能、少数のコアから成る
- 複雑で連続的な処理が得意
- GPU
- 比較的低性能、多数のコアから成る
- 簡単な並列処理が得意
ニューラルネットの学習は単純な行列演算が多いことから、GPUを活用することにより、高速化が可能である。特に、元々の使用目的であるグラフィック以外の用途で使用されるGPUの総称であるGPGPU (General-purpose on GPU)が活用されている。
GPGPU開発環境
Deep Learningフレームワーク(Tensorflow, Pytorch)内で実装されており、指定するだけで使用可能なので、特段意識する必要はない。
- CUDA
- GPU上で並列コンピューティングを行うためのプラットフォーム。
- NVIDIA社が開発しているGPUのみで使用可能。
- Deep Learning用に提供されているので、使いやすい。
- OpenCL (Deep Learningにおいてあまり使われてない)
- オープンな並列コンピューティングのプラットフォーム。
- NVIDIA社以外の会社(Intel, AMD, ARMなど)のGPUからでも使用可能。
- Deep Learning用の計算に特化しているわけではない。
量子化
ネットワークが大きくなると大量のパラメータが必要なり学習や推論に多くのメモリと演算処理が必要となる。そこで、通常のパラメータの64 bit 浮動小数点を32 bit など下位の精度に落とすことでメモリと演算処理の削減を行う手法を量子化という。
- 利点
- 計算の高速化
- 省メモリ
- 欠点
- 精度の低下
量子化するにあたり、極端に精度が落とすと誤差が大きくなってしまうが、そうでない限りは性能自体に問題は発生しない。そのため、極端に精度が落とさないようにする必要がある。
蒸留
学習済みの精度の高いモデルの知識を軽量なモデルへ継承させる手法を蒸留という。一般的には、軽量化しながら、複雑なモデルに匹敵する精度のモデルを得ることができる。
- Geoffrey Hinton, Oriol Vinyals, Jeff Dean(2015)「Distilling the Knowledge in a Neural Network」
https://arxiv.org/abs/1503.02531
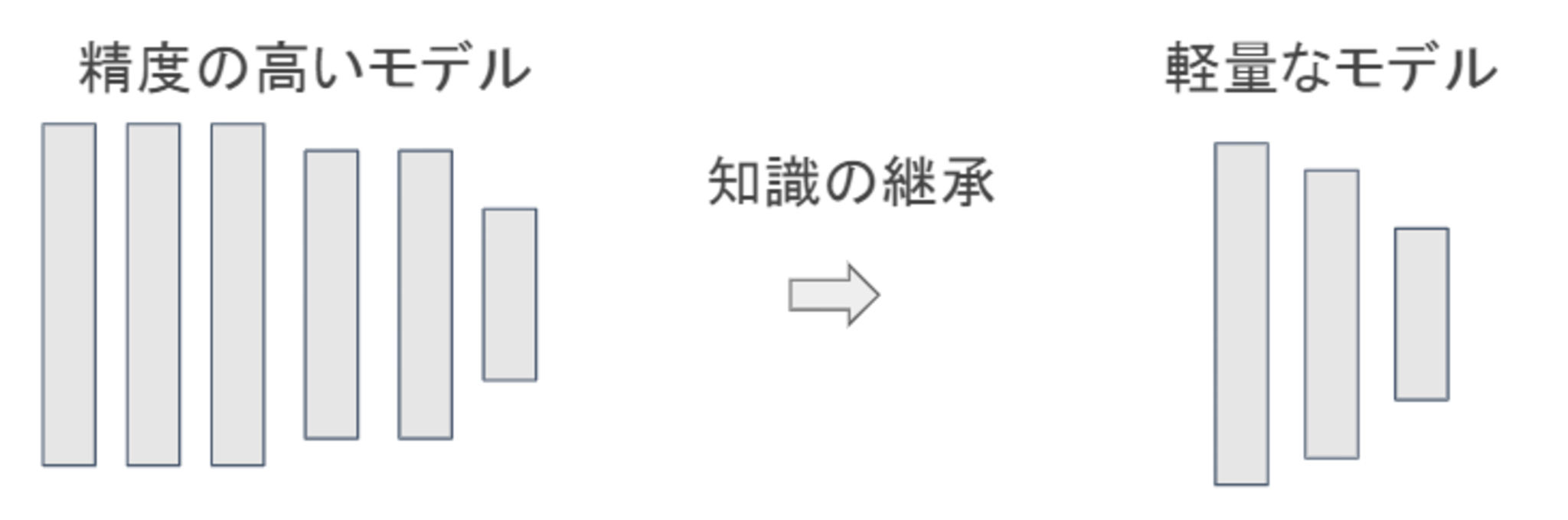
蒸留は教師モデルと生徒モデルの2つから構成される。
- 教師モデル
予測精度の高い、複雑なモデルやアンサンブルされたモデル - 生徒モデル
教師モデルをもとに作られる軽量なモデル

プルーニング
複雑なモデルになればなるほどパラメータが膨大な数となっていくが、全てのニューロンが精度に影響を与えるわけではない。そこで、モデルの精度に寄与が少ないニューロンを削減することで省メモリ化、高速化を実現する方法をプルーニングという。
ニューロンの削減は、重みが閾値以下の場合、ニューロンを削減し、再学習するアプローチで行う。
Section4:応用モデル
MobileNet
