大規模言語モデルの数学的原理② | Attention Is All You Need
原論文の Transformer は、Encoder と Decoder からなる系列変換モデルである。
Encoder は、入力列の各位置の表現を、入力列全体の文脈に応じて更新し、入力列全体を考慮した表現列を作る部分である。
Decoder は、既知の出力側トークン列と Encoder の出力を用いて、各位置で次に現れる出力トークンを予測(※1)するための表現列を作る部分である。
- 原論文の(以下に記載した)図では、Encoder 側には
$$ \text{Multi-Head Attention} $$
と書かれているが、これは Encoder 内の Multi-Head Self-Attention である。
すなわち、Encoder 側の各層では、Query、Key、Value が、その層へ入力される同じ系列表現から作られる。
そのうえで、複数の self-attention head を並列に計算し、それらの出力を結合して
output projection matrix(※2) をかける sub-layer である(本稿で扱う内容)。
$ $ - 一方、Decoder 側の各層には、attention sub-layer が $2$ つある。
$1$ つ目は
$$ \text{Masked Multi-Head Attention} $$
であり、これは Decoder 側の Multi-Head Self-Attention である。
すなわち、Query、Key、Value は Decoder 側の同じ系列表現から作られる。
ただし、各位置が未来の位置を参照しないように mask が入っている。
$ $
$2$ つ目は
$$ \text{Multi-Head Attention} $$
であり、これは Encoder-Decoder Attention である。
この場合、Query は前の Decoder layer の出力、すなわち Decoder 側の系列表現から作られ、
Key と Value は Encoder の出力表現列から作られる。
したがって、Decoder 側の各位置は、Encoder の出力表現列の各位置を参照できる。
-したがって、原論文の図で同じ
$$
\text{Multi-Head Attention}
$$
と書かれていても、どの系列表現から Query、Key、Value を作るかによって、
self-attention であるか Encoder-Decoder Attention であるかが異なる。
※1. 推論時には、既知の出力側トークン列は、すでに生成された出力トークン列である。
学習時には、既知の出力側トークン列は、正解出力列を右にずらした列である。
$ $
※2. 原論文では、Multi-Head Attention について
"These are concatenated and once again projected, resulting in the final values"
と述べられている。この "once again projected" に対応する学習行列が
$$
W^O\in\mathbb{R}^{h d_v\times d_{\mathrm{model}}}
$$
である。ただし、原論文では $W^O$ に特別な名称は明示されていないようである。
本稿では、この $W^O$ を output projection matrix または出力変換行列と呼ぶことにする。
ただし、ここでいう「変換」は、学習される線形変換 learned linear projection の意味である。
また「projection」は、線形代数における射影行列 $P^2=P$ を満たす正方行列を意味しない。
AI の専門家ではないため、
厳密な用語や実装上の詳細については原論文
Attention Is All You Need
を参照されたい。
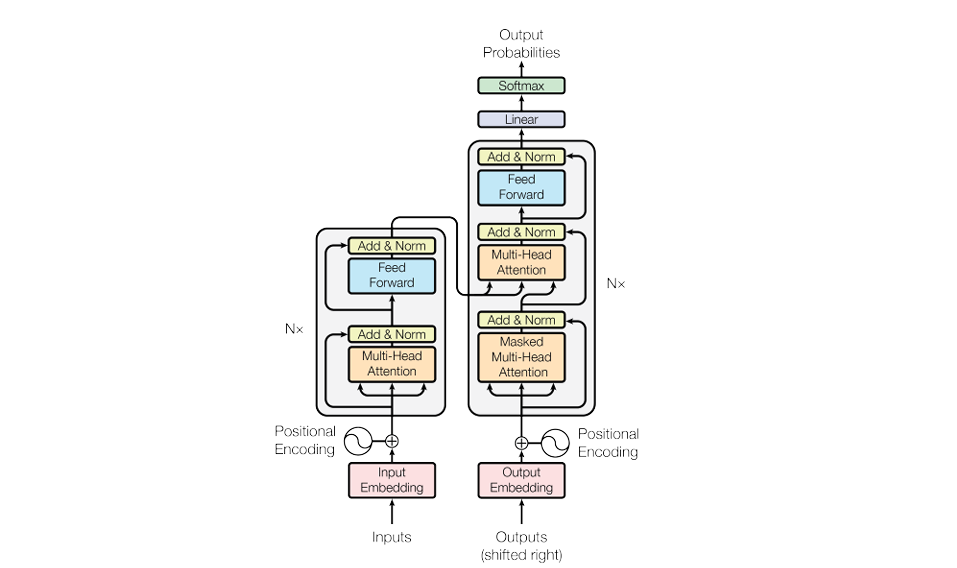 Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
Def.
