【代数と言語学、あるいは量子と踊る猫。】 #1 意味論のベクトル空間モデルとプレグループ代数モデル
- 本記事は
[CSC] Bob Coecke, Mehrnoosh Sadrzadeh, Stephen Clark, Mathematical Foundations for a Compositional Distributional Model of Meaning, 2010.
の読解記録の連載記事です。
- 半順序集合およびモノイド、圏の定義を断りなく使用します。
- 不備やご指摘など大歓迎です。ぜひお願いいたします。
- 今後も修正を重ねていきますが、coming soonの部分はまだまだ調査が必要で、特に分量が増える予定です。
更新ログ
- 3/7: 書きかけで投稿。残り2割くらい。
- 3/8:
本題の前に
僕は大学で圏論の勉強会をしており、半順序集合(poset)やモノイドを学びました。また同時に、言語学や量子論に関心があり、これらに関する学際的な論文を探していたところ、[CSC]に出会いました。
この内容を大学のサークルで論文紹介できたらいいなと思い、まずは記事を書いてみることにしました。
[CSC]はDisCoCat(Distributional Compositional Categorical)という新たなパラダイムの萌芽となった論文です。現在は量子コンピュータ上での実装を目指して、QNLP(量子自然言語処理)の研究が勧められているようです。
読み進めながら、日々新たな概念や考え方に出会うことができて楽しいです。
3月中にとりあえず書き切ることが目標です。
本連載の目次
- 意味論のベクトル空間モデルとプレグループ代数モデル
- モノイダル圏からコンパクト閉圏へ
- 文法と意味を表現する圏
- 実践編: 例文の意味の計算
- 文の意味の比較
- Montague意味論とBoolean代数の半環
はじめに
構成性原理と意味論
大前提: Fregeの構成性原理
個々の部分の意味を構成的に合成することで文や句といった複雑な表現の全体の意味が成立するという原則。
ここで、構成的とは、所定の規則(つまり文法規則)に従うということである。
[3]ことばの認知科学事典より改変
これは形式意味論coming soon
意味論とは?
※これは論文の前提知識となっているため、ここでは最低限の情報だけを補足します。
意味論とは哲学や言語学の領域の学問分野であり、文や単語といった記号列が表す意味について論じる学問です。
coming soon
意味論の立場
意味論にはいろいろな立場・アプローチがあります。構成性原理に従うもの(形式意味論など)もあれば、そうでないもの(認知意味論など)もあります。
ここでは、前者の中にある2つの対立する立場として「構成的理論」と「分布的理論」に注目します。これらは相反する長所と短所を持っています。
構成的理論: 文法型と理論のモデル
- 厳密に構成的で、文法性の判定に強い。
- 定性的にすぎず、意味の違いについて述べることができない。
分布的理論: 単語ベクトルのモデル
- 定量的であり、ニュアンスの違いを評価できる。
- 非構成的であり、文法的な正しさについて述べることができない。
これらの立場の違いに関して、自然言語処理や認知科学の文脈で先行研究がなされてきました。coming soon
先行研究との違い
この論文の立場として、ベクトル空間のテンソル積を使用して、意味のベクトルを、その役割(文法的型)の組として扱います。
先行研究でも同様にテンソル空間を用いた取り組みがなされてきた潮流があるのですが、[CSC]はその欠点を克服する形で、意味のベクトルモデルを定義します。
第一の欠点
- ベクトルの内積は同じ空間にあるベクトル間でしか計算できないため、同一の文法構造を持つ文同士でしか意味を比較できない。
- そこで、いかなる文であっても単一の空間内におけるベクトルとして計算する方法を定めた。
第二の欠点
- 文法的型を表すベクトルの計算手法が整備されていない。
- 第一の欠点を克服すると、型を表すベクトルが必要なくなった。
圏論を介してつながる型代数と意味ベクトルモデル
coming soon
結局何をするの?