Depthwise Separable Convolution(Depthwise ConvolutionとPointwise Convolution)という仕組みを用いて画像認識において軽量化・高速化・高精度化したモデルのこと。
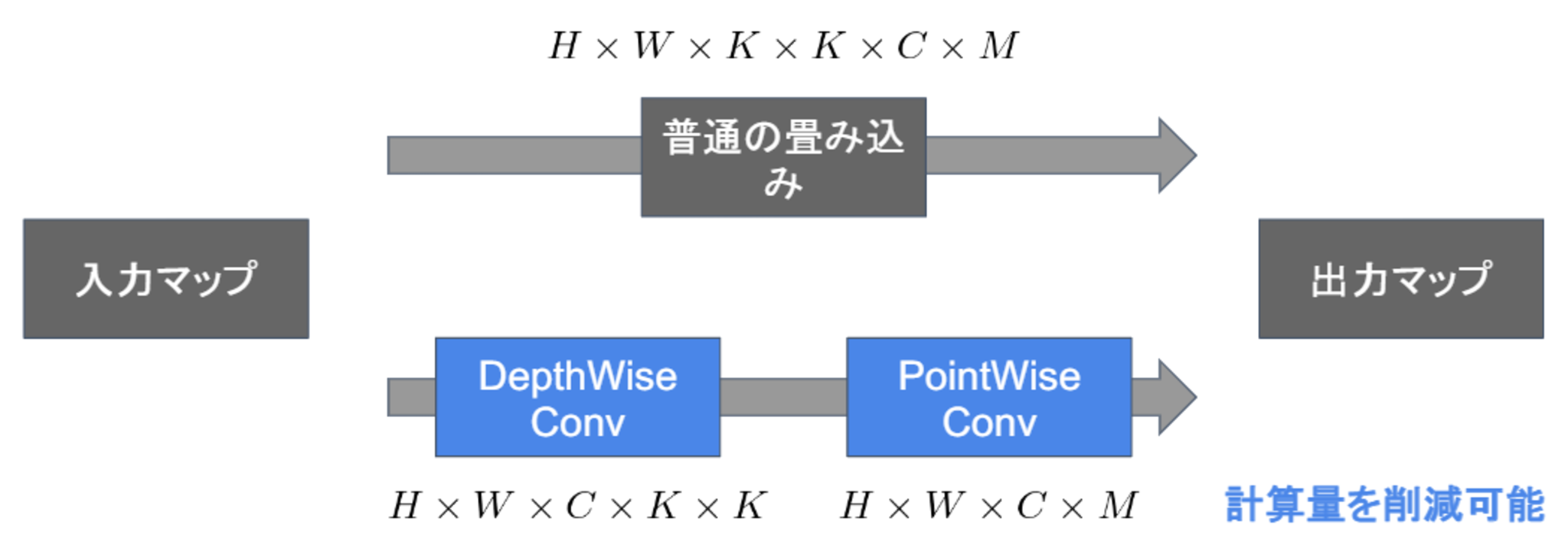
- 通常の畳込みが空間方向とチャネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行う。
- 全体の計算量は、Depthwise Convolutionの計算量+Pointwise Convolutionの計算量となる。
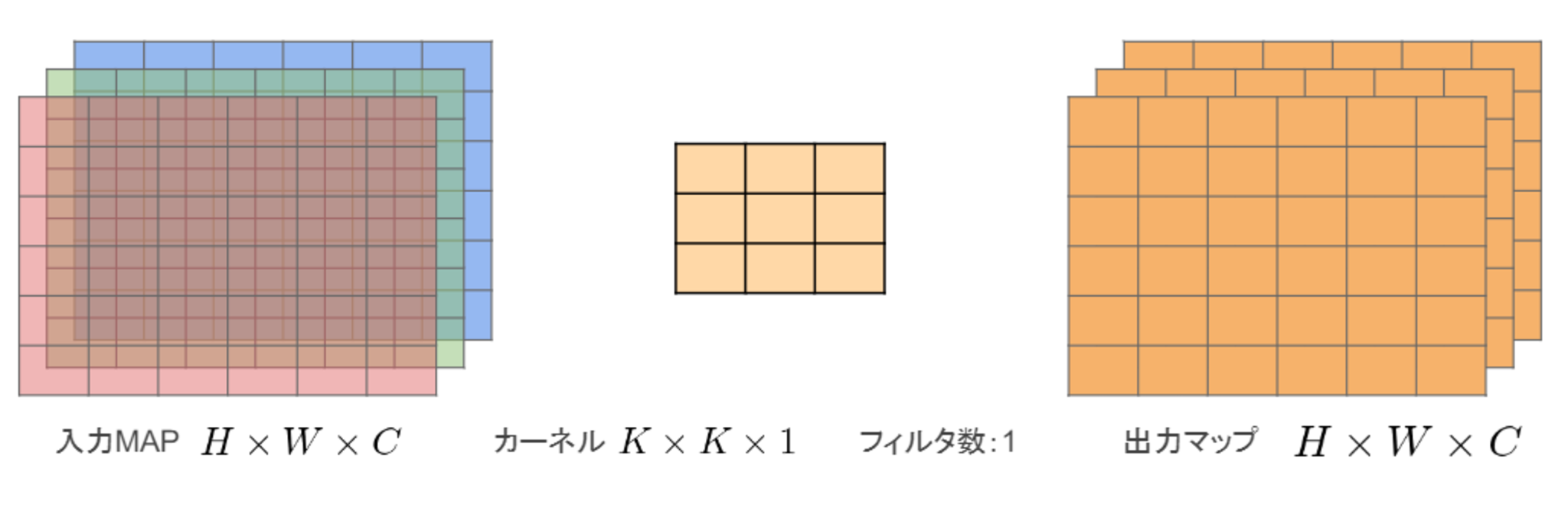
一般的な畳込みの計算量
高さ $H$、幅 $W$、カーネルのサイズ $K$、チャンネル $C$、フィルタ数 $M$とすると以下のようになる。

- 入力特徴マップ(チャネル数):$H \times W \times C$
- 畳込みカーネルのサイズ:$K \times K \times C$
- 出力チャネル数(フィルタ数):$M$
- ストライド1でパディングありの場合の畳み込み計算量
- ある1点の計算量:$K \times K \times C \times M$
- 全出力マップの計算量:$H \times W \times K \times K \times C \times M$
Depthwise Convolution
- 入力マップのチャネルごとに畳み込みを行う。
- 出力マップをそれらと結合する(入力マップのチャネル数と同じになる)。
- フィルタは1つだけと固定させる。
- 入力マップ:$H \times W \times C$
- カーネル:$K \times K \times 1$
- 出力マップ:$H \times W \times C$
- 全出力マップの計算量:$H \times W \times K \times K \times C$
Pointwise Convolution
- $1\times 1$ convとも呼ばれる(正確には$1\times 1\times C$)
- 入力マップのポイントごとに畳み込みを実施
- 出力マップ(チャネル数)はフィルタ数分だけ作成可能(任意のサイズが指定可能)

- 入力マップ:$H \times W \times C$
- カーネル:$1 \times 1 \times C$
- 出力マップ:$H \times W \times C$
- 全出力マップの計算量:$H \times W \times C \times M$
DenseNet
Dense Blockという仕組みを用いた画像認識モデルのこと。
DenseNetの全体像

Dense Block
出力層に前の層の入力を足しあわせる。すなわち、層間の情報の伝達を最大にするために全ての同特徴量サイズの層を結合する。
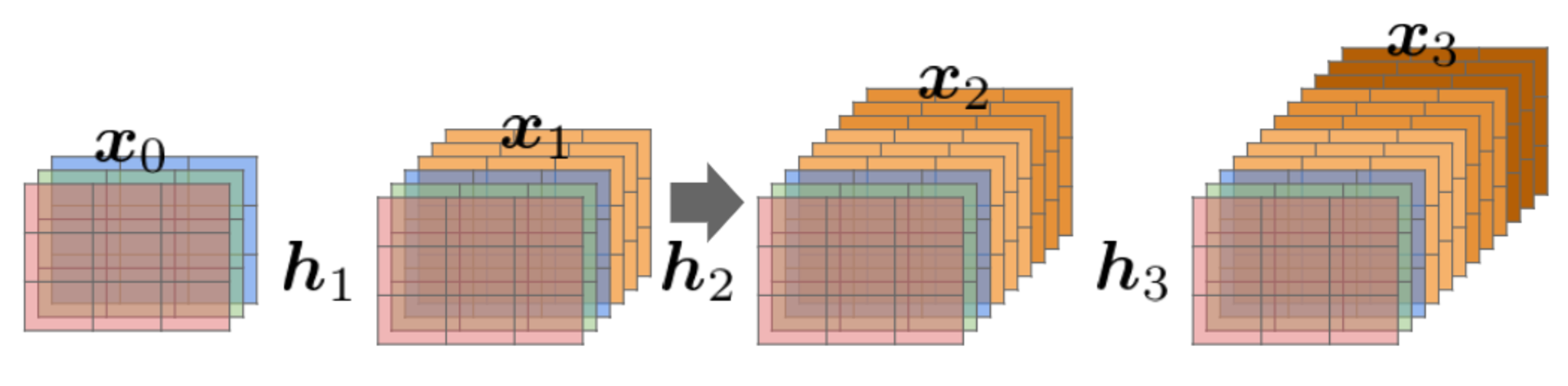
DenseNet内で使用されるDenseBlockと呼ばれるモジュールでは成⻑率$k$と呼ばれるハイパーパラメータが存在する。