$\text{Self-Attention\ (Encoder)}$
$ $
$$
\text{各トークンに固定のベクトルを割り当てるだけでなく、前後の文脈を考慮してベクトルを動的に更新する仕組み}
$$
$ $
$d_{\mathrm{model}},d_k,d_v,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ に対して、モデルの学習パラメータとして用いる行列
$$
W_r^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
を用意する。
このとき、
- $W_r^Q$ を第 $r$ ヘッドの Query 変換行列
- $W_r^K$ を第 $r$ ヘッドの Key 変換行列
- $W_r^V$ を第 $r$ ヘッドの Value 変換行列
-という。
ここで「変換」とは、原論文の Multi-Head Attention における learned linear projection を指す。
すなわち、入力表現に学習される線形変換を適用し、Query、Key、Value を作るという意味である。
$ $
後述する Query 行列、Key 行列、Value 行列と区別するために、
ここでは $W_r^Q,W_r^K,W_r^V$ をそれぞれ Query 変換行列、Key 変換行列、Value 変換行列と呼ぶ。
$ $
また、原論文における projection は、学習される線形変換という意味であり、線形代数における射影行列を意味しない。
すなわち、線形代数でいう射影行列は通常 $P^2=P$ を満たす正方行列であるが、
ここでの $W_r^Q,W_r^K,W_r^V$ は一般には正方行列でもなく、冪等性も仮定しない。
$h=1$ の場合、添字 $r=1$ を省略して、
$$
W_Q:=W_1^Q,\quad
W_K:=W_1^K,\quad
W_V:=W_1^V
$$
と書くことがある。
このとき、
$$
W_Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
である。
$d_{\mathrm{model}}$ は、Transformer 内で各位置の表現ベクトルがもつ次元である。
すなわち、系列長を $n$ とすると、Transformer の各層に入力される表現列は
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
の形で表される。ここで、第 $i$ 行
$$
\mathbf{z}_i:=Z_{i,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
は、第 $i$ 位置のトークンに対応する表現ベクトルである。
したがって、$d_{\mathrm{model}}$ は語彙数や系列長を表す数ではなく、各トークンの表現が何次元のベクトルで表されるかを表す数である。
$ $
例えば、原論文の Transformer ベースでは
$$
d_{\mathrm{model}}=512
$$
である。この場合、各位置のトークンの表現は $512$ 次元の行ベクトルとして扱われる。
$ $
また、入力トークンの埋め込みベクトルも、位置エンコーディングも、Transformer 各層の入出力も、
基本的には同じ $d_{\mathrm{model}}$ 次元にそろえられる。
$ $
これは、埋め込みベクトルと位置エンコーディングを足し合わせたり、
各 sub-layer の出力を residual connection によって元の入力に足し戻したりするためである。
一方、各 attention head の Query、Key、Value の次元 $d_k,d_v$ は、
$d_{\mathrm{model}}$ そのものとは区別される。
$ $
Transformer 原論文の Multi-Head Attention の標準設定に忠実に書く場合には、
$$
d_k=d_v=\frac{d_{\mathrm{model}}}{h}
$$
とする。この場合、$h$ は $d_{\mathrm{model}}$ を割り切ると仮定する。
$ $
したがって、$d_{\mathrm{model}}$ は Transformer 全体で各位置の表現を保持するための基本次元であり、
$d_k,d_v$ は各 head 内で Query、Key、Value を扱うための次元である。
$n,d_{\mathrm{model}},d_k,d_v,h\in\mathbb{N}_{>0}$ とする。
入力表現を
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
とする。各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{z}_i:=Z_{i,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
とおく。
各 $r\in\{1,\ldots,h\}$ に対して、Query 変換行列、Key 変換行列、Value 変換行列を
$$
W_r^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
とする。
このとき、各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{q}_i^{(r)}:=\mathbf{z}_iW_r^Q\in\mathbb{R}^{1\times d_k}
$$
$$
\mathbf{k}_i^{(r)}:=\mathbf{z}_iW_r^K\in\mathbb{R}^{1\times d_k}
$$
$$
\mathbf{v}_i^{(r)}:=\mathbf{z}_iW_r^V\in\mathbb{R}^{1\times d_v}
$$
と定める。このとき、
- $\mathbf{q}_i^{(r)}$ を第 $r$ ヘッドにおける第 $i$ 位置の Query 行ベクトル
- $\mathbf{k}_i^{(r)}$ を第 $r$ ヘッドにおける第 $i$ 位置の Key 行ベクトル
- $\mathbf{v}_i^{(r)}$ を第 $r$ ヘッドにおける第 $i$ 位置の Value 行ベクトル
-という。
ここまで 天下り的(?) だが、主に下記 $3$ 点について知っておくと、しばらくは理解しやすい。
- Query、Key、Value の(直観的な)役割
- Query、Key、Value を使って、そもそも何を実現しようとしているのか (目的は何か)?