型そのものをベクトル空間として表し、そのテンソル積を用いて解釈し直すアプローチをとることによって、coming soon
計算言語学における2つの〈陣営〉-分布意味論とプレグループ代数文法
意味のベクトル空間モデル
たびたび引用される言語学者Firthの分布仮説「単語の意味は、それが伴う仲間(文脈)によって理解されるであろう」。これを背景として意味のベクトル空間モデルが提唱されました。
ある単語の意味はその文脈に現れる単語によって決定されるというのです。
より具体的にいうと、コーパスという自然言語の文章の集まり(言語学研究に用いられる)において、その知りたい単語を含む文があれば、文中で共起する動詞などをカウントし、それらの数値を成分に持つベクトルを考えます。
例: cherry, strawberry, digital, information
英語のコーパス内のデータにおいて、名詞 cherry, strawberry, digital, information を考えます。分布意味論の考え方に従えば、これらの単語の意味は周辺に出現する「文脈」によって決定されます。これらはテキストデータにおいて、例えば次のような単語と頻繁に共起すると考えられるでしょう。
- pie, sugar, ... との共起(食品・料理の文脈): "cherry pie" や "strawberry sugar" など。
- computer, data, ... との共起(IT・情報処理の文脈): "digital computer" や "information data" など。
このように、ある単語がどのような単語の「仲間」として現れるか(Firthの分布仮説)を統計的に処理することで、単語の意味をベクトルとして表現することが可能になります。
例えば、computer, data, pie, sugar との共起回数を考え、このようになっているとします(Jurafsky, Martin "SLP3" Figure 5.3 より抜粋)。
| 単語 | computer | data | pie | sugar |
|---|---|---|---|---|
| cherry | 2 | 8 | 442 | 25 |
| strawberry | 0 | 0 | 60 | 19 |
| digital | 1670 | 1683 | 5 | 4 |
| information | 3325 | 3982 | 5 | 13 |
そこで、各単語の単語ベクトルを次のように定義します。
$$
\ket{cherry}=\begin{pmatrix}
2 \\ 8 \\ 442 \\ 25
\end{pmatrix},
\ket{strawberry}=\begin{pmatrix}
0 \\ 0 \\ 60 \\ 19
\end{pmatrix},
\ket{digital}=\begin{pmatrix}
1670 \\ 1683 \\ 5 \\ 4
\end{pmatrix},
\ket{information}=\begin{pmatrix}
3325 \\ 3982 \\ 5 \\ 13
\end{pmatrix}
$$
分布意味論のモデルでは、これらのベクトル間の内積(inner product)を計算することで、単語間の意味的な近さを数値化できます。
実際に、カテゴリ内およびカテゴリ間での内積を計算すると以下のようになります。
$$ \bra{cherry}\ket{strawberry}=2\times0+8\times0+442\times60+25\times19=26,995 $$ $$ \bra{digital}\ket{information}=1670\times3325+1683\times3982+5\times5+4\times13=12,254,533 $$ $$ \bra{cherry}\ket{digital}=2\times1670+8\times1683+442\times5+25\times4=19,114 $$ $$ \bra{cherry}\ket{information}=2\times3325+8\times3982+442\times5+25\times13=41,041 $$ $$ \bra{strawberry}\ket{digital}=0\times1670+0\times1683+60\times5+19\times4=376 $$ $$ \bra{strawberry}\ket{information}=0\times3325+0\times3982+60\times5+19\times13=547 $$
次に、各ベクトルの $L^2$ ノルム(ベクトルの長さ)を求めます。
$$
\|\ket{cherry}\| = \sqrt{2^2+8^2+442^2+25^2} = \sqrt{196,057} \approx 442.78