DenseBlock内の各ブロック毎に$k$個ずつ特徴マップのチャネル数が増加していく。
- $K$をネットワークのgrowth rate(成長率)という。
- $K$が大きくなるほどネットワークが大きくなるため、小さな整数に設定するのがよい。
Transition Layer(変換レイヤー)
Dense Blockで追加されたチャネルサイズを、ダウンサンプリングして削減し、元に戻す層がTransition Layerである。
Normalization
Batch Normalization
- レイヤー間を流れるデータの分布を、ミニバッチ単位で平均が0、分散が1になるように正規化
- H x W x CのsampleがN個あった場合に、N個の同一チャネルが正規化の単位
- RGBの3チャネルのsampleがN個の場合は、それぞれのチャンネルの平均と分散を求め正規化を実施(図の⻘い部分に対応)。チャンネルごとに正規化された特徴マップを出力。
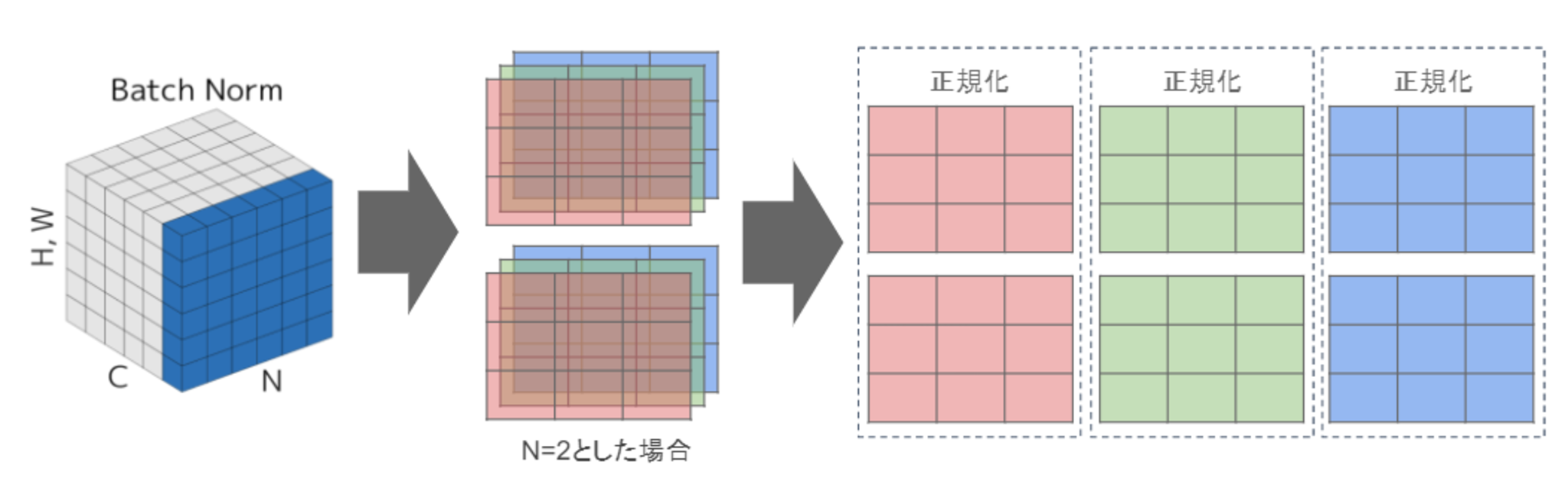
- ニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制など効果がある。
- ミニバッチのサイズを大きく取れない場合には、効果が薄くなり、学習が収束しないことがある。
- 代わりにLayer Normalizationなどが使われることが多い。
Layer Normalization
- N個のsampleのうち一つに注目。H x W x Cの全てのpixelが正規化の単位。
- RGBの3チャネルのsampleがN個の場合は、あるsampleを取り出し、全てのチャネルの平均と分散を求め正規化を実施(図の⻘い部分に対応)。
- 特徴マップごとに正規化された特徴マップを出力
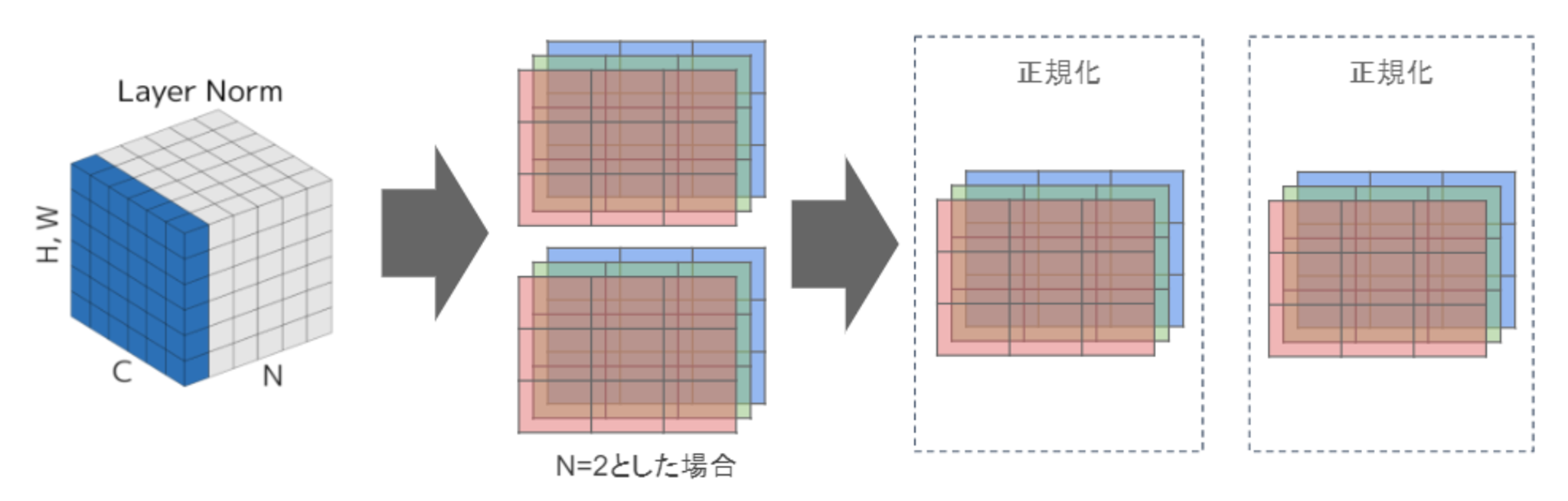
- ミニバッチの数に依存しないので、上記の問題を解消できていると考えられる。
- 入力データや重み行列に対して、以下の操作を施しても、出力が変わらないことが知られている。
- 入力データのスケールに関してロバスト(頑健)である。
- 重み行列のスケールやシフトに関してロバスト(頑健)である。
Instance Normalization
- 各データ1つの各チャンネルに対して正規化する。
- Batch Normalizationのバッチサイズが1の場合と等価である。

- コントラストの正規化に寄与している。
- 画像のスタイル転送やテクスチャ合成タスク等で使用される。
Wavenet
WaveNetは、時系列データに対して、畳み込みニューラルネットワーク(Dilated Convolution)を用いたモデルであり、Pixel CNN(高解像度の画像を精密に生成できる手法)を音声に応用したもの。
- Dilated Causal Convolution
- 層が深くなるにつれて畳み込むリンクを離す。
- 受容野を簡単に増やすことができるという利点がある。

通常の畳込みと同じ層の深さでもより幅広い時系列を扱うことができる。
■確認テスト