- Query、Key、Value を使った具体的な計算。
-そこで、上記 $3$ 点を以下 $3$ つの補足にわたって説明しておく( ゚Д゚)。
まずは、図書館で本を探す場面を例に、Query、Key、Value の役割を説明する。
例えば、利用者が
$$
\text{猫の飼い方について知りたい}
$$
と思っているとする。このとき、
- この利用者の検索条件が Query に対応する。
- 一方、図書館の各本には、タイトル、分類番号、キーワード、要約などの目録情報が付いており、
この目録情報が Key に対応する。 - また、各本の本文や内容そのものが Value に対応する。
-つまり、
$$
\text{Query}=\text{探したい内容}
$$
$$
\text{Key}=\text{探される側の目録情報}
$$
$$
\text{Value}=\text{実際に取り出される中身}
$$
である。この見方では、Query と Key を照合する事は、利用者の検索条件と各本の目録情報を照らし合わせる操作 に他ならない (そして、これは後述する Query ベクトルと Key ベクトルの内積をもとに求められる )。
例えば、
$$
\text{猫の飼い方について知りたい}
$$
という Query は、
$$
\text{猫},\quad \text{ペット},\quad \text{飼育},\quad \text{餌},\quad \text{トイレ},\quad \text{健康管理}
$$
のような Key をもつ本と強く対応しやすい。
一方、
$$
\text{宇宙},\quad \text{金融},\quad \text{古代史},\quad \text{プログラミング}
$$
のような Key をもつ本とは対応しにくい。
実は、この対応の強さが後述する attention score であり、softmax 関数によって attention weight (注意重み) に変換される。
その後、attention weight が大きい本の Value、すなわち本文や内容が大きく取り出される。
$ $
ただし、実際には attention は、ただ $1$ 冊の本だけを選ぶ仕組みではない。
むしろ、検索条件に合う複数の本から、それぞれの関連度に応じて内容を少しずつ集め、混ぜ合わせる仕組み(重み付き和)である。
$ $
この意味で、Self-Attention は、各位置のトークンが、
自分の Query を使って系列内の各位置の Key を検索し、得られた重みに応じて各位置の Value を受け取る操作である。
$ $
ただし、この図書館の例は直感的な比喩である。実際の Transformer では、
Query、Key、Value は人間が直接決めた検索語、分類ラベル、本文ではない。
それらは、定義に与えたように 入力表現に学習される行列 $W_Q,W_K,W_V$ をかけることで得られるベクトルである。
Query、Key、Value を使う目的は、
文章を構成する 各トークンの表現(ベクトル) を、前後の文脈を考慮した 新しい表現(ベクトル) へ"動的に"更新すること である。
- 入力列の第 $i$ 位置のトークンが
$$ \mathbf{z}_i $$
というベクトルによって表現されているとする。
この $\mathbf{z}_i$ だけを見ると、第 $i$ 位置の表現は、その位置単独の情報に偏っている。
しかし、自然言語のトークンの意味や役割というものは、そのトークンだけで決まるわけではない。
多くの場合、前後のトークンや文全体との関係によって、そのトークンがどのような意味や役割をもつかが決まる。
$ $
例えば、「はし を 渡る」という文では、「はし」は川や道路を越える構造物を表す。
一方、「はし で 食べる」という文では、「はし」は食べ物をつかむ道具を表す。
このように、発音が同じでも、前後のトークンによって"はし"というトークンがどの意味で使われているかが明確になる。
$ $
そのため、前後の文脈が考慮されるためには、常に同じトークンに同一のベクトルを割り当てるのではなく、前後のトークンとの関係性に着目して、動的にベクトルを更新しなければならない(※2)。
$ $
※2. 入力埋め込みの段階では、同じトークン型に同じ埋め込みベクトルが割り当てられることが多い
( 詳しくはコチラ )。しかし、Self-Attention を通ることで、
その位置の表現は周囲のトークンとの関係に応じて更新される。
$ $ - そこで Self-Attention では、第 $i$ 位置のトークンの表現ベクトルから、
前後の文脈を加味した新しいベクトル
$$ \mathbf{o}_i $$
を作るため、系列内(文章)の各位置 $j$ の情報をどれくらい文脈として考慮するべきかを計算する。
この「どの位置から、どれくらい情報を受け取るか」を決めるために Query と Key を使う。
$ $
具体的には、第 $i$ 位置の Query 行ベクトル $\mathbf{q}_i$ と、各第 $j$ 位置の Key 行ベクトル $\mathbf{k}_j$ との内積
