大規模言語モデルの数学的原理① | Attention Is All You Need
個人的な理解や数学的な定式化として、論文に記載のない一般化された定義を与えている。
正しい情報は、原論文
Attention Is All You Need
を参照。
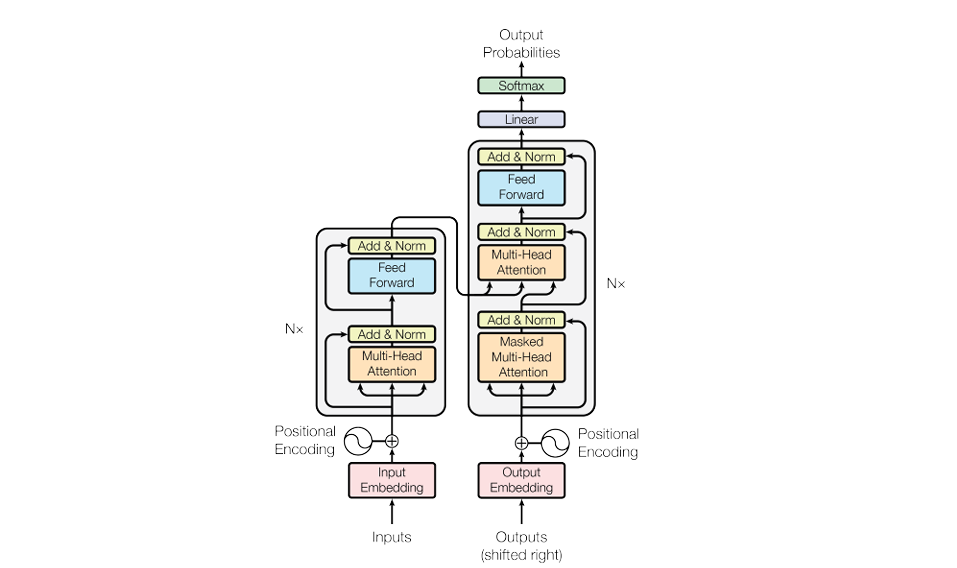 Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
Def.
$\text{String}$ と $\text{Token}$
$ $
$$
\text{トークンとは、AI が処理するテキストの基本的な単位である。}
$$
$ $
本稿では、
$$
\mathbb{N}_{>0}:=\{1,2,3,\ldots\}
$$
と約束する。
空でない集合 $U$ を固定する。$U$ の元を文字という。
すなわち、
$$
a\in U
$$
であるとき、$a$ は本稿で扱う文字である。
例えば、
$$
U=\{\mathtt{0},\mathtt{1},\mathtt{+},\mathtt{\times},a,b,c\}
$$
と定める。
このとき、
$$
\mathtt{0}\in U,\quad
\mathtt{1}\in U,\quad
\mathtt{+}\in U,\quad
a\in U
$$
であるから、$\mathtt{0}$、$\mathtt{1}$、$\mathtt{+}$、$a$ は文字である。
この段階では、$\mathtt{0}$ が数字であるか、$\mathtt{+}$ が加法記号であるか、$a$ が英字であるかは本質的ではない。
$U$ を上で固定した文字候補集合とする。
$\Sigma\subseteq U$ がアルファベットであるとは、
$$
\Sigma\ne\varnothing
$$
かつ、ある $n\in\mathbb{N}_{>0}$ と互いに異なる $a_1,\ldots,a_n\in U$ が存在して、
$$
\Sigma=\{a_1,\ldots,a_n\}
$$
と表せることをいう。
このとき、$\Sigma$ の各元を、アルファベット $\Sigma$ の文字という。
例えば、文字候補集合を
$$
U=\{\mathtt{0},\mathtt{1},\mathtt{+},\mathtt{\times},a,b,c\}
$$
とする。
このとき、
$$
\Sigma_1=\{\mathtt{0},\mathtt{1}\}
$$
は、$\Sigma_1\subseteq U$ であり、空でない有限集合であるから、アルファベットである。
$\Sigma_1$ においては、$\mathtt{0}$ と $\mathtt{1}$ が文字である。
$ $
また、
$$
\Sigma_2=\{a,b,c\}
$$
も、$\Sigma_2\subseteq U$ であり、空でない有限集合であるから、アルファベットである。
$\Sigma_2$ においては、$a,b,c$ が文字である。
このように、アルファベットとは、固定した文字候補集合 $U$ の中から、使用する文字を有限個選んだ集合である。
$\Sigma$ をアルファベットとする。$n\in\mathbb{N}_{>0}$ とする。
- $\Sigma$ 上の長さ $n$ の文字列とは、写像
$$ w:\{1,\ldots,n\}\to\Sigma $$
のことをいう。 - このとき、各 $i\in\{1,\ldots,n\}$ に対して、$w(i)$ を文字列 $w$ の第 $i$ 文字という。
通常、
$$ w(1)=a_1,\ \ldots,\ w(n)=a_n $$
であるとき、この文字列を
$$ a_1a_2\cdots a_n $$
と書く。 - また、この文字列の長さを
$$ |w|:=n $$
で定める。
$\Sigma$ をアルファベットとする。
- $\Sigma$ 上の長さ $0$ の文字列とは、空集合から $\Sigma$ へのただ $1$ つの写像
$$ \varnothing\to\Sigma $$
のことをいう。 - この文字列を空文字列といい、
$$ \varepsilon $$
で表す。 - このとき、
$$ |\varepsilon|=0 $$
である。
空集合 $\varnothing$ から $\Sigma$ への写像はただ $1$ つしか存在しない。
実際、写像 $f:\varnothing\to\Sigma$ は、任意の $x\in\varnothing$ に対して値 $f(x)\in\Sigma$ を定めるものである。
$ $
しかし、$\varnothing$ には元が存在しないため、値を指定すべき対象が存在しない。
したがって、空集合から $\Sigma$ への写像はただ $1$ つである(空虚に真)。
この意味で、長さ $0$ の文字列は一意である。
空文字列 $\varepsilon$ は、長さ $0$ の文字列であって、アルファベット $\Sigma$ の文字ではない。
本稿では、空文字列を表す記号 $\varepsilon$ は、文字候補集合 $U$ の元ではない記号として扱う。
すなわち、
$$
\varepsilon\notin U
$$
と約束する。
したがって、任意のアルファベット $\Sigma\subseteq U$ に対して、
$$
\varepsilon\notin\Sigma
$$
である。
また、$\varepsilon$ はスペース記号ではない。空文字列 $\varepsilon$ は、文字を $0$ 個並べた文字列である。
$ $
一方、スペース記号は $1$ つの文字として扱うことができる対象である。
したがって、スペース記号を文字として扱いたい場合には、スペース記号を $\Sigma$ の元として明示的に含める必要がある。
$\Sigma$ をアルファベットとする。
- 長さ $0$ の文字列全体の集合を
$$ \Sigma^0:=\{\varepsilon\} $$
で定める。 - $n\in\mathbb{N}_{>0}$ に対して、$\Sigma$ 上の長さ $n$ の文字列全体の集合を
$$ \Sigma^n := \{w\mid w:\{1,\ldots,n\}\to\Sigma\} $$
で定める。 - $\Sigma$ 上のすべての有限文字列からなる集合を
$$ \Sigma^* := \bigcup_{n=0}^{\infty}\Sigma^n $$
で定める。この集合 $\Sigma^*$ を、$\Sigma$ のクリーネ閉包という。
定義より、空文字列は $\Sigma$ 上の長さ $0$ の文字列であるから、
$$
\varepsilon\in\Sigma^0\subseteq\Sigma^*
$$
である。
したがって、
$$
\varepsilon\in\Sigma^*
$$