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNetの大きな貢献の1つである。提案された新しいConvolution型アーキテクチャは(あ)と呼ばれ、結合確率を効率的に学習できるようになっている。(あ)を用いた際の大きな利点は、単純なConvolution Layerと比べて(い)ことである。
〇解答
(あ) : Dilated Causal Convolution
(い) : パラメータ数に対する受容野が広い。
Section5:Transformer
Seq2seq
Seq2seqとは、系列(Sequence)を入力として、系列を出力するもの。
- Encoder-Decoderモデルとも呼ばれる
- 入力系列がEncode(内部状態に変換)され、内部状態からDecode(系列に変換)する
- 実応用上も、入力・出力共に系列情報なものは多い
- 翻訳 (英語→日本語)
- 音声認識 (波形→テキスト)
- チャットボット (テキスト→テキスト)
具体的には、RNN x 言語モデルである。
- RNNは系列情報を内部状態に変換することができる。
- 文章の各単語が現れる際の同時確率は、事後確率で分解できる。
- したがって、事後確率を求めることがRNNの目標になる。
- 言語モデルを再現するようにRNNの重みが学習されていれば、ある時点の次の単語を予測することができる。
- 先頭単語を与えれば文章を生成することも可能である。
EncoderからDecoderに渡される内部状態ベクトルが鍵である。

Decoder側の構造は言語モデルRNNとほぼ同じだが 隠れ状態の初期値にEncder側の内部状態を受け取る。
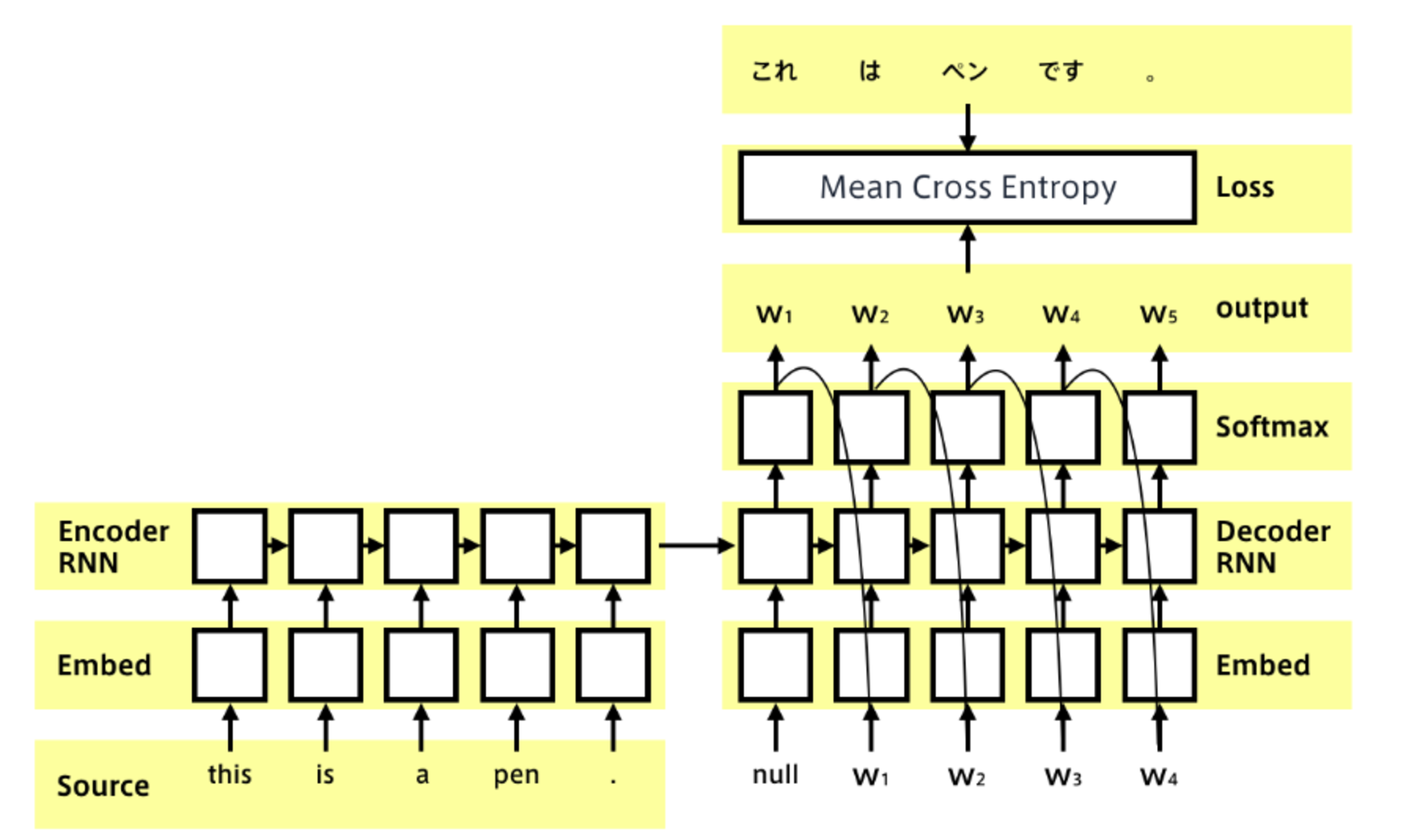
Decoderのoutput側に正解を当てれば教師あり学習がEnd2endで行える。
■確認テスト

〇解答
時刻$t$の出力を時刻$t+1$の入力とすることができるが、この方法でDecoderを学習させると、連鎖的に誤差が大きくなり、学習が不安定になったり、収束が遅くなったりする。
■確認テスト
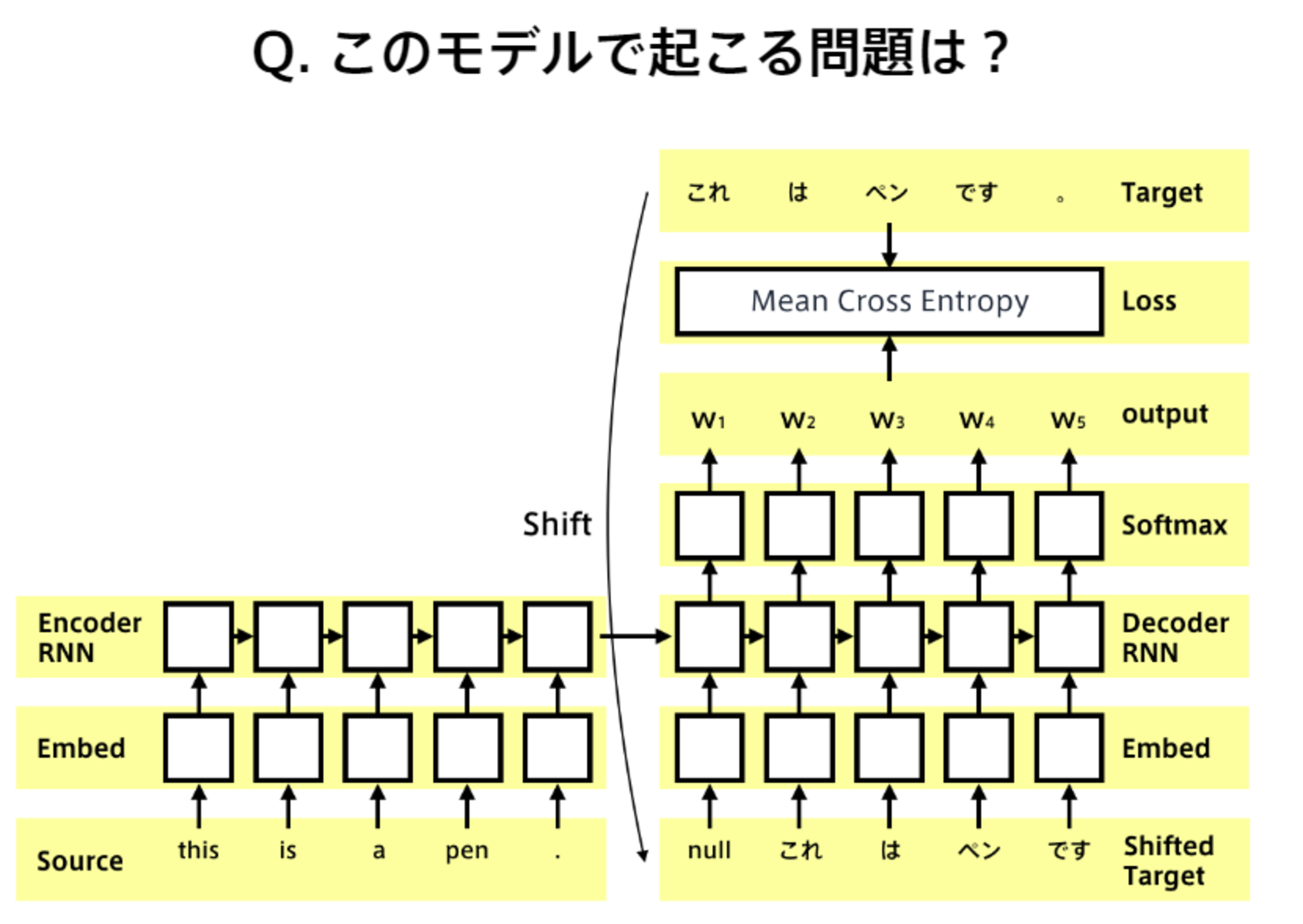
〇解答
訓練時には問題ないように見えても、学習時と本番の時では環境が異なるため、バリデーションで収束しない。
Transformer
Attention (注意機構)
翻訳先の各単語を選択する際に、翻訳元の文中の各単語の隠れ状態を利用する辞書オブジェクトの機能をもつもの。query(検索クエリ)に一致するkeyを索引し、対応するvalueを取り出す操作であると見做すことができる。
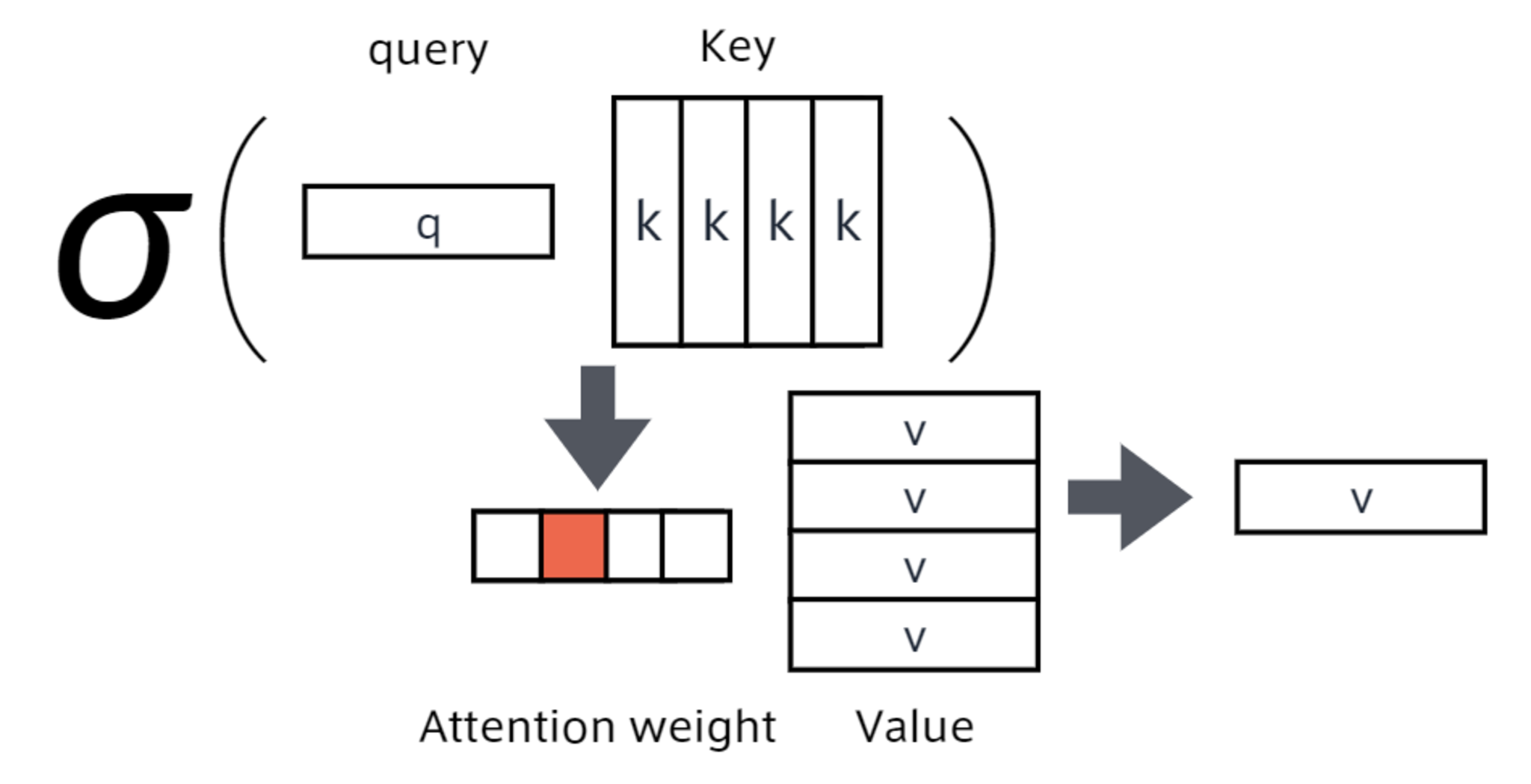
Transformer
- アメリカのHugging Face社が提供
- 分類、情報抽出、要約、翻訳、テキスト生成などのための事前学習モデルを100以上の言語で提供されている。
- 最先端の自然言語処理技術が簡単に使用可能されている。
- RNNを使わない
- 必要なのはAttentionだけ
- 当時のSOTAをはるかに少ない計算量で実現