$$ \mathbf{q}_i\mathbf{k}_j^\top $$
によって、第 $i$ 位置が第 $j$ 位置をどれくらい参照するかを表すスコアを作る。
$ $ - このスコアを softmax によって正規化すると、attention weight (各トークンの注意重み)
$$ \alpha_{ij} $$
が得られる。
その後、第 $i$ 位置の新しい表現は、各位置の Value 行ベクトルを attention weight に応じて重み付き和することで作られる。
すなわち、
$$ \mathbf{o}_i = \sum_{j=1}^{n}\alpha_{ij}\mathbf{v}_j $$
である。
したがって、Query と Key は「どこを見るか」を決め、Value は「見た結果として何を受け取るか」を決める。
-このようにSelf-Attention は、各トークンの表現(ベクトル)を、自分自身を含む系列全体の文脈を考慮した新しいベクトルへ更新する仕組み である。
ここでは Single-head の場合、または $1$ つの head を固定して考えよう。
入力表現
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
の各行 $\mathbf{z}_i$ は、第 $i$ 位置のトークンの現在の表現である。
各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{z}_i:=Z_{i,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
とおく。
ここで、学習される行列
$$
W_Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
によって、
$$
\mathbf{q}_i:=\mathbf{z}_iW_Q\in\mathbb{R}^{1\times d_k}
$$
$$
\mathbf{k}_i:=\mathbf{z}_iW_K\in\mathbb{R}^{1\times d_k}
$$
$$
\mathbf{v}_i:=\mathbf{z}_iW_V\in\mathbb{R}^{1\times d_v}
$$
を作る。
そこで、例えば、入力列が
$$
\text{私},\quad \text{は},\quad \text{猫}
$$
であり、$3$つのトークンの入力表現を、それぞれ
$$
\mathbf{z}_1,\quad \mathbf{z}_2,\quad \mathbf{z}_3
$$
で表すとする。
- まず、各入力表現から Query 行ベクトル、Key 行ベクトル、Value 行ベクトルが次のように作られる。
$$ \begin{array}{ccccc} \mathbf{z}_1 & \xrightarrow{\quad \times W_Q\quad} & \mathbf{q}_1 & & \\[6pt] \mathbf{z}_2 & \xrightarrow{\quad \times W_Q\quad} & \mathbf{q}_2 & & \\[6pt] \mathbf{z}_3 & \xrightarrow{\quad \times W_Q\quad} & \mathbf{q}_3 & & \\[6pt] \\ \mathbf{z}_1 & \xrightarrow{\quad \times W_K\quad} & \mathbf{k}_1 & & \\[6pt] \mathbf{z}_2 & \xrightarrow{\quad \times W_K\quad} & \mathbf{k}_2 & & \\[6pt] \mathbf{z}_3 & \xrightarrow{\quad \times W_K\quad} & \mathbf{k}_3 & & \\[6pt] \\ \mathbf{z}_1 & \xrightarrow{\quad \times W_V\quad} & \mathbf{v}_1 & & \\[6pt] \mathbf{z}_2 & \xrightarrow{\quad \times W_V\quad} & \mathbf{v}_2 & & \\[6pt] \mathbf{z}_3 & \xrightarrow{\quad \times W_V\quad} & \mathbf{v}_3 & & \end{array} $$
ただし、ここでは例として第 $1$ 位置「私」に対応する新しい表現を作る場合だけを考える。
そのため、第 $1$ 位置の Query 行ベクトル $\mathbf{q}_1$ だけを用いる。
($\mathbf{q}_2$ と $\mathbf{q}_3$ は、それぞれ第 $2$ 位置「は」と第 $3$ 位置「猫」に対応する新しい表現を作るときに用いられるため、この例では使う事はない。