である。
例えば $\Sigma=\{a,b,c\}$ とすると、
$$
\Sigma^1
=
\{w\mid w:\{1\}\to\Sigma\}
$$
である。
したがって、$\Sigma^1$ の元は、次の $3$ つの写像である。
$$
w_a:\{1\}\to\Sigma,\quad w_a(1)=a
$$
$$
w_b:\{1\}\to\Sigma,\quad w_b(1)=b
$$
$$
w_c:\{1\}\to\Sigma,\quad w_c(1)=c
$$
よって、
$$
\Sigma^1=\{w_a,w_b,w_c\}
$$
である。
$a\in\Sigma$ を文字とする。
厳密には、文字 $a$ と、長さ $1$ の文字列
$$
w_a:\{1\}\to\Sigma,\quad w_a(1)=a
$$
は、一般には異なる対象である。
しかし、対応
$$
\Sigma\to\Sigma^1,\quad a\mapsto w_a
$$
は全単射である。
実際、各 $a\in\Sigma$ に対して、$w_a$ は第 $1$ 文字が $a$ である長さ $1$ の文字列である。
また、長さ $1$ の文字列 $w:\{1\}\to\Sigma$ は、値 $w(1)\in\Sigma$ によって一意に定まる。
そのため、文字 $a$ と長さ $1$ の文字列 $w_a$ を同一視し、どちらも同じ記号 $a$ で表すことがある。
例えば、アルファベットを
$$
\Sigma=\{\mathtt{0},\mathtt{1}\}
$$
とする。
このとき、
$$
\Sigma^0=\{\varepsilon\}
$$
である。
また、文字と長さ $1$ の文字列を同一視すれば、
$$
\Sigma^1=\{\mathtt{0},\mathtt{1}\}
$$
とみなせる。
長さ $2$ の文字列全体は、
$$
\Sigma^2=\{\mathtt{00},\mathtt{01},\mathtt{10},\mathtt{11}\}
$$
である。
また、写像
$$
w:\{1,2,3\}\to\Sigma
$$
を
$$
w(1)=\mathtt{0},\quad
w(2)=\mathtt{1},\quad
w(3)=\mathtt{0}
$$
で定めると、$w$ は $\Sigma$ 上の長さ $3$ の文字列であり、通常は
$$
\mathtt{010}
$$
と書く。
このように、
$$
\varepsilon,\quad
\mathtt{0},\quad
\mathtt{1},\quad
\mathtt{00},\quad
\mathtt{01},\quad
\mathtt{10},\quad
\mathtt{11},\quad
\mathtt{010}
$$
などはすべて $\Sigma$ 上の有限文字列である。
そして、
$$
\Sigma^*
=
\bigcup_{n=0}^{\infty}\Sigma^n
$$
は、$\Sigma$ 上のすべての有限文字列からなる集合である。
後でトークナイザを
$$
\operatorname{Tok}:\Sigma^*\to\mathcal{V}^*
$$
として定義する。
このとき、$\Sigma^*$ はアルファベット $\Sigma$ 上の有限列全体であり、$\mathcal{V}^*$ は語彙 $\mathcal{V}$ 上の有限列全体である。
したがって、アルファベット $\Sigma$ 上の有限列全体だけに対して $\Sigma^*$ を定義するのではなく、
任意の集合 $A$ に対して
$$
A^*
$$
を先に定義しておくと、文字列とトークン列を同じ記法で扱える。
そこで、本稿では、$A$ を集合とし、アルファベット $\Sigma$ 上の有限列全体と同様に以下を定める。
- 長さ $0$ の $A$ 上の有限列全体の集合を
$$ A^0:=\{\varepsilon\} $$
で定める。 - $n\in\mathbb{N}_{>0}$ に対して、長さ $n$ の $A$ 上の有限列全体の集合を
$$ A^n:=\{w\mid w:\{1,\ldots,n\}\to A\} $$
で定める。 - $A$ 上のすべての有限列からなる集合を
$$ A^*:=\bigcup_{n=0}^{\infty}A^n $$
で定める。
$V\in\mathbb{N}_{>0}$ とする。
- 互いに異なる対象
$$ \tau_1,\ldots,\tau_V $$
からなる有限集合
$$ \mathcal{V}:=\{\tau_1,\ldots,\tau_V\} $$
を語彙といい、$\mathcal{V}$ の元をトークン型という。文脈上、トークン型を単にトークンと呼ぶこともある。 - このとき、
$$ |\mathcal{V}|=V $$
であり、$V$ を語彙数という。
語彙 $\mathcal{V}$ は有限集合であり、それ自体には順序がない。
したがって、
$$
\mathcal{V}=\{\tau_1,\ldots,\tau_V\}
$$
という表記は、語彙の元を便宜上列挙しているだけである。
トークン型は、後述するトークナイザが出力する単位である。
したがって、トークン型は必ずしもアルファベット $\Sigma$ の文字とは限らない
$ $
例えば、トークン型は $1$ 文字に対応することもあれば、複数文字からなる文字列片に対応することもある。
また、空白、句読点、特殊記号などに対応するトークン型を語彙に含めることもある。
$ $
例えば、語彙を
$$
\mathcal{V}
=
\{\tau_{\text{私}},\tau_{\text{は}},\tau_{\text{猫}},\tau_{\text{好き}},\tau_{\text{。}}\}
$$
とする。このとき、語彙数は
$$
V=5
$$
である。また、
$$
\tau_{\text{好き}}\in\mathcal{V}
$$
であるから、$\tau_{\text{好き}}$ はトークン型である。
このトークン型 $\tau_{\text{好き}}$ は、文字列片
$$
\text{好き}
$$
に対応していると考えられる。
この文字列片は、文字としては
$$
\text{好},\quad \text{き}
$$
の $2$ 文字からなる。
したがって、トークン型は必ずしも $1$ 文字とは限らない。
$\Sigma$ をアルファベットとし、$\mathcal{V}$ を語彙とする。
- 写像
$$ \operatorname{Tok}:\Sigma^*\to\mathcal{V}^* $$
を、$\Sigma$ 上の文字列を $\mathcal{V}$ 上の有限列へ変換するトークナイザという。 - 文字列 $s\in\Sigma^*$ に対して、$\operatorname{Tok}(s)$ を $s$ のトークン列という。