- 英仏 (3600万文) の学習を8GPUで3.5日で完了
Decoderは次の単語を予測するが、RNNを使っていないため系列全ての単語が一度に与えられる。
そのため、未来の単語が見えないようにするため、Decoderでは未来の単語をマスクする。
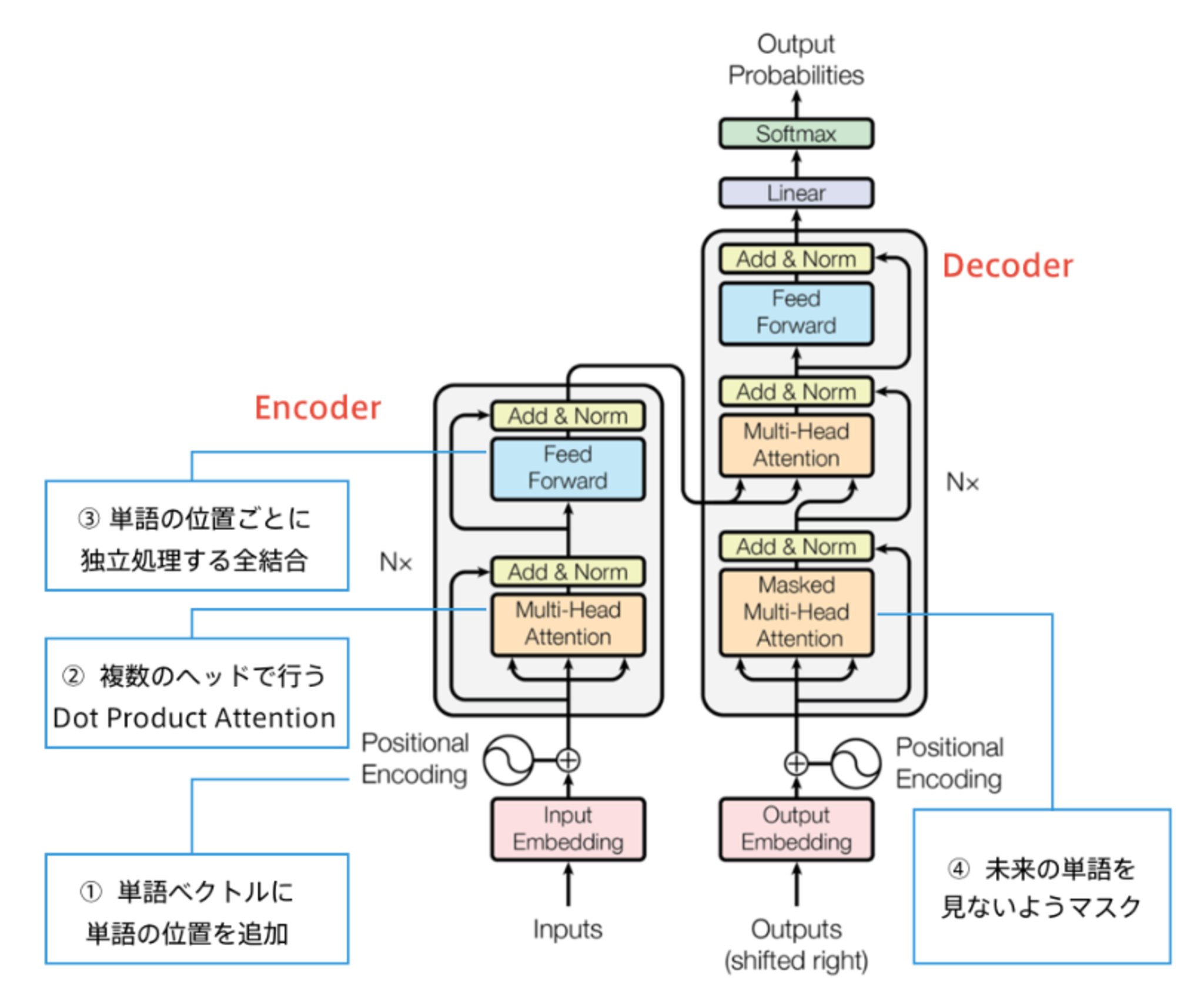
Section6:物体検知とSemantic Segmentation
物体認識のタスクの概要
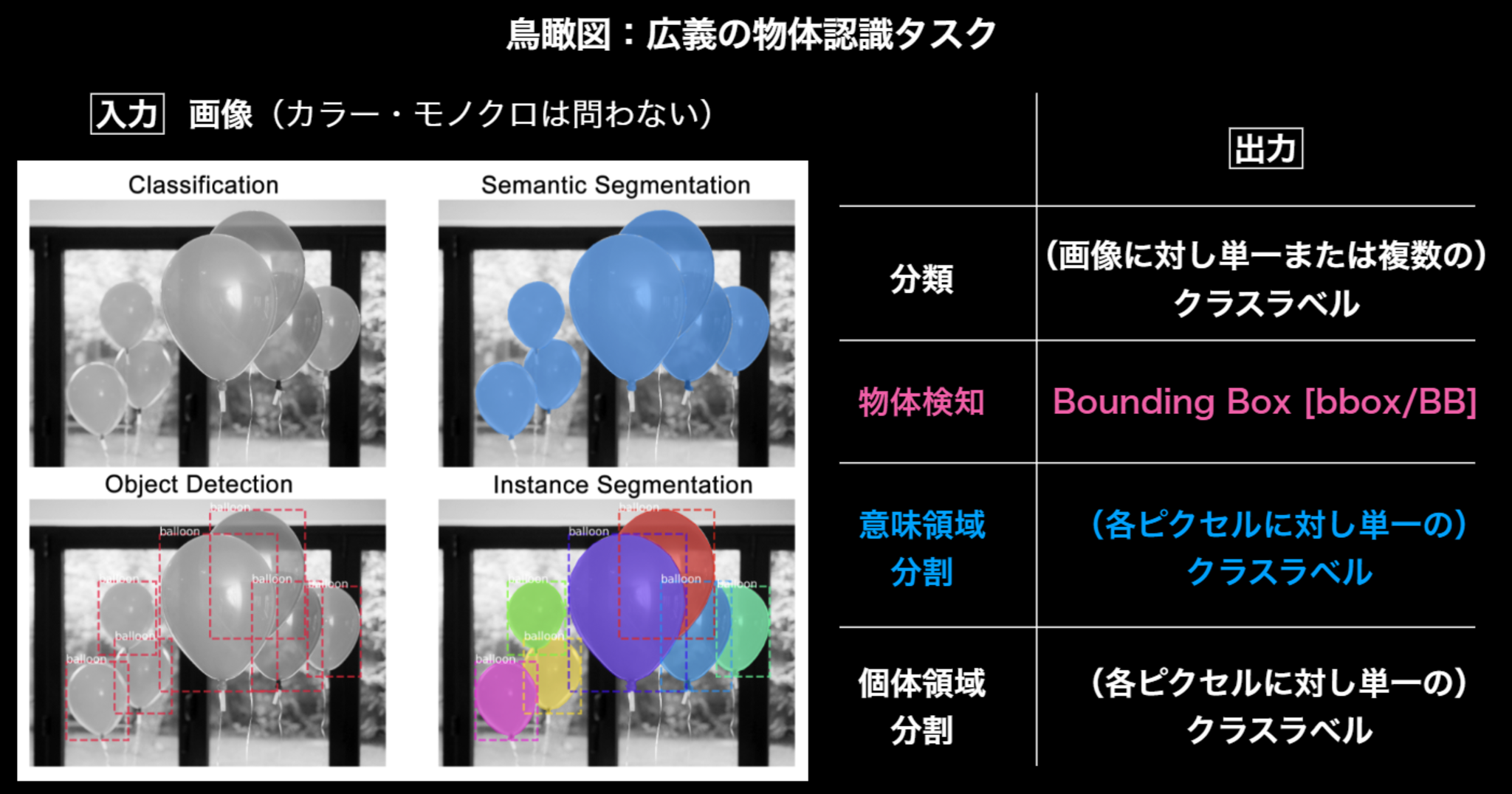 鳥瞰図
鳥瞰図
データセット
さまざまなアルゴリズムが開発されるにつれ、精度を見るために、
共通として制度評価に用いられるデータセットが必要になる。
代表的データセット
物体検知コンペティションで用いられたデータセットは、以下の通り。
| コンペ | クラス | Train+Val | Box÷画像 | 画像サイズ |
|---|---|---|---|---|
| VOC12 | 20 | 11,540 | 2.4 | 470×380 |
| ILSVRC17 | 200 | 476,668 | 1.1 | 500×400 |
| MS COCO18 | 80 | 123,287 | 7.3 | 640×480 |
| OICOD18 | 500 | 1,743,042 | 7.0 | 一様ではない |
ILSVRC17以外は、Instance Annotationが与えられている(物体個々のラベルがなされている)。
- VOC:Visual Object Classes
- 主要貢献者が2012年に他界ためコンペは終了
- ILSVRC:ImageNet Scale Visual Recognition Challenge
- コンペは2017年に終了(後継のコンペはOpen Images Challenge)
- ImageNet(21,841クラス/1400万枚以上)のサブセット
- MS COCO Object Detection Challenge
- COCO = Common Object in Context
- 物体位置推定に対する新たな評価指標を提案(後述)
- Open Images Challenge Object Detection
- ILSVRCやMS COCOとは異なるannotation process
- Open Images V4(6000クラス以上/900万枚以上)のサブセット
「Box÷画像」の意味
一画像当たりのBox数の平均数。
なぜ重要なのか?
- Box÷画像が少ない:ほぼアイコンのような画像(画像の中心に物体が1つ)⇒日常感がない。自動運転などにはいかせない。
(アイコンのような写りにはよい。) - Box÷画像が多い:1個1個の物体が小さい。⇒ 日常生活の画像に近くなる。
代表的データセットのポジショニングマップ
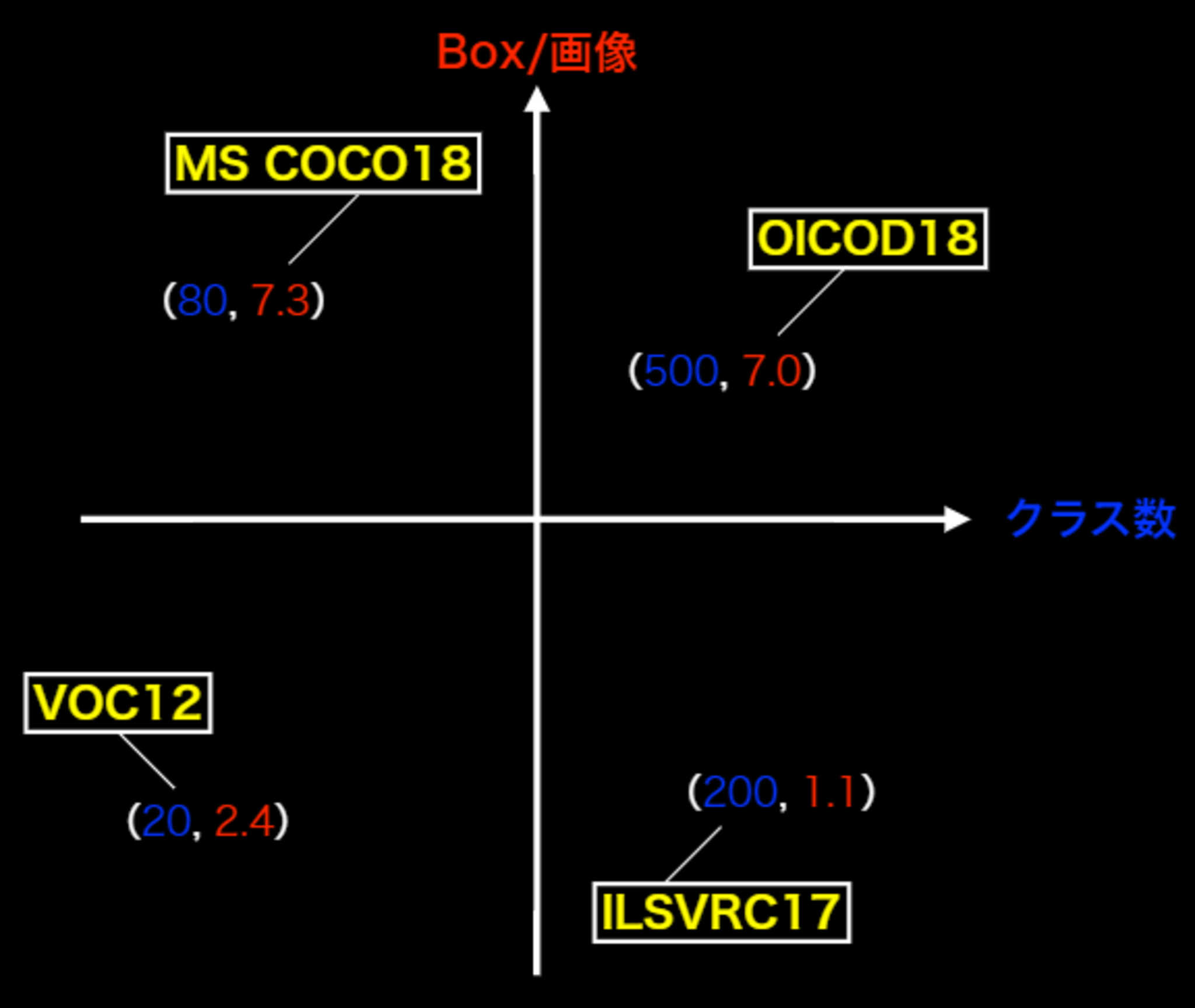
- 目的に応じた選択をする。
- 画像の物体がアイコン的か?それとも複数か?
- クラス数が多いことは嬉しいか?