$$
$$
\|\ket{strawberry}\| = \sqrt{0^2+0^2+60^2+19^2} = \sqrt{3,961} \approx 62.94
$$
$$
\|\ket{digital}\| = \sqrt{1670^2+1683^2+5^2+4^2} = \sqrt{5,621,430} \approx 2,370.96
$$
$$
\|\ket{information}\| = \sqrt{3325^2+3982^2+5^2+13^2} = \sqrt{26,912,143} \approx 5,187.69
$$
これらを用いて、単語の頻度の差を補正した類似度の指標であるコサイン類似度を算出すると、以下の結果が得られます。
| 単語 | cherry | strawberry | digital | information |
|---|---|---|---|---|
| cherry | (1.00) | 0.97 | 0.02 | 0.02 |
| strawberry | 0.97 | (1.00) | 0.00 | 0.00 |
| digital | 0.02 | 0.00 | (1.00) | 1.00 |
| information | 0.02 | 0.00 | 1.00 | (1.00) |
詳細な計算
$$ \cos\theta_{cherry, strawberry}\approx\frac{26,995}{442.78\times 62.94}\approx 0.97 $$ $$ \cos\theta_{digital, information}\approx\frac{12,254,533}{2,370.96\times 5,187.69}\approx 1.00 $$ $$ \cos\theta_{cherry, digital}\approx\frac{19,114}{442.78\times 2,370.96}\approx 0.02 $$ $$ \cos\theta_{cherry, information}\approx\frac{41,041}{442.78\times 5,187.69}\approx 0.02 $$ $$ \cos\theta_{strawberry, digital}\approx\frac{376}{62.94\times 2,370.96}\approx 0.00 $$ $$ \cos\theta_{strawberry, information}\approx\frac{547}{62.94\times 5,187.69}\approx 0.00 $$
計算結果から明らかなように、同じカテゴリに属するペア(cherry と strawberry、digital と information)は非常に高い類似度を示します。一方で、「果物」と「デジタル情報」という異なるカテゴリの間では、類似度がほぼ $0$ となり、ベクトル空間上で互いに直交に近い関係にあることが客観的な統計データから示されました。
このように、単語の意味を高次元の「意味空間」におけるベクトルとして表現し、
この手法の利点としては、ベクトル空間が単語間の距離の概念が与えられる点にあります。内積
coming soon
従来の語彙意味論の主要なアプローチは、辞書編纂者やドメイン専門家の手作業によるものでした。これは、各単語の役割や分類をすべてにわたり人間が設定していく手法です。人工知能の歴史における、当初の「ルールベース」の潮流のようなイメージに近いです。
意味のベクトル空間モデルの優位性は次の通りです。
- テキストから客観的かつ自動的に作成可能
- 意味の連続的な違いを表現可能
- 人間の認知システムが分布情報に敏感であることを示す実験的証拠とよく合致する
実際、大規模言語モデルや文書検索、語彙獲得や語義の識別性と曖昧性解消などの多くの言語処理の分野に活用されてきました。
また、認知科学の文脈では、意味処理の多岐にわたる分野: 意味的プライミングからエピソード記憶、テキスト理解にいたるまで、そのシミュレーションに成功しています。さらに、このモデルにおいて得られるコサイン類似度は、人間の類似性判断や単語連想の基準と実質的に相関していることが示されています。
型範疇理論としてのプレグループ代数
遡ること約70年前、数学者ヨアヒム・ランベック(Joachim Lambek)は数学と言語学の融合を目指して、Lambek計算(Lambek Calculus)を発表しました。その40年後、LambekはLambek計算の子孫として、プレグループという革新的な代数構造を提案しました。
プレグループは名前の通り「前群」とも訳されます。半順序集合とモノイドの構造に「随伴」の概念を加えた代数系です。