- ある $m\in\mathbb{N}_{>0}$ と $\tau_{i_1},\ldots,\tau_{i_m}\in\mathcal{V}$ が存在して、
$$ \operatorname{Tok}(s)=(\tau_{i_1},\ldots,\tau_{i_m}) $$
と書けるとする。
このとき、各 $j\in\{1,\ldots,m\}$ に対して、$\tau_{i_j}$ を $s$ の第 $j$ 位置のトークン型という。
文脈上、これを単に $s$ の第 $j$ 位置のトークンと呼ぶ。 - また、位置つきの組
$$ (j,\tau_{i_j}) $$
を、$s$ の第 $j$ トークン出現ということにする。
ここで、
$$
\operatorname{Tok}(s)=\varepsilon
$$
である場合、$s$ のトークン列は空列であり、トークン出現は存在しない。
トークナイゼーションとは、文字列を処理に適した単位へ分割することである。
本稿の記法では、文字列全体の集合を
$$
\Sigma^*
$$
とし、トークン列全体の集合を
$$
\mathcal{V}^*
$$
とする。
したがって、トークナイザは、文字列をトークン列へ変換する写像
$$
\operatorname{Tok}:\Sigma^*\to\mathcal{V}^*
$$
として定式化される。
文字列
$$
s\in\Sigma^*
$$
に対して、
$$
\operatorname{Tok}(s)=(\tau_1,\ldots,\tau_m)
$$
であれば、$\operatorname{Tok}(s)$ は $s$ から得られたトークン列であり、各 $\tau_i$ は語彙 $\mathcal{V}$ の元である。
同じ文字列であっても、トークナイザが異なれば、得られるトークン列は異なりうる。
例えば、文字列
$$
s=\text{好き}
$$
に対して、ある語彙 $\mathcal{V}_1$ とトークナイザ
$$
\operatorname{Tok}_1:\Sigma^*\to\mathcal{V}_1^*
$$
は
$$
\operatorname{Tok}_1(s)=(\tau_{\text{好き}})
$$
を返すかもしれない。
一方、別の語彙 $\mathcal{V}_2$ とトークナイザ
$$
\operatorname{Tok}_2:\Sigma^*\to\mathcal{V}_2^*
$$
は
$$
\operatorname{Tok}_2(s)=(\tau_{\text{好}},\tau_{\text{き}})
$$
を返すかもしれない。
したがって、トークン列は文字列だけから絶対的に定まるものではなく、固定されたトークナイザ
$$
\operatorname{Tok}:\Sigma^*\to\mathcal{V}^*
$$
によって定まる。
一方、トークナイザ $\operatorname{Tok}$ を固定すれば、各文字列 $s\in\Sigma^*$ に対して、$\operatorname{Tok}(s)$ は一意に定まる。
LLMにおけるトークンは、必ずしも単語とは限らない。
トークンは、単語、部分語、記号、空白を含む文字列片などに対応しうる。
したがって、数学的には、トークンを自然言語上の単語として直接定義するのではなく、固定されたトークナイザ
$$
\operatorname{Tok}:\Sigma^*\to\mathcal{V}^*
$$
が出力する語彙 $\mathcal{V}$ の元、すなわちトークン型として定義するのがよい。
また、トークン列の中の位置つきの対象を扱う場合には、トークン型と区別してトークン出現と呼ぶ。
語彙を
$$
\mathcal{V}=\{\tau_1,\ldots,\tau_V\}
$$
とする。ただし、$V\in\mathbb{N}_{>0}$ とし、$\tau_1,\ldots,\tau_V$ は互いに異なるとする。
- このとき、全単射
$$ \iota:\mathcal{V}\to\{1,\ldots,V\} $$
をトークンID写像という。 - トークン型 $\tau\in\mathcal{V}$ に対して、整数
$$ \iota(\tau)\in\{1,\ldots,V\} $$
を $\tau$ のトークンIDという。
特に、列挙 $\tau_1,\ldots,\tau_V$ によって
$$
\iota(\tau_k)=k
$$
と定めることができる。
語彙 $\mathcal{V}$ は有限集合であり、それ自体には順序がない。
したがって、トークンIDは語彙 $\mathcal{V}$ だけから自然に定まるものではなく、語彙の列挙、または全単射
$$
\iota:\mathcal{V}\to\{1,\ldots,V\}
$$
を固定することによって定まる。
例えば、
$$
\mathcal{V}=\{\tau_A,\tau_B\}
$$
に対して、
$$
\iota_1(\tau_A)=1,\quad \iota_1(\tau_B)=2
$$
と定めることもできるし、
$$
\iota_2(\tau_A)=2,\quad \iota_2(\tau_B)=1
$$
と定めることもできる。
したがって、トークンIDはトークン型そのものに内在する番号ではなく、固定されたトークンID写像によって与えられる番号である。
$\Sigma$ をアルファベットとし、$\mathcal{V}$ を語彙とする。
トークナイザを
$$
\operatorname{Tok}:\Sigma^*\to\mathcal{V}^*
$$
とし、トークンID写像を
$$
\iota:\mathcal{V}\to\{1,\ldots,V\}
$$
とする。
- 文字列 $s\in\Sigma^*$ に対して、
$$ \operatorname{Tok}(s)=\varepsilon $$
であるとき、
$$ \operatorname{Tok}_{\mathrm{ID}}(s):=\varepsilon $$
と定める。 - また、ある $m\in\mathbb{N}_{>0}$ と $\tau_{i_1},\ldots,\tau_{i_m}\in\mathcal{V}$ が存在して、
$$ \operatorname{Tok}(s)=(\tau_{i_1},\ldots,\tau_{i_m}) $$
であるとき、
$$ \operatorname{Tok}_{\mathrm{ID}}(s) := (\iota(\tau_{i_1}),\ldots,\iota(\tau_{i_m})) $$
を、$s$ のトークンID列という。
このとき、
$$
\operatorname{Tok}_{\mathrm{ID}}(s)\in\{1,\ldots,V\}^*
$$
である。