- 同じものなのに違う名づけがされていて、クラスが違うかも。
評価指標
分類問題の評価指標
混合行列の概要は以下の通り。
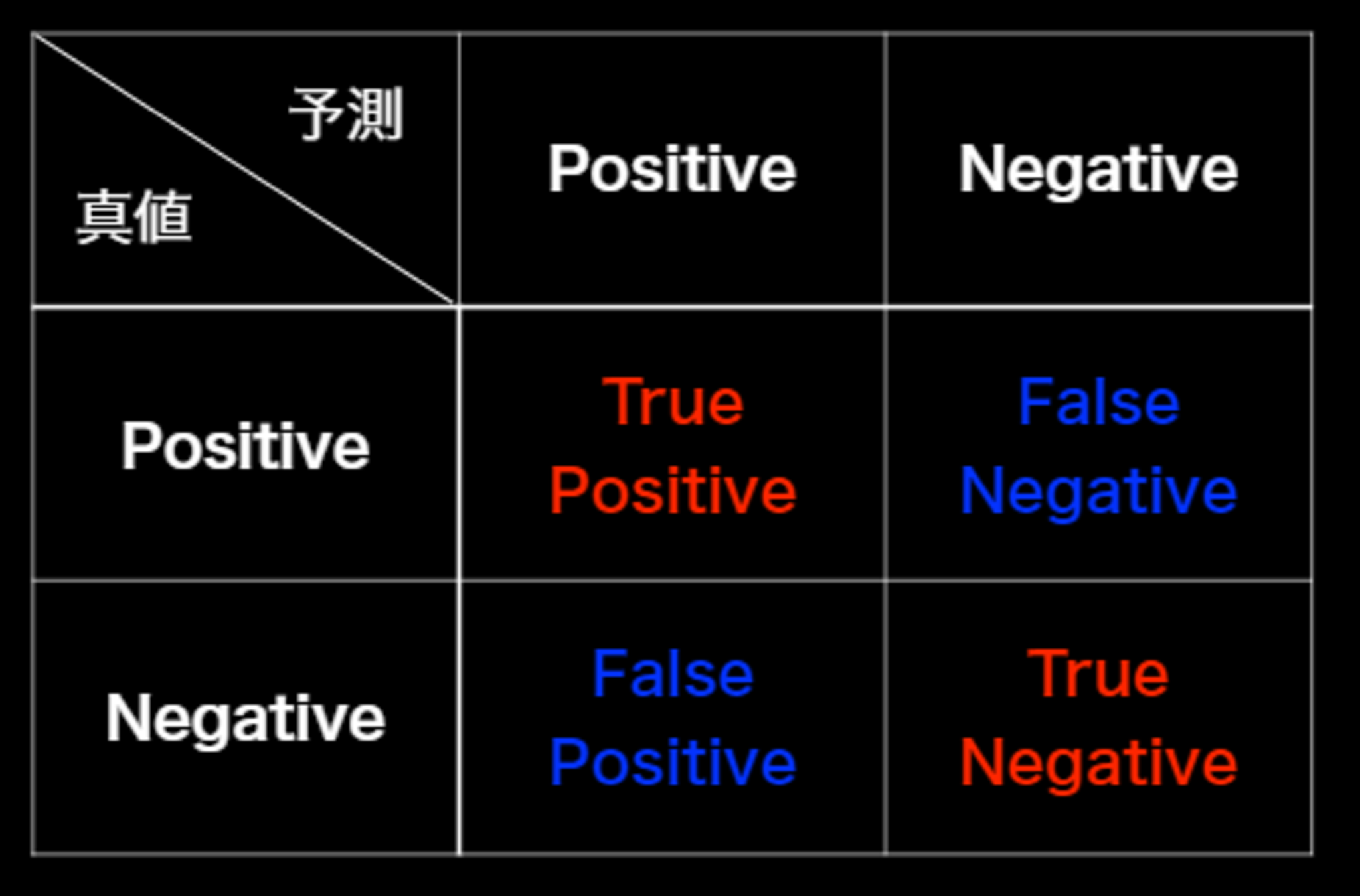 混合行列
混合行列
- True Positive(TP, 真陽性) : 正しくPositiveと判別した数
- False Positive(FP, 偽陽性) : 間違えてPositiveと判別した数
- True Negative(TN, 真陰性) : 正しくNegativeと判別した数
- False Negative(FN, 偽陰性) : 間違えてNegativeと判別した数
主な指標は以下の通り。
- 正解率(Accuracy):全データ($TP+FN+FP+TN$)のうち、正しく判別した($TP+TN$)確率
$\displaystyle \frac{TP+TN}{TP+FN+FP+TN}$ - 再現率(Recall):Positiveなデータ($TP+FN$)から、Positiveと予想($TP$)できる確率
$\displaystyle \frac{TP}{TP+FN}$ - 適合率(Precision):モデルがPositiveと予想したデータ$TP+FP$から、Positiveと予想($TP$)できる確率
$\displaystyle \frac{TP}{TP+FP}$ - F値(F score):再現率(Recall)と適合率(Precision)の調和平均
$\displaystyle \frac{2}{1/Recall+1/Precision}=\frac{2 \times Precision \times Recall}{Recall+Precision}$
IOU(Intersection Over Union)
物体検出においてはクラスラベルだけでなく, 物体位置の予測精度も評価したいことが動機となっている。
bounding boxを用いて、IoUを定義する。
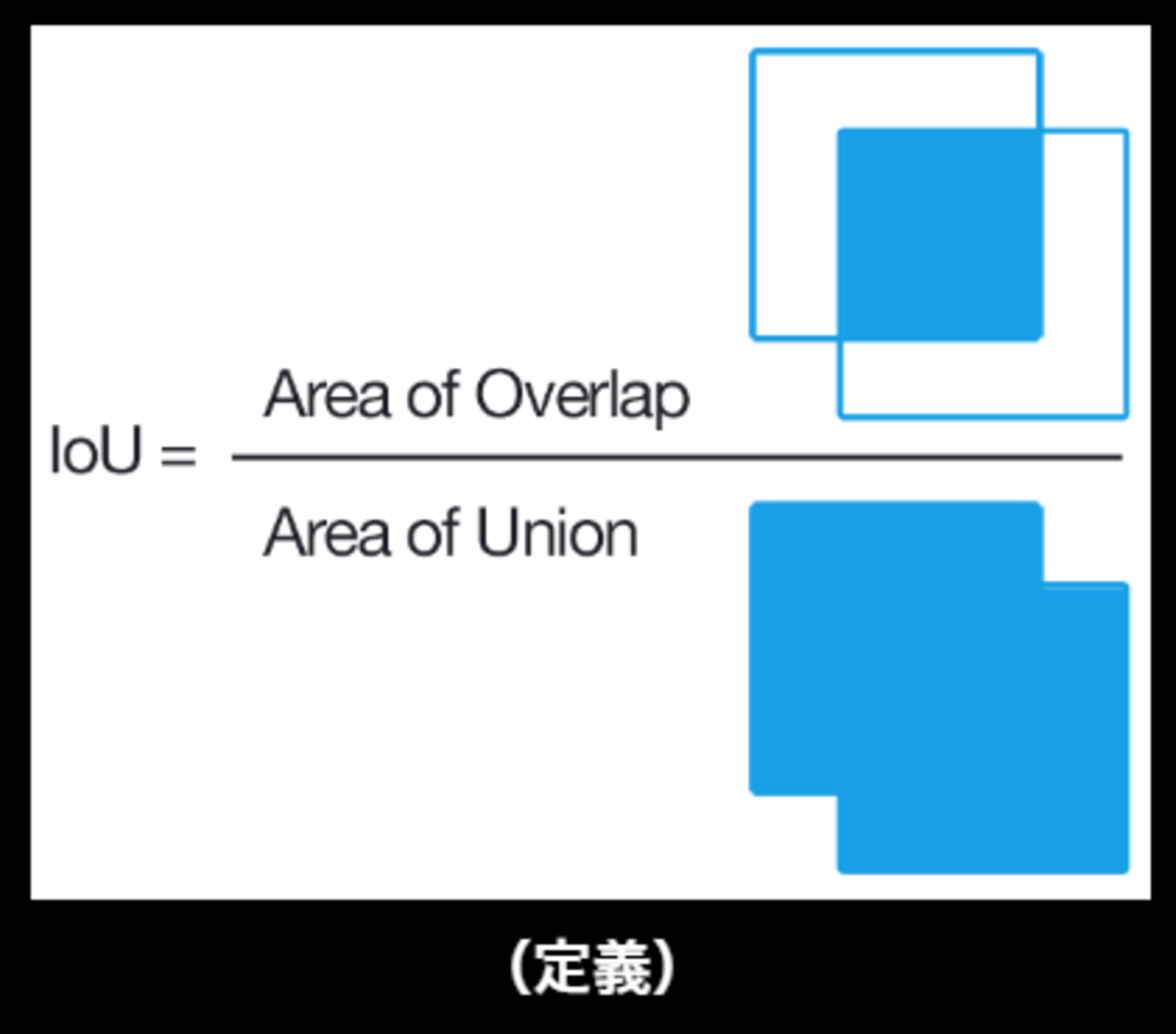 IoU
IoU
\begin{align} IoU = \frac{TP}{TP+FP+FN} \end{align}
IOUの直感的理解は難しく、IOUにはよくある誤りがある。
■具体例

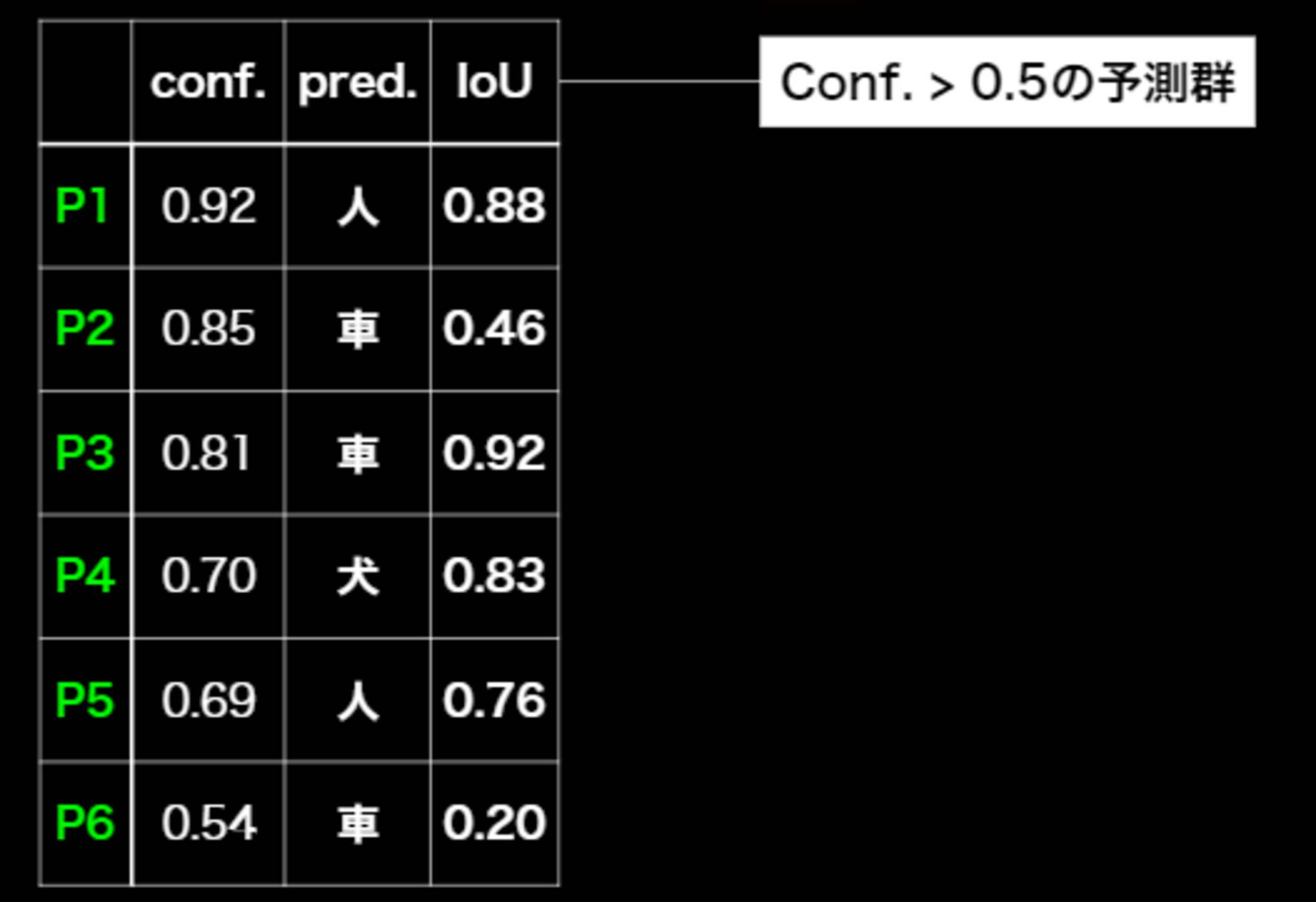
以下のプロセスで計算される。
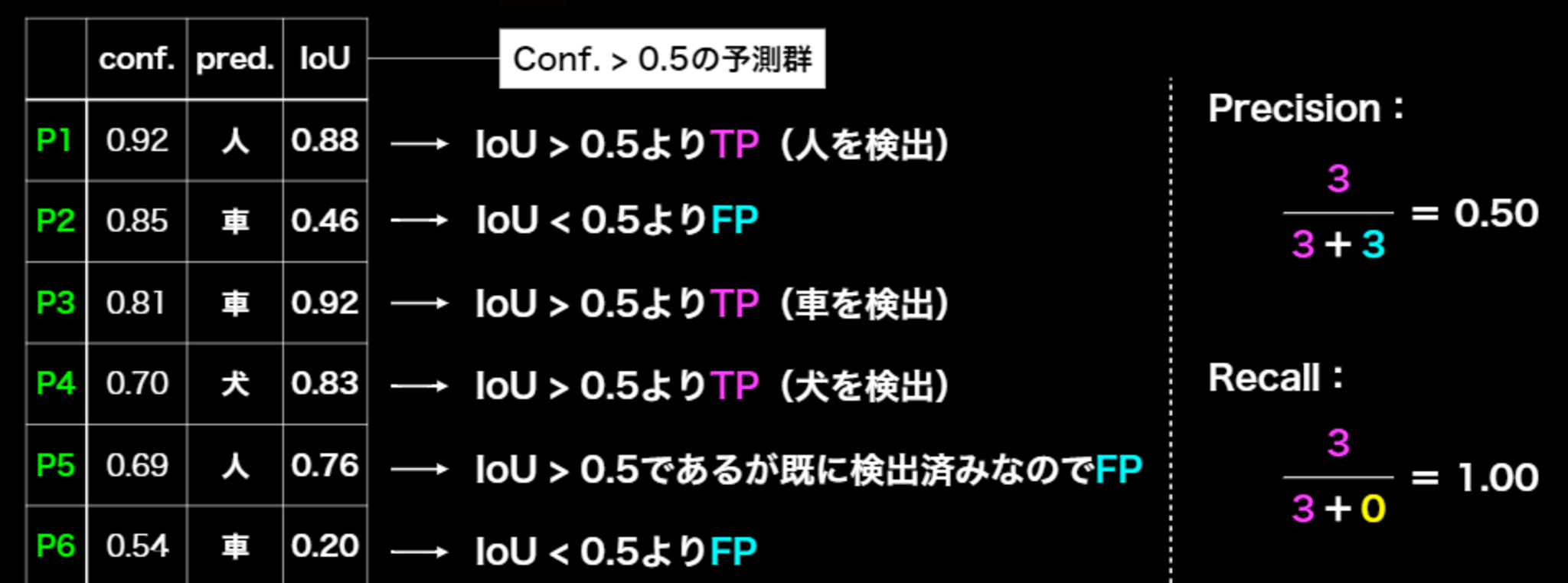

AP(Average Precision)
confの閾値を$\beta$とするとき、Recall$=$R($\beta$)、Precision$=$ P($\beta$)
\begin{align}
AP=\int_0^1 P(R) dR
\end{align}
mAP(mean Average Precision)
AP(Average Precision)の平均
\begin{align}
mAP=\frac{1}{C} \sum_{i=1}^C AP_i
\end{align}
mAPcoco(mean Average Precision coco)
- MS COCOで導入された新たな指標