$\mathbf{q}_2$ は第 $2$ 位置の出力 $\mathbf{o}_2$ を作るときに使われ、$\mathbf{q}_3$ は第 $3$ 位置の出力 $\mathbf{o}_3$ を作るときに使う)
$ $ - 第 $1$ 位置「私」の前後の文脈を考慮した新しいベクトル表現を作るには、
まず Query 行ベクトル $\mathbf{q}_1$ と各位置の Key 行ベクトルとの内積を計算する。
すなわち、
$$ \begin{array}{ccccc} \mathbf{q}_1,\mathbf{k}_1 & \longmapsto & \mathbf{q}_1\mathbf{k}_1^\top & = & s_{11} \\[6pt] \mathbf{q}_1,\mathbf{k}_2 & \longmapsto & \mathbf{q}_1\mathbf{k}_2^\top & = & s_{12} \\[6pt] \mathbf{q}_1,\mathbf{k}_3 & \longmapsto & \mathbf{q}_1\mathbf{k}_3^\top & = & s_{13} \end{array} $$
である。
これは、第 $1$ 位置「私」から見て、
$$ \text{私},\quad \text{は},\quad \text{猫} $$
のそれぞれをどれだけ参照するかを決めるための(生の)スコアである。
(直観的には注意を向ける箇所を定量的に表した"ような"もの)。
$ $ - 次に、これらのスコアを $\sqrt{d_k}$ で割り、softmax 関数を適用することで、
$$ \alpha_{11},\quad \alpha_{12},\quad \alpha_{13} $$
という attention weight を得る。
より正確には、
$$ (\widetilde{s}_{11},\widetilde{s}_{12},\widetilde{s}_{13}) = \left( \frac{s_{11}}{\sqrt{d_k}}, \frac{s_{12}}{\sqrt{d_k}}, \frac{s_{13}}{\sqrt{d_k}} \right) $$
に対して softmax を適用し、
$$ (\alpha_{11},\alpha_{12},\alpha_{13}) = \operatorname{softmax}(\widetilde{s}_{11},\widetilde{s}_{12},\widetilde{s}_{13}) $$
と定める。
図式で書くと、
$$ \begin{array}{ccccc} (s_{11},s_{12},s_{13}) & \xrightarrow{\quad /\sqrt{d_k}\quad} & (\widetilde{s}_{11},\widetilde{s}_{12},\widetilde{s}_{13}) & \xrightarrow{\quad \operatorname{softmax(・)}\quad} & (\alpha_{11},\alpha_{12},\alpha_{13}) \end{array} $$
である(厳密には、これが注意を向ける箇所を定量的に表したもの(´・ω・`))。
$ $ - 最後に、得られた attention weight によって、各位置の Value 行ベクトルを重み付き和する。
$$ \begin{array}{ccccc} \alpha_{11},\mathbf{v}_1 & \longmapsto & \alpha_{11}\mathbf{v}_1 & & \\[6pt] \alpha_{12},\mathbf{v}_2 & \longmapsto & \alpha_{12}\mathbf{v}_2 & & \\[6pt] \alpha_{13},\mathbf{v}_3 & \longmapsto & \alpha_{13}\mathbf{v}_3 & & \end{array} $$
ここで、
$$ \alpha_{11}\mathbf{v}_1 $$
は「私」から取り出される情報の寄与であり、
$$ \alpha_{12}\mathbf{v}_2 $$
は「は」から取り出される情報の寄与であり、
$$ \alpha_{13}\mathbf{v}_3 $$
は「猫」から取り出される情報の寄与である。
これらを足し合わせた
$$ \mathbf{o}_1 = \alpha_{11}\mathbf{v}_1 + \alpha_{12}\mathbf{v}_2 + \alpha_{13}\mathbf{v}_3 $$
が、第 $1$ 位置「私」の新しいベクトル表現である。
ただし、第 $1$ 位置「私」に対応する新しい出力行ベクトルは、「私」自身だけでなく、
「は」や「猫」から得られる情報も attention weight に応じて混ぜ合わせることで更新される。
(直観的には文脈を考慮して更新されているイメージ)
説明を簡単にするため $h=1$ の場合を考える。
すなわち、
$$
W_Q:=W_1^Q,\quad
W_K:=W_1^K,\quad