Transformer に直接入力されるのは、自然言語の文字列そのものではなく、通常はトークナイザによって得られたトークンID列である。
本稿の流れでは、まず文字列
$$
s\in\Sigma^*
$$
をトークナイザによって
$$
\operatorname{Tok}(s)\in\mathcal{V}^*
$$
へ写す。
次に、各トークン型にトークンIDを対応させ、トークンIDを用いて埋め込み行列から埋め込みベクトルを取り出す。
$ $
したがって、$\operatorname{Tok}(s)$ の長さを $m$ とすると、文字列 $s\in\Sigma^*$ に対して、
$$
\operatorname{Tok}(s)=(\rho_1,\ldots,\rho_m)
$$
であるとする。
このとき、
$$
s
\longmapsto
\operatorname{Tok}(s)
\longmapsto
(\iota(\rho_1),\ldots,\iota(\rho_m))
\longmapsto
X_s\in\mathbb{R}^{m\times d_{\mathrm{model}}}
$$
という流れで、文字列 $s$ は長さ $m$ の実数行列表現へ変換される。
$m$ は、$s$ のトークン列の長さに依存する。
$\text{Input Embedding}$ と $\text{Positional Encoding}$
$ $
$$
\begin{align}
&\text{Transformer にトークン列を与えるには、各トークンをモデルが扱える実ベクトルへ変換する必要がある。}\\
&\text{さらに、自己注意機構だけでは列の順序情報が明示されないため、}\\
&\text{各トークンの位置情報を入力表現に加える必要がある。}
\end{align}
$$
$ $
語彙を $\mathcal{V}$ とし、語彙数を $V\in\mathbb{N}_{>0}$ とする。
トークンID写像を
$$
\iota:\mathcal{V}\to\{1,\ldots,V\}
$$
とし、モデル次元を $d_{\mathrm{model}}\in\mathbb{N}_{>0}$ とする。
- 行列
$$ E\in\mathbb{R}^{V\times d_{\mathrm{model}}} $$
を、$\mathcal{V}$ に対する埋め込み行列という。 - 各 $k\in\{1,\ldots,V\}$ に対して、$E$ の第 $k$ 行
$$ E_{k,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}} $$
を、トークンID $k$ に対応する埋め込みベクトルという。 - また、トークン型 $\tau\in\mathcal{V}$ に対して、
$$ \operatorname{Emb}(\tau):=E_{\iota(\tau),:}\in\mathbb{R}^{1\times d_{\mathrm{model}}} $$
を、トークン型 $\tau$ の埋め込みベクトルという。
$d_{\mathrm{model}}$ は、Transformer内部で各位置の表現ベクトルがもつ共通の次元である。
すなわち、$d_{\mathrm{model}}$ は、Transformer内部で各位置の表現を何個の実数によって表すかを表す数である。
例えば、
$$
d_{\mathrm{model}}=4
$$
であれば、各位置の表現ベクトルは
$$
(x_1,x_2,x_3,x_4)\in\mathbb{R}^{1\times 4}
$$
の形で表される。
また、
$$
d_{\mathrm{model}}=768
$$
であれば、各位置の表現ベクトルは $768$ 個の実数からなる。
埋め込み行列
$$
E\in\mathbb{R}^{V\times d_{\mathrm{model}}}
$$
は、語彙 $\mathcal{V}$ に含まれる各トークン型を、$d_{\mathrm{model}}$ 次元の実ベクトルへ対応させるための行列である。
ただし、行列 $E$ の行はトークン型そのものではなく、トークンIDによって番号づけられている。
すなわち、第 $1$ 行はトークンID $1$ に対応する埋め込みベクトルであり、第 $2$ 行はトークンID $2$ に対応する埋め込みベクトルである。
一般に、第 $k$ 行
$$
E_{k,:}
$$
は、トークンID $k$ に対応する埋め込みベクトルである。
したがって、トークン型 $\tau\in\mathcal{V}$ の埋め込みベクトルは、
$$
\operatorname{Emb}(\tau)=E_{\iota(\tau),:}
$$
である。
語彙 $\mathcal{V}$ の各トークン型は、入力埋め込み行列によって $d_{\mathrm{model}}$ 次元のベクトルへ対応づけられる。
すなわち、トークン型 $\tau\in\mathcal{V}$ の入力埋め込みは
$$
\operatorname{Emb}(\tau)\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
である。
ただし、Transformerの各層を通った後の表現は、単にトークン型だけで定まるのではなく、位置や周囲の文脈にも依存しうる。
したがって、$d_{\mathrm{model}}$ は、トークン型そのものだけでなく、各位置の内部表現全体に共通する次元である。
語彙を
$$
\mathcal{V}
=
\{\tau_{\text{私}},\tau_{\text{猫}},\tau_{\text{好き}}\}
$$
とする。
このとき、語彙数は
$$
V=3
$$
である。
トークンID写像を
$$
\iota(\tau_{\text{私}})=1,\quad
\iota(\tau_{\text{猫}})=2,\quad
\iota(\tau_{\text{好き}})=3
$$
で定める。
また、モデル次元を
$$
d_{\mathrm{model}}=2
$$
とし、埋め込み行列を
$$
E
=
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
\in\mathbb{R}^{3\times 2}
$$
とする。
- このとき、$E$ の第 $1$ 行はトークンID $1$ に対応する埋め込みベクトルであるから、
$$ E_{1,:}=(0.2,0.5) $$
である。 - また、$E$ の第 $2$ 行はトークンID $2$ に対応する埋め込みベクトルであるから、
$$ E_{2,:}=(-0.1,0.7) $$
である。 - 同様に、$E$ の第 $3$ 行はトークンID $3$ に対応する埋め込みベクトルであるから、
$$ E_{3,:}=(0.8,-0.3) $$
である。
-したがって、各トークン型の埋め込みベクトルは、