ややこしいですが、順序論において「前順序」は「半順序」より弱い(制約が少ない)のに対し、代数系としての「前群」は「半群」よりも遥かに強い(多機能な)構造を持っています。これは「群(Group)へと至る直前の高度なプロトタイプ」というニュアンスで捉えると整合性が取れます。
プレグループの数学的性質
半順序モノイド $(P,\leq, \cdot, 1)$ とは、単位元 $1$ を持つモノイド乗法 $\cdot$ を備えた半順序集合であり、任意の $p, q, r \in P$ について、$p \leq q$ ならば $r \cdot p \leq r \cdot q$ かつ $p \cdot r \leq q \cdot r$ を満たすものである。
本稿の主役となるプレグループは、この半順序モノイドに「随伴性」を課したものです。
プレグループ $(P,\leq, \cdot, 1, (-)^l, (-)^r)$ とは、その各元 $p \in P$ に対し、(*)を満たす左随伴 $p^l$ と右随伴 $p^r$ を$P$の元にもつ半順序モノイドである。
(*)$ p^l \cdot p \leq 1 \leq p \cdot p^l,\quad p \cdot p^r \leq 1 \leq p^r \cdot p $
随伴はプレグループの各元に一意的に定まります(命題1)。プレグループは、随伴の乗法に関して単位元との関係性としての不等式(*)が必ず成立する構造をもつ半順序モノイドであると言えます。
これは一見とっつきづらく、受け入れがたいかもしれませんが、文中の単語の間の簡約という操作に効いてきます。
続いて、プレグループの基本性質を見ていきましょう。これらの証明を通して、プレグループにおける元の操作の感覚が掴めるはずです。
以下、モノイド乗法の記号は必要な時に限り明示します。
- 左(右)随伴は一意である
- 随伴をとる操作は順序を反転させる: $p\leq q\Longrightarrow q^l\leq p^l, q^r\leq p^r $
- 単位元$1$の随伴は$1$である: $1^l=1=1^r$
- 積$pq$の随伴は$p,q$の随伴で表される: $(p q)^r=q^r p^r, (pq)^l=q^lp^l$
- 左随伴と右随伴をとる操作は互いに逆操作である: $(p^r)^l=p=(p^l)^r$
- 同じ随伴は反復的に(*)を満たす。
例えば、$p^rp^{rr}\leq 1\leq p^{rr}p^r, p^{lll}p^{ll}\leq 1 \leq p^{ll}p^{lll}$などが成り立つ。
証明はこちら
- 1: $r,r'$を$p\in P$の右随伴、$l,l'$を$p\in P$の左随伴とする。
$r=1r\leq (r'p)r=r'(pr)\leq r'$より、対称性から$r=r'$を得る。
左随伴に関しても同様にして$l=l'$が成り立つので、プレグループの元の左(右)随伴は一意である。 - 2: $p\leq q\Longrightarrow q^l=q^l1\leq q^l(pp^l)=(q^lp)p^l\leq(q^lq)p^l\leq 1p^l=p^l,$ $\ q^r=1q^r\leq (p^rp)q^r=p^r(pq^r)\leq p^r(qq^r)\leq p^r1=p^r$
より、$q^l\leq p^l, q^r\leq p^r$を得る。 - 3: $1$が単位元であることから、$1\cdot 1= 1$である。また、$P$が半順序集合であることから、反射律により$1\leq 1$である。以上により、$1\cdot 1\leq 1\leq 1\cdot 1$であることと随伴の一意性から$1^l=1=1^r$が従う。
- 4: $(q^lp^l)(pq)=q^l(p^lp)q\leq q^l1q=q^lq\leq 1$
$(pq)(q^lp^l)=p(qq^l)p^l\geq p1p^l=pp^l\geq 1$
により、$(q^lp^l)(pq)\leq 1\leq (pq)(q^lp^l)$が成り立つ。随伴の一意性から、$(pq)^l=q^lp^l$が得られる。右随伴についても同様に$(pq)^r=q^rp^r$が導かれる。 - 5: $(p^r)^l=(p^r)^l1\leq (p^r)^l(p^r p)=((p^r)^lp^r)p\leq 1p=p$
$(p^r)^l=1(p^r)^l\geq (pp^r)(p^r)^l=p(p^r(p^r)^l)\geq p1=p$
より$(p^r)^l=p$を得る。同様に$p=(p^l)^r$も成り立つ。 - 6: (*)において$p$を適宜$p^l,p^{ll},\cdots ,p^r,p^{rr},\cdots$に置き換えると各々の不等式が導かれる。
すなわち、列$p,p^l,p^{ll},\cdots$や$p,p^r,p^{rr},\cdots$において、隣接する2項は必ず不等式(*)を満たす。
プレグループの背景
なぜこのような代数を考えるのか?