- IoUの閾値は0.5 で固定するのではなく、IoUの閾値を0.5~0.95まで0.05刻みでのmAPを計算し算術平均をとった値を用いる
\begin{align} mAP_{COCO}=\frac{mAP_{0.5}+mAP_{0.55}+mAP_{0.6}+mAP_{0.65}+\cdots +mAP_{0.95}}{10} \end{align}
位置を厳しくしながら評価していったもの。
FPS(Flames per Second)
応用上の要請から, 検出精度に加え検出速度も問題となる(リアルタイム検知も特に大事)ことから生まれた、物体検出の検出速度に対する評価指標。
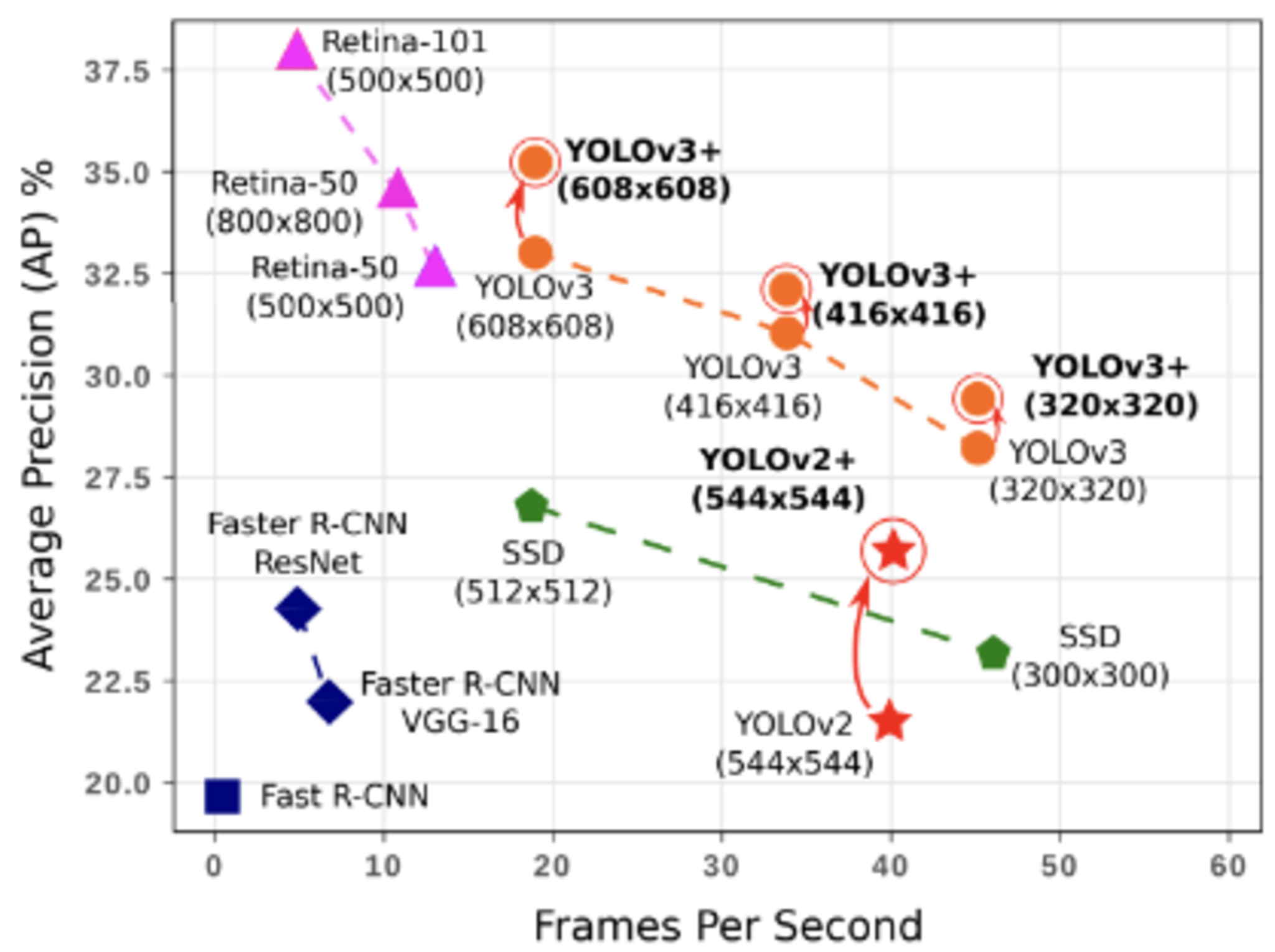 FPS
FPS
- 右に行けば行くほど良い。
- 縦軸はAPで用いられることが多い。
物体検知の大枠
- 2段階検出器(Two-stage detector)
候補領域の検出とクラス推定を別々に行う。- 1段階検出器と比べて精度が高い傾向
- 1段階検出器と比べて計算量が大きいため予測も遅い傾向
⇒ 別々に推定を行うので時間がかかる。(リアルタイム検出には向かない)
- 1段階検出器(One-stage detector)
候補領域の検出とクラス推定を同時に行う。- 2段階検出器と比べて精度が低い傾向
- 2段階検出器と比べて計算量が小さく予測も早い傾向
⇒ リアルタイム検出には、2段階検出器より向いている。
SSD(Single Shot Detector)
1段階検出器のモデルの1つで、VGG16をベースとしたアーキテクチャ。
- 初めにデフォルトボックスを用意する(一般的には複数用意される。)
- デフォルトボックスを変形して、プレディクテッド・バウンディングボックスとする。
Non-Maximum Suppression
RCNNでもすでに用いられており、SSDで初めて出てきた概念ではない。
- デフォルトボックスを複数用意したことで1つの物体に対して複数のバウンディングボックスが予測される問題
⇒ IoUを計算する。閾値で複数の予測があるのであれば最もconfidenceが高いものだけを残す
Hard Negative Mining
- VOCの21クラス目である背景のようなクラスがある場合、背景とそれ以外の物体で検出数が不均衡となる。
⇒ 最大でもposittive:negative=1:3となるように制約をかける
損失関数
\begin{align} L(x, c, l, g) = \frac{1}{N} (L_{conf}(x,c)+\alpha L_{loc}(x,l,g)) \end{align}
- $L_{conf}$:confidenceに対する損失
- $L_{loc}$:検出位置に対する損失
Semantic Segmentation
covolutionやpooling をかますことにより入力画像の解像度がどんどん落ちる。これは、解像度が落ちることがSemantic Segmentationにとっては問題
Semantic Segmentationは、入力サイズと同じサイズの画像があり各ピクセルに対してクラス分類が行われるのが基本
解像度が落ちている状態、つまり入力時の画像の解像度とは違う
⇒ どうやって入力時の画像のサイズに戻すのか?