$$
\operatorname{Emb}(\tau_{\text{私}})
=
E_{\iota(\tau_{\text{私}}),:}
=
E_{1,:}
=
(0.2,0.5)
$$
$$
\operatorname{Emb}(\tau_{\text{猫}})
=
E_{\iota(\tau_{\text{猫}}),:}
=
E_{2,:}
=
(-0.1,0.7)
$$
$$
\operatorname{Emb}(\tau_{\text{好き}})
=
E_{\iota(\tau_{\text{好き}}),:}
=
E_{3,:}
=
(0.8,-0.3)
$$
である。
このように、埋め込み行列 $E$ は、トークンIDを行番号として用いることにより、各トークン型を $d_{\mathrm{model}}$ 次元の実ベクトルへ対応させる。
埋め込み行列
$$
E\in\mathbb{R}^{V\times d_{\mathrm{model}}}
$$
は、基本的には次の流れで作られる。
- 語彙 $\mathcal{V}$ を固定する。
まず、トークナイザによって扱う語彙
$$ \mathcal{V}=\{\tau_1,\ldots,\tau_V\} $$
を固定する。
このとき、語彙数は
$$ V=|\mathcal{V}| $$
である。
$ $ - モデル次元 $d_{\mathrm{model}}$ を決める。
次に、各トークン型を何次元のベクトルで表すかを決める。
これが
$$ d_{\mathrm{model}} $$
である。
$ $ - 行列の形を決める。
語彙数が $V$ で、モデル次元が $d_{\mathrm{model}}$ であるから、埋め込み行列の形は
$$ E\in\mathbb{R}^{V\times d_{\mathrm{model}}} $$
になる。
$ $ - 各成分を初期化する。
学習を始める前に、$E$ の各成分をランダムに初期化する。
例えば、概念的には
$$ E^{(0)} = (E^{(0)}_{k,j})_{1\le k\le V,\ 1\le j\le d_{\mathrm{model}}} $$
を小さな乱数で定める。
この時点では、各行ベクトルはまだ意味のある表現ではない。
$ $ - 学習によって更新する。
訓練データを用いて損失関数
$$ L $$
を小さくするように、埋め込み行列 $E$ を他のパラメータと一緒に更新する。
例えば、勾配降下法の形で書けば、
$$ E^{(t+1)} = E^{(t)} - \eta\frac{\partial L}{\partial E} $$
のように更新される。
ここで、$\eta>0$ は学習率である。
実際には Adam や AdamW などの最適化手法が使われることが多い。
$ $ - 学習後の行ベクトルを埋め込みとして使う。
学習後の埋め込み行列 $E$ の第 $k$ 行
$$ E_{k,:} $$
が、トークンID $k$ に対応する埋め込みベクトルになる。
語彙を $\mathcal{V}$ とし、語彙数を $V\in\mathbb{N}_{>0}$ とする。
トークンID写像を
$$
\iota:\mathcal{V}\to\{1,\ldots,V\}
$$
とし、モデル次元を $d_{\mathrm{model}}\in\mathbb{N}_{>0}$ とする。
埋め込み行列を
$$
E\in\mathbb{R}^{V\times d_{\mathrm{model}}}
$$
とする。
トークン型 $\tau\in\mathcal{V}$ に対して、
$$
k:=\iota(\tau)
$$
とおく。
このとき、
$$
\operatorname{Emb}(\tau):=u_kE\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
を、トークン型 $\tau$ の埋め込みベクトルという。
ただし、$u_k\in\mathbb{R}^{1\times V}$ は $k$ に対応する $\text{One-hot}$ ベクトルである。
同値に、
$$
\operatorname{Emb}(\tau)=E_{\iota(\tau),:}
$$
である。
$V\in\mathbb{N}_{>0}$ とし、$k\in\{1,\ldots,V\}$ とする。
第 $k$ 成分のみが $1$ であり、その他の成分がすべて $0$ である行ベクトル
$$
u_k\in\mathbb{R}^{1\times V}
$$
を、$k$ に対応する $\text{One-hot}$ ベクトルという。
成分で書けば、各 $r\in\{1,\ldots,V\}$ に対して、
$$
(u_k)_r
=
\begin{cases}
1 & (r=k)\\
0 & (r\ne k)
\end{cases}
$$
である。
$E\in\mathbb{R}^{V\times d_{\mathrm{model}}}$ とする。
$u_k$ は第 $k$ 成分のみが $1$ であり、その他の成分がすべて $0$ であるから、各 $j\in\{1,\ldots,d_{\mathrm{model}}\}$ に対して、
$$
(u_kE)_j
=
\sum_{r=1}^{V}(u_k)_rE_{r,j}
=
E_{k,j}
$$
である。
したがって、
$$
u_kE=E_{k,:}
$$
である。
すなわち、$\text{One-hot}$ ベクトルと埋め込み行列の積は、埋め込み行列から対応する行を取り出す操作である。
数学的には、トークン型 $\tau$ の埋め込みを
$$
\operatorname{Emb}(\tau)=u_{\iota(\tau)}E
$$
と書ける。
しかし、実装上は $\text{One-hot}$ ベクトルを明示的に作らず、トークンID $k=\iota(\tau)$ を用いて埋め込み行列 $E$ の第 $k$ 行を直接取り出すことが多い。
すなわち、
$$
\operatorname{Emb}(\tau)=E_{\iota(\tau),:}
$$
と考えればよい。
語彙を $\mathcal{V}$ とし、語彙数を $V\in\mathbb{N}_{>0}$ とする。
トークンID写像を
$$
\iota:\mathcal{V}\to\{1,\ldots,V\}
$$
とし、モデル次元を $d_{\mathrm{model}}\in\mathbb{N}_{>0}$ とする。
埋め込み行列を
$$
E\in\mathbb{R}^{V\times d_{\mathrm{model}}}
$$
とする。
$n\in\mathbb{N}_{>0}$ とし、トークン列
$$
(\tau_1,\ldots,\tau_n)\in\mathcal{V}^n
$$