言語の語順には明確な「方向性」があり、単純な群では記述しきれません。そこで、「左から消してくれる元(左随伴)」と「右から消してくれる元(右随伴)」を分けることで、非対称な語順を数学的に捉えることに成功しました。
Lambekは、言葉を「群(Group)」のような数学的構造の枠組みで解釈したいという願いから、「弱く、しなやかな」随伴という概念を用いて、プレグループという代数構造で数十年かけて実現したのです。
Coming soon
ランベック計算とプレグループ代数の対応
coming soon
プレグループと型範疇論理
型とは
コンピュータ科学
coming soon
型範疇論理の適用例
プレグループは、型範疇論理と同じ方法で自然言語の形式化を行います。
英語の例として、以下の基本型を固定します:
- $n$: 名詞(noun)
- $s$: 平叙文(declarative statement)
- $j$: 動詞の原型/不定詞(infinitive of the verb)
- $\sigma$: 接着型(glueing type)
ここで用いる型とは、次のように定義されます:
- 基本型は型である。
- 基本型の随伴も型である。
- 型の並置もまた、型である。
- 以上により得られるものが型であり、そうでないものは型ではない。
以上で設定された型は辞書の各単語に割り当てられます。
文中の単語の型の並置はまた、型になっていますが、それが基本型$s$に簡約されるとき、その文は「文法的」であると定義します。
簡約の方法
"John likes Mary"という例文を考えましょう。各単語には
$$ \begin{array}{ccc} \text{John} & \text{likes} & \text{Mary} \\ n & (n^r s n^l) & n \end{array} $$
これは、先ほどのプレグループの規則に従えば、
$$
\begin{align*}
n(n^rsn^l)n&=(nn^r)s(n^ln)
\quad &\text{モノイド乗法の結合法則} \\
&\leq 1s1 \quad &nn^r,n^ln\leq1\\