W_V:=W_1^V
$$
と書く。例えば、
$$
n=3,\quad d_{\mathrm{model}}=2,\quad d_k=2,\quad d_v=2
$$
とする。入力表現を
$$
Z
=
\begin{pmatrix}
1 & 0\\
0 & 1\\
1 & 1
\end{pmatrix}
\in\mathbb{R}^{3\times 2}
$$
とする。
このとき、各位置の入力表現は
$$
\mathbf{z}_1=(1,0),\quad \mathbf{z}_2=(0,1),\quad \mathbf{z}_3=(1,1)
$$
である。
また、学習される行列の例として、
$$
W_Q
=
\begin{pmatrix}
1 & 0\\
0 & 1
\end{pmatrix}
\in\mathbb{R}^{2\times 2}
$$
$$
W_K
=
\begin{pmatrix}
1 & 1\\
1 & -1
\end{pmatrix}
\in\mathbb{R}^{2\times 2}
$$
$$
W_V
=
\begin{pmatrix}
2 & 0\\
0 & 3
\end{pmatrix}
\in\mathbb{R}^{2\times 2}
$$
を考える。
- このとき、第 $1$ 位置について、
$$ \mathbf{q}_1 = \mathbf{z}_1W_Q = (1,0) \begin{pmatrix} 1 & 0\\ 0 & 1 \end{pmatrix} = (1,0) $$
であり、
$$ \mathbf{k}_1 = \mathbf{z}_1W_K = (1,0) \begin{pmatrix} 1 & 1\\ 1 & -1 \end{pmatrix} = (1,1) $$
であり、
$$ \mathbf{v}_1 = \mathbf{z}_1W_V = (1,0) \begin{pmatrix} 2 & 0\\ 0 & 3 \end{pmatrix} = (2,0) $$
である。 - 同様に、第 $2$ 位置について、
$$ \mathbf{q}_2 = \mathbf{z}_2W_Q = (0,1) $$
$$ \mathbf{k}_2 = \mathbf{z}_2W_K = (1,-1) $$
$$ \mathbf{v}_2 = \mathbf{z}_2W_V = (0,3) $$
である。 - また、第 $3$ 位置について、
$$ \mathbf{q}_3 = \mathbf{z}_3W_Q = (1,1) $$
$$ \mathbf{k}_3 = \mathbf{z}_3W_K = (2,0) $$
$$ \mathbf{v}_3 = \mathbf{z}_3W_V = (2,3) $$
である。
-したがって、この例では、
$$
\mathbf{q}_1=(1,0),\quad \mathbf{q}_2=(0,1),\quad \mathbf{q}_3=(1,1)
$$
$$
\mathbf{k}_1=(1,1),\quad \mathbf{k}_2=(1,-1),\quad \mathbf{k}_3=(2,0)
$$
$$
\mathbf{v}_1=(2,0),\quad \mathbf{v}_2=(0,3),\quad \mathbf{v}_3=(2,3)
$$
である。
これらを行に並べると、
$$
Q
=
\begin{pmatrix}
\mathbf{q}_1\\
\mathbf{q}_2\\
\mathbf{q}_3
\end{pmatrix}
=
\begin{pmatrix}
1 & 0\\
0 & 1\\
1 & 1
\end{pmatrix}
$$
$$
K
=
\begin{pmatrix}
\mathbf{k}_1\\
\mathbf{k}_2\\
\mathbf{k}_3
\end{pmatrix}
=
\begin{pmatrix}
1 & 1\\
1 & -1\\
2 & 0
\end{pmatrix}
$$
$$
V
=
\begin{pmatrix}
\mathbf{v}_1\\
\mathbf{v}_2\\
\mathbf{v}_3
\end{pmatrix}
=
\begin{pmatrix}
2 & 0\\
0 & 3\\
2 & 3
\end{pmatrix}
$$
である。
このように、同じ入力表現 $\mathbf{z}_i$ から、異なる学習行列 $W_Q,W_K,W_V$ によって、
Query ベクトル、Key ベクトル、Value ベクトルがそれぞれ作られる。
$n,d_k,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{q}_i^{(r)}\in\mathbb{R}^{1\times d_k}
$$
を Query 行ベクトルとする。
また、各 $r\in\{1,\ldots,h\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{k}_j^{(r)}\in\mathbb{R}^{1\times d_k}