をとる。各 $i\in\{1,\ldots,n\}$ に対して、
$$
k_i:=\iota(\tau_i)
$$
とおく。
また、$k_i$ に対応する $\text{One-hot}$ ベクトルを
$$
u_{k_i}\in\mathbb{R}^{1\times V}
$$
とする。
行列 $T\in\mathbb{R}^{n\times V}$ を、各 $i\in\{1,\ldots,n\}$ に対して
$$
T_{i,:}=u_{k_i}
$$
を満たす行列として定める。
すなわち、成分で書けば、各 $i\in\{1,\ldots,n\}$ と各 $r\in\{1,\ldots,V\}$ に対して、
$$
T_{i,r}
=
\begin{cases}
1 & (r=k_i)\\
0 & (r\ne k_i)
\end{cases}
$$
である。
このとき、
$$
X:=TE\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を、トークン列 $(\tau_1,\ldots,\tau_n)$ の入力埋め込みという。
各 $i\in\{1,\ldots,n\}$ に対して、
$$
X_{i,:}
=
u_{k_i}E
=
E_{k_i,:}
=
\operatorname{Emb}(\tau_i)
$$
である。
したがって、$X$ の第 $i$ 行は、第 $i$ 位置のトークン型 $\tau_i$ の埋め込みベクトルである。
トークン列
$$
(\tau_1,\ldots,\tau_n)
$$
は、トークン型を並べた列である。
各トークン型 $\tau_i$ に対して、トークンID
$$
k_i=\iota(\tau_i)
$$
を求め、埋め込み行列 $E$ の第 $k_i$ 行を取り出す。
このようにして得られる埋め込みベクトルを上から順に並べた行列が
$$
X=TE
$$
である。
すなわち、$X$ は、トークン列全体を実数行列として表したものである。
語彙数を
$$
V=3
$$
とし、モデル次元を
$$
d_{\mathrm{model}}=2
$$
とする。
語彙を
$$
\mathcal{V}=\{\tau_{\text{私}},\tau_{\text{猫}},\tau_{\text{好き}}\}
$$
とし、トークンID写像を
$$
\iota(\tau_{\text{私}})=1,\quad
\iota(\tau_{\text{猫}})=2,\quad
\iota(\tau_{\text{好き}})=3
$$
で定める。
また、埋め込み行列を
$$
E
=
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
\in\mathbb{R}^{3\times 2}
$$
とする。
トークン型 $\tau_{\text{猫}}$ のトークンIDは
$$
\iota(\tau_{\text{猫}})=2
$$
である。
$2$ に対応する $\text{One-hot}$ ベクトルは
$$
u_2=(0,1,0)\in\mathbb{R}^{1\times 3}
$$
であるから、
$$
\operatorname{Emb}(\tau_{\text{猫}})
=
u_2E
=
(0,1,0)
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
=
(-0.1,0.7)
$$
である。
したがって、$\tau_{\text{猫}}$ の埋め込みベクトルは
$$
(-0.1,0.7)\in\mathbb{R}^{1\times 2}
$$
である。
次に、トークン列
$$
(\tau_{\text{私}},\tau_{\text{猫}},\tau_{\text{好き}})
$$
を考える。
このとき、トークンID列は
$$
(1,2,3)
$$
である。
対応する $\text{One-hot}$ 行列は
$$
T
=
\begin{pmatrix}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{pmatrix}
$$
である。
したがって、トークン列の入力埋め込みは
$$
X
=
TE
=
\begin{pmatrix}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{pmatrix}
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
=
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
$$
である。
この $X$ の第 $1$ 行は $\tau_{\text{私}}$ の埋め込みベクトルであり、第 $2$ 行は $\tau_{\text{猫}}$ の埋め込みベクトルであり、第 $3$ 行は $\tau_{\text{好き}}$ の埋め込みベクトルである。
本稿では、$\text{One-hot}$ ベクトルを
$$
u_k\in\mathbb{R}^{1\times V}
$$
という行ベクトルとして扱う。
そのため、埋め込みは
$$
u_kE\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
と書かれる。
もし $\text{One-hot}$ ベクトルを列ベクトル
$$
e_k\in\mathbb{R}^{V\times 1}
$$
として扱う場合には、同じ埋め込みベクトルは
$$
E^\top e_k\in\mathbb{R}^{d_{\mathrm{model}}\times 1}
$$
として表される。
どちらの表記を採用するかは約束の違いである。
$n\in\mathbb{N}_{>0}$ とし、モデル次元を $d_{\mathrm{model}}\in\mathbb{N}_{>0}$ とする。
行列
$$
P\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を、長さ $n$ のトークン列に対する位置符号という。
各 $i\in\{1,\ldots,n\}$ に対して、$P$ の第 $i$ 行
$$
p_i:=P_{i,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
を、第 $i$ 位置の位置ベクトルという。
位置ベクトル $p_i$ は、トークン列における第 $i$ 位置の情報を表すベクトルである。
位置符号 $P$ は、長さ $n$ とモデル次元 $d_{\mathrm{model}}$ だけから常に一意に定まる対象ではない。
位置符号には、あらかじめ固定された関数によって定めるものや、学習によって定めるものなどがある。
したがって、数学的には、位置符号とは
$$