⇒ covolutionやpooling で落ちた解像度を元に戻す(Up-sampling)
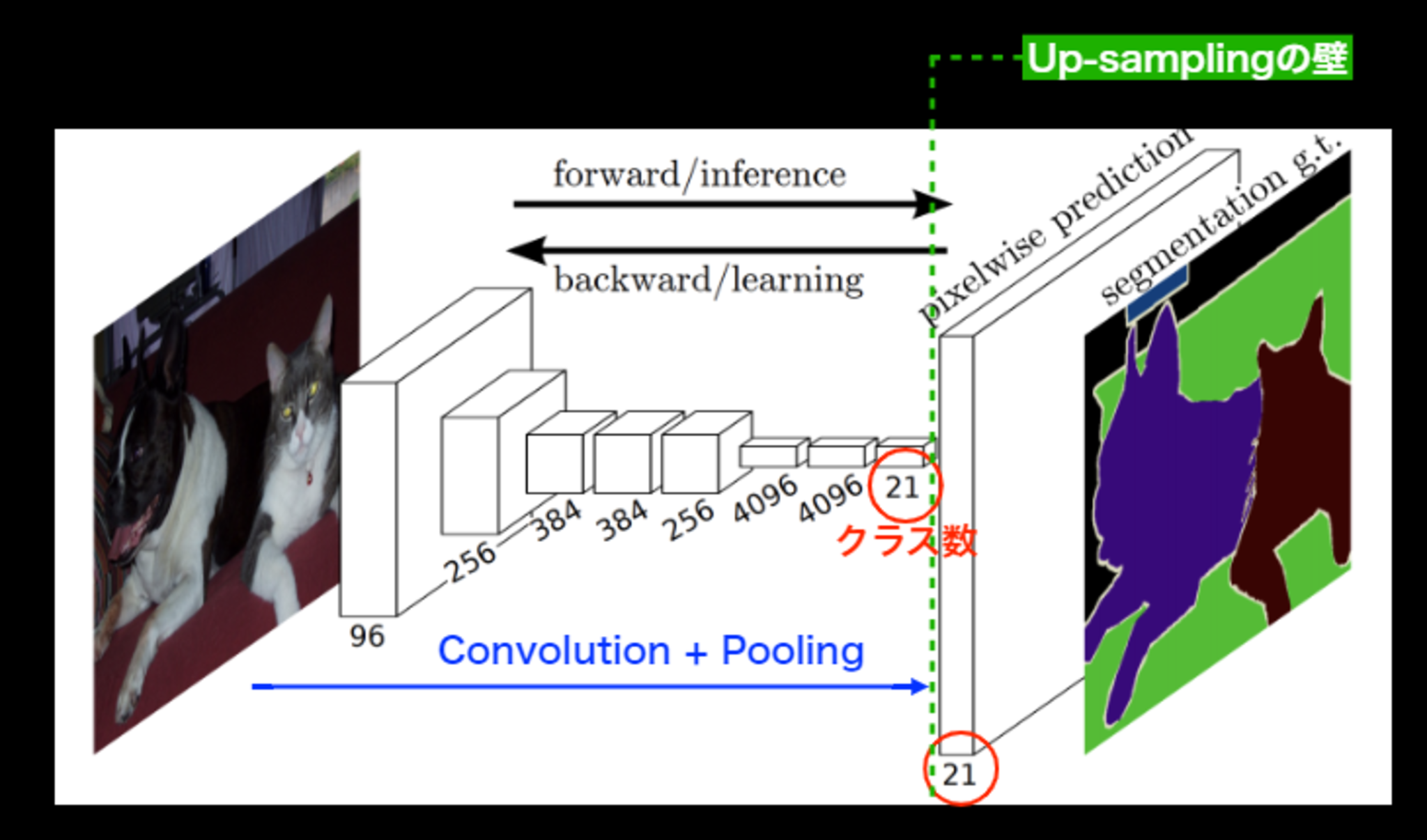 概要図
概要図
Up-sampling
covolutionやpooling で落ちる解像度を元に戻すことをUp-samplingという。
Up-samplingの壁、Up-samplingを如何に行うかが肝となる。
そもそもpoolingしなきゃいいのでは?
⇒ 正しく認識するためには受容野にある程度の大きさが必要。
- 受容野を広げる方法
- 深いcovolution層を用いる → 多層化に伴う演算、メモリの問題がある
- pooling and stride ⇒ 受容野を広げるために、poolingが必要。
Deconvolution(Transposed convolution)の処理手順
Up-samplingの手法の1つ
通常のcovolution層と同様にカーネルサイズ、パディング、ストライドを指定する
- 特徴マップのPixel感覚をstrideだけ空ける
- 特徴マップのまわりに(Kernel size -1) -paddingだけ余白を作る
- 畳み込み演算を行う。
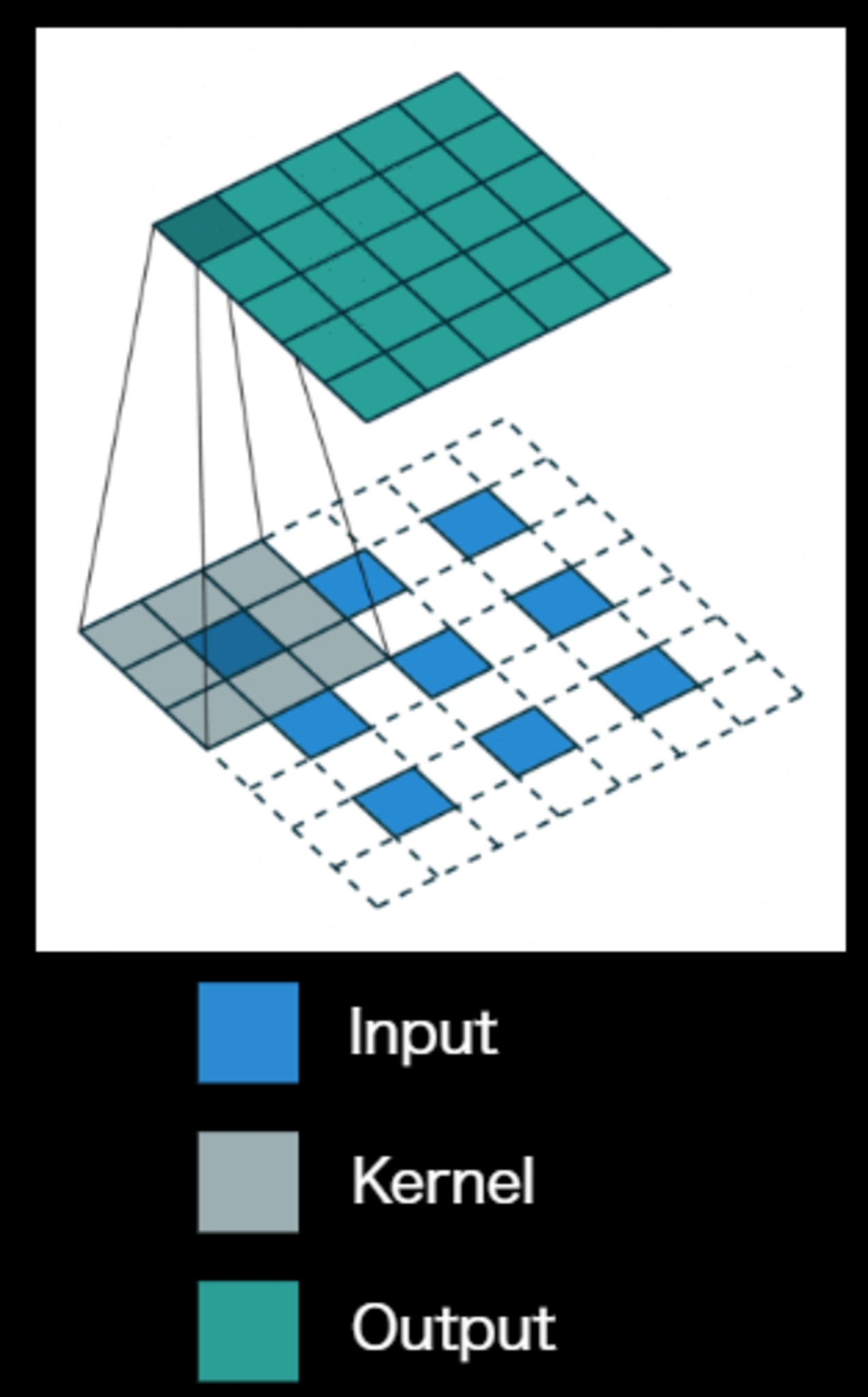
Dilated Convolution
Convolutionの段階で受容野を広げる工夫をしたもの