&=s \quad &\text{1はモノイド乗法の単位元}
\end{align*}
$$
このように、簡約はプレグループの代数に従って行われます。
また、簡約は以下のように、図式的に描かれます。
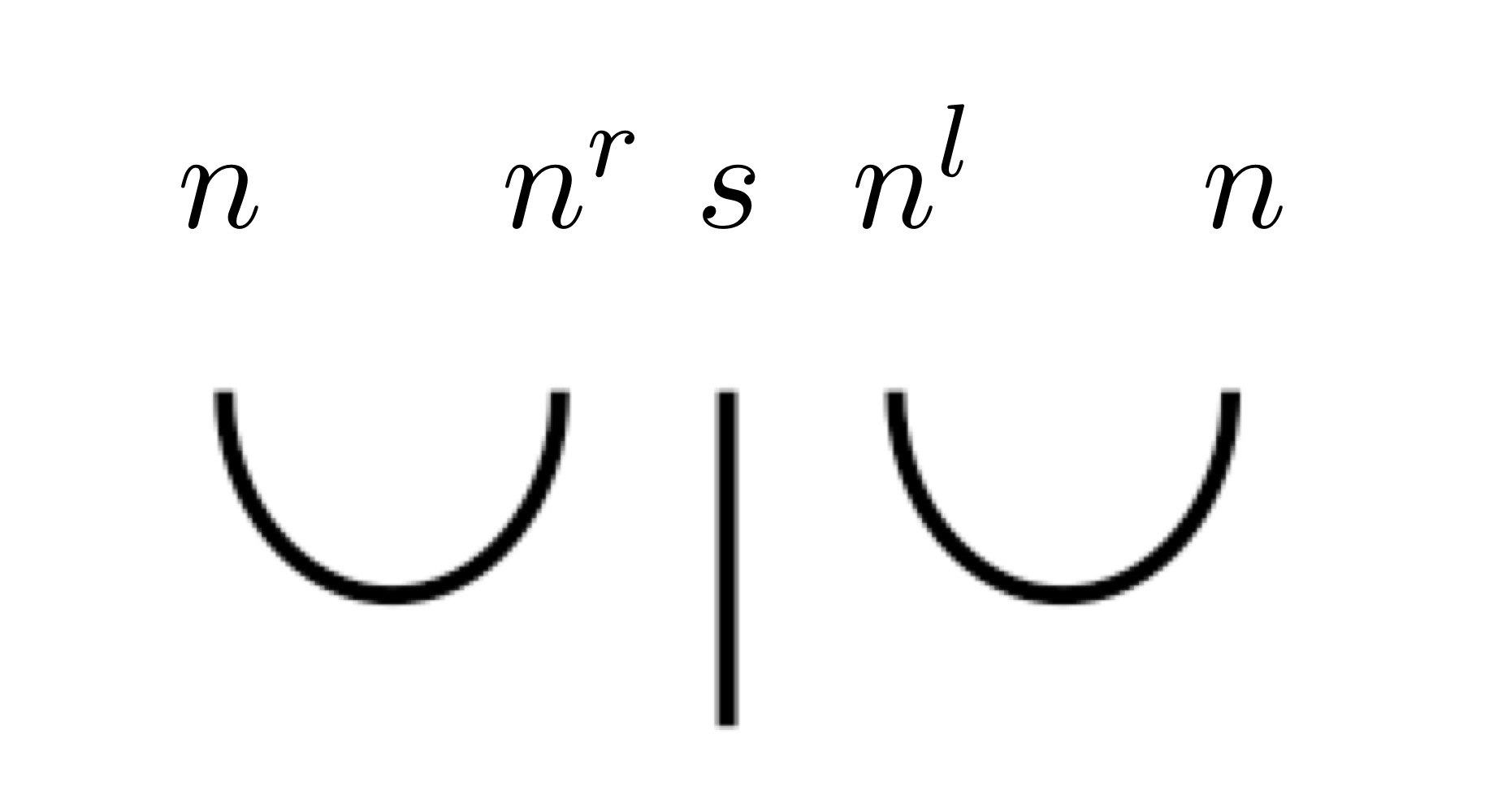 John likes Maryの型簡約の図
John likes Maryの型簡約の図
簡約の方法2
今度は否定文の型簡約をしてみます。
\begin{array}{ccc}
\text{John} & \text{does} & \text{not} & \text{likes} & \text{Mary} \\
n & (n^rsj^l\sigma) & (\sigma^rjj^l\sigma) & (\sigma^r j n^l) & n
\end{array}
同様に、次の通り型が簡約されます。
\begin{align*}
&n(n^rsj^l\sigma)(\sigma^rjj^l\sigma)(\sigma^r j n^l)n \quad&\text{}\\
&=(nn^r)s(j^l(\sigma\sigma^r)j)(j^l(\sigma\sigma^r)j)(n^ln)
\quad&\text{モノイド乗法の結合法則}\\
&\leq(nn^r)s11(n^ln)=(nn^r)s(n^ln)
\quad&(j^l(\sigma\sigma^r)j)\leq j^l1j=j^lj\leq1\\
&\leq 1s1=s
\quad& nn^r,n^ln\leq1
\end{align*}
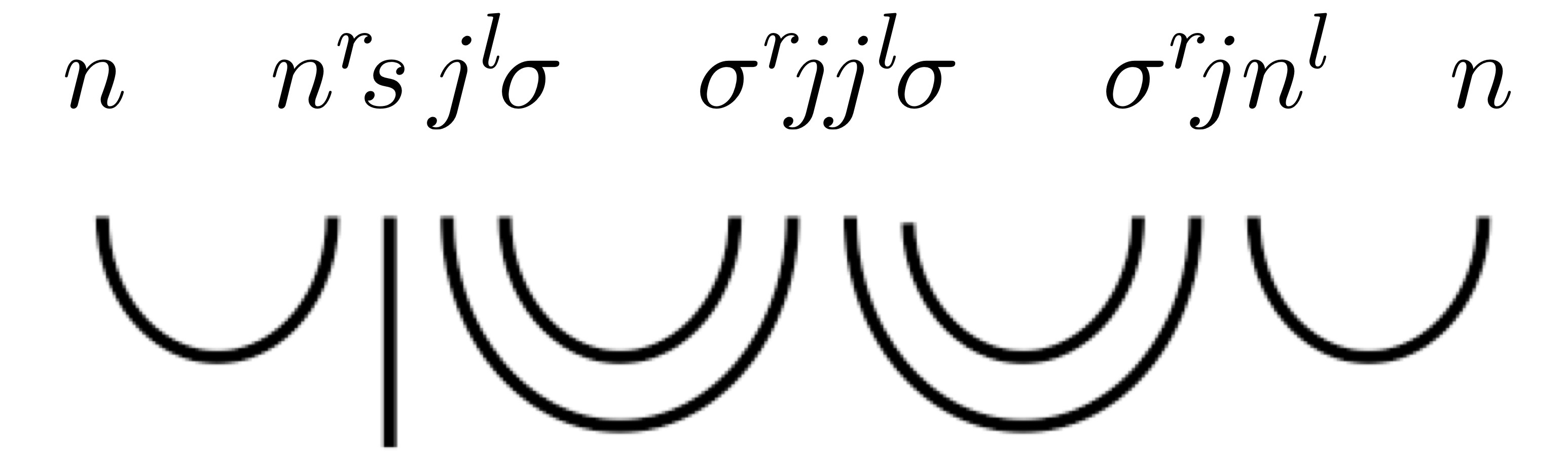 John does not like Maryの型簡約の図
John does not like Maryの型簡約の図
doesやnotで用いられている型は先行研究で導入されたものです。
coming soon
まとめ
coming soon
最後に
本記事の内容のほとんどは[CSC]の和訳や要約だったりします。また、用いた図もこの論文から引用しました。
次回はモノイダル圏とコンパクト閉圏の話をしていきます!