P\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
という形をもつ行列であり、その具体的な作り方はモデルの仕様として別に定める。
例えば、トークン列の長さを
$$
n=3
$$
とし、モデル次元を
$$
d_{\mathrm{model}}=2
$$
とする。
このとき、位置符号は
$$
P\in\mathbb{R}^{3\times 2}
$$
の形をもつ行列である。
例えば、
$$
P
=
\begin{pmatrix}
0.0 & 0.1\\
0.2 & 0.0\\
-0.1 & 0.3
\end{pmatrix}
$$
と定めれば、これは長さ $3$ のトークン列に対する位置符号である。
このとき、第 $1$ 位置の位置ベクトルは
$$
p_1=P_{1,:}=(0.0,0.1)
$$
である。
第 $2$ 位置の位置ベクトルは
$$
p_2=P_{2,:}=(0.2,0.0)
$$
である。
第 $3$ 位置の位置ベクトルは
$$
p_3=P_{3,:}=(-0.1,0.3)
$$
である。
したがって、位置符号 $P$ は、各位置 $1,2,3$ に対して、それぞれ $2$ 次元の位置ベクトルを対応させている。
$n\in\mathbb{N}_{>0}$ とし、$d_{\mathrm{model}}\in\mathbb{N}_{>0}$ は偶数であるとする。
各 $i\in\{1,\ldots,n\}$ と各
$$
r\in\{0,\ldots,d_{\mathrm{model}}/2-1\}
$$
に対して、
$$
P_{i,2r+1}
:=
\sin\left(
\frac{i-1}{10000^{2r/d_{\mathrm{model}}}}
\right)
$$
および
$$
P_{i,2r+2}
:=
\cos\left(
\frac{i-1}{10000^{2r/d_{\mathrm{model}}}}
\right)
$$
で定める行列
$$
P\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を、長さ $n$ に対する正弦余弦位置符号という。
上の定義では、位置 $i$ は $1$ から数えている。
そのため、原論文でいう位置
$$
pos
$$
に対応する量を
$$
pos=i-1
$$
としている。
また、列番号も $1$ から数えているため、奇数列に $\sin$、偶数列に $\cos$ を割り当てている。
これは、$0$ 始まりの添字で書かれることが多い原論文の式を、$1$ 始まりの行列添字に直したものである。
$n=3$ とし、
$$
d_{\mathrm{model}}=2
$$
とする。
このとき、
$$
r\in\{0,\ldots,d_{\mathrm{model}}/2-1\}=\{0\}
$$
である。
したがって、各 $i\in\{1,2,3\}$ に対して、
$$
P_{i,1}
=
\sin(i-1)
$$
かつ
$$
P_{i,2}
=
\cos(i-1)
$$
である。
実際、
$$
P_{1,1}=\sin 0=0,\quad P_{1,2}=\cos 0=1
$$
であり、
$$
P_{2,1}=\sin 1,\quad P_{2,2}=\cos 1
$$
であり、
$$
P_{3,1}=\sin 2,\quad P_{3,2}=\cos 2
$$
である。
したがって、長さ $3$ に対する正弦余弦位置符号は
$$
P
=
\begin{pmatrix}
\sin 0 & \cos 0\\
\sin 1 & \cos 1\\
\sin 2 & \cos 2
\end{pmatrix}
=
\begin{pmatrix}
0 & 1\\
\sin 1 & \cos 1\\
\sin 2 & \cos 2
\end{pmatrix}
$$
である。
小数で近似すれば、
$$
P
\approx
\begin{pmatrix}
0 & 1\\
0.8415 & 0.5403\\
0.9093 & -0.4161
\end{pmatrix}
$$
である。
この例では、第 $1$ 位置の位置ベクトルは
$$
p_1=(0,1)
$$
であり、第 $2$ 位置の位置ベクトルは
$$
p_2=(\sin 1,\cos 1)
$$
であり、第 $3$ 位置の位置ベクトルは
$$
p_3=(\sin 2,\cos 2)
$$
である。
つまり、正弦余弦位置符号は、位置番号 $i$ に応じて異なるベクトルを各位置に割り当てる。
Transformer は、再帰構造や畳み込み構造を用いず、自己注意機構を中心に系列を処理する。
そのため、入力埋め込みだけでは、各トークンが列のどの位置に現れたかという情報を明示的には持たない。
$ $
そこで、各位置 $pos$ に対して位置ベクトルを定め、入力埋め込みに加えることで、各トークンの表現に位置情報を付与する。
原論文では、この位置ベクトルを正弦関数と余弦関数によって定めている。
$ $
その主な意図は、固定した相対位置 $k$ に対して、
位置 $pos+k$ の位置符号を、位置 $pos$ の位置符号の線形変換として表せるようにすることである。
$ $
実際、各周波数
$$
\omega_r:=10000^{-2r/d_{\mathrm{model}}}
$$
に対して、位置 $pos$ の $2$ 次元分の位置符号は
$$
(\sin(pos\omega_r),\cos(pos\omega_r))
$$
である。
このとき、加法定理より、
$$
\sin((pos+k)\omega_r)
=
\sin(pos\omega_r)\cos(k\omega_r)
+
\cos(pos\omega_r)\sin(k\omega_r)
$$
であり、
$$
\cos((pos+k)\omega_r)
=
-\sin(pos\omega_r)\sin(k\omega_r)
+
\cos(pos\omega_r)\cos(k\omega_r)
$$
である。
したがって、
$$
\begin{pmatrix}
\sin((pos+k)\omega_r)\\
\cos((pos+k)\omega_r)
\end{pmatrix}
=
\begin{pmatrix}
\cos(k\omega_r) & \sin(k\omega_r)\\
-\sin(k\omega_r) & \cos(k\omega_r)
\end{pmatrix}
\begin{pmatrix}
\sin(pos\omega_r)\\
\cos(pos\omega_r)
\end{pmatrix}
$$
である。
$ $
右辺の行列は $pos$ には依存せず、相対的なずれ $k$ にだけ依存する。
この意味で、正弦余弦位置符号では、固定した相対位置 $k$ だけ離れた位置の符号を、現在位置の符号から線形変換によって表せる。
$ $
そのため、モデルが絶対位置だけでなく、相対位置に基づく関係を学習しやすくなると期待される。
また、正弦余弦位置符号は学習パラメータではなく、任意の位置 $pos$ に対して式で定義できる。
したがって、学習時に現れた系列長より長い系列に対しても、同じ式によって位置符号を与えられる。
$n\in\mathbb{N}_{>0}$ とし、モデル次元を $d_{\mathrm{model}}\in\mathbb{N}_{>0}$ とする。
トークン列の入力埋め込みを
$$
X\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
とし、位置符号を
$$
P\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
とする。
また、$c>0$ をスケーリング係数とする。
- このとき、
$$ Z:=cX+P\in\mathbb{R}^{n\times d_{\mathrm{model}}} $$
を、スケーリング係数 $c$ による位置情報つき入力表現という。
すなわち、各 $i\in\{1,\ldots,n\}$ と各 $j\in\{1,\ldots,d_{\mathrm{model}}\}$ に対して、
$$ Z_{i,j}:=cX_{i,j}+P_{i,j} $$
である(※)。 - 特に、$c=1$ のとき、
$$ Z=X+P $$
であり、$c=\sqrt{d_{\mathrm{model}}}$ のとき、
$$ Z=\sqrt{d_{\mathrm{model}}}X+P $$
である。
※ 同値に、各 $i\in\{1,\ldots,n\}$ に対して、
$$
Z_{i,:}=cX_{i,:}+P_{i,:}
$$
である。
Transformer 原論文の設定では、入力埋め込みを位置符号に足す前に、
$$
\sqrt{d_{\mathrm{model}}}
$$
倍して用いる。
したがって、原論文型の位置情報つき入力表現は
$$
Z:=\sqrt{d_{\mathrm{model}}}X+P
$$
である。
一方、モデルや実装によっては、スケーリングを用いずに
$$
Z:=X+P
$$
とする場合もある。
したがって、スケーリングを含めるかどうかはモデルの仕様である。
トークン埋め込み $X$ は、各位置にどのトークン型が現れたかを表す。
一方、位置符号 $P$ は、列の各位置そのものの情報を表す。
したがって、
$$
Z=cX+P
$$
は、トークン型の情報と位置の情報を同じ次元のベクトル空間内で合成した表現である。
特に、同じトークン型が異なる位置に現れた場合でも、対応する位置ベクトルが異なれば、位置情報つき入力表現も異なりうる。
同じトークン型が異なる位置に現れる場合を考える。
例えば、トークン列
$$
(\tau_{\text{猫}},\tau_{\text{猫}})
$$
をとる。
トークン型の埋め込みだけを見れば、どちらも同じ埋め込みベクトル
$$
\operatorname{Emb}(\tau_{\text{猫}})
$$
を持つ。
しかし、位置符号を加えると、第 $1$ 位置と第 $2$ 位置で位置ベクトルが異なりうるため、
$$
c\operatorname{Emb}(\tau_{\text{猫}})+P_{1,:}
$$
と
$$
c\operatorname{Emb}(\tau_{\text{猫}})+P_{2,:}
$$
は異なるベクトルになりうる。
したがって、位置情報つき入力表現では、同じトークン型であっても、出現位置の違いを反映できる。
語彙を
$$
\mathcal{V}
=
\{\tau_{\text{私}},\tau_{\text{猫}},\tau_{\text{好き}}\}
$$
とし、語彙数を
$$
V=3
$$
とする。
トークンID写像を
$$
\iota(\tau_{\text{私}})=1,\quad
\iota(\tau_{\text{猫}})=2,\quad
\iota(\tau_{\text{好き}})=3
$$
で定める。
モデル次元を
$$
d_{\mathrm{model}}=2
$$
とし、埋め込み行列を
$$
E
=
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
\in\mathbb{R}^{3\times 2}
$$
とする。
トークン列
$$
(\tau_{\text{私}},\tau_{\text{猫}},\tau_{\text{好き}})
$$
を考える。
このとき、トークンID列は
$$
(1,2,3)
$$
である。
したがって、対応する One-hot 行列は
$$
T
=
\begin{pmatrix}
1 & 0 & 0\\
0 & 1 & 0\\
0 & 0 & 1
\end{pmatrix}
$$
である。
よって、トークン列の入力埋め込みは
$$
X
=
TE
=
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
$$
である。
ここで、位置符号を
$$
P
=
\begin{pmatrix}
0.0 & 0.1\\
0.2 & 0.0\\
-0.1 & 0.3
\end{pmatrix}
\in\mathbb{R}^{3\times 2}
$$
とする。
また、原論文型のスケーリングを用いるため、
$$
c=\sqrt{d_{\mathrm{model}}}=\sqrt{2}
$$
とする。
このとき、位置情報つき入力表現は
$$
Z
=
\sqrt{2}X+P
$$
である。
具体的には、
$$
Z
=
\sqrt{2}
\begin{pmatrix}
0.2 & 0.5\\
-0.1 & 0.7\\
0.8 & -0.3
\end{pmatrix}
+
\begin{pmatrix}
0.0 & 0.1\\
0.2 & 0.0\\
-0.1 & 0.3
\end{pmatrix}
$$
である。
したがって、
$$
Z
=
\begin{pmatrix}
0.2\sqrt{2} & 0.5\sqrt{2}+0.1\\
-0.1\sqrt{2}+0.2 & 0.7\sqrt{2}\\
0.8\sqrt{2}-0.1 & -0.3\sqrt{2}+0.3
\end{pmatrix}
$$
である。
この行列 $Z$ の第 $1$ 行は、第 $1$ 位置に現れた $\tau_{\text{私}}$ の情報と第 $1$ 位置の情報を含む。
第 $2$ 行は、第 $2$ 位置に現れた $\tau_{\text{猫}}$ の情報と第 $2$ 位置の情報を含む。
第 $3$ 行は、第 $3$ 位置に現れた $\tau_{\text{好き}}$ の情報と第 $3$ 位置の情報を含む。
参考文献


この記事を高評価した人
この記事に送られたバッジ
投稿者