$$
を Key 行ベクトルとする。
各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{q}_i^{(r)}
=
(q_{i,1}^{(r)},\ldots,q_{i,d_k}^{(r)})
$$
と成分表示する。
また、各 $r\in\{1,\ldots,h\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{k}_j^{(r)}
=
(k_{j,1}^{(r)},\ldots,k_{j,d_k}^{(r)})
$$
と成分表示する。
このとき、各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、
$$
s_{i,j}^{(r)}
:=
\sum_{\ell=1}^{d_k}
q_{i,\ell}^{(r)}k_{j,\ell}^{(r)}
\in\mathbb{R}
$$
と定める。
この実数 $s_{i,j}^{(r)}$ を、第 $r$ ヘッドにおける第 $i$ 位置から第 $j$ 位置へのスケーリング前の(生の) attention score という。
上の定義は、
$$
s_{i,j}^{(r)}
=
\left[
\mathbf{q}_i^{(r)}
(\mathbf{k}_j^{(r)})^\top
\right]_{1,1}
$$
と同値である。ここで、
$$
\mathbf{q}_i^{(r)}
(\mathbf{k}_j^{(r)})^\top
\in\mathbb{R}^{1\times 1}
$$
である。
したがって、厳密にはこの積は $1\times 1$ 行列であるが、
$1\times 1$ 行列をその唯一の成分として定めた実数として同一視する事で
$$
s_{i,j}^{(r)}
=
\mathbf{q}_i^{(r)}
(\mathbf{k}_j^{(r)})^\top
$$
と書く。
スケーリング前の(生の) attention score は
$$
s_{i,j}^{(r)}
=
\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top
$$
であり、
第 $r$ ヘッドにおける第 $i$ 位置の Query 行ベクトルと各第 $j$ 位置の Key 行ベクトルの内積である。
内積とは、対応する成分どうしを掛けて、それらをすべて足し合わせた値である。
$ $
この値は、第 $i$ 位置の Query 行ベクトルと第 $j$ 位置の Key 行ベクトルがどれだけよく対応しているかを表すスコアとして用いられる。
直感的には、$\mathbf{q}_i^{(r)}$ は第 $i$ 位置から見た問い合わせ側の特徴であり、$\mathbf{k}_j^{(r)}$ は第 $j$ 位置が問い合わせと照合されるための特徴である。
したがって、
$$
\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top
$$
は、第 $i$ 位置から見て、第 $j$ 位置をどれだけ参照しやすいかを決めるための(生の)スコアである。
$n,d_k,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{q}_i^{(r)}\in\mathbb{R}^{1\times d_k}
$$
を Query 行ベクトルとし、各 $r\in\{1,\ldots,h\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{k}_j^{(r)}\in\mathbb{R}^{1\times d_k}
$$
を Key 行ベクトルとする。
各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、(生の) attention score を
$$
s_{i,j}^{(r)}
:=
\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top \in \mathbb{R}
$$
と定める。
このとき、
$$
\widetilde{s}_{i,j}^{(r)}
:=
\frac{s_{i,j}^{(r)}}{\sqrt{d_k}}
=
\frac{\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top}{\sqrt{d_k}}
\in\mathbb{R}
$$
を、第 $r$ ヘッドにおける第 $i$ 位置から第 $j$ 位置への scaled dot-product score という。
原論文では Scaled Dot-Product Attention という関数名が使われているが、各成分
$$
\widetilde{s}_{i,j}^{(r)}
$$
を scaled dot-product score と呼ぶことは、原論文の正式用語というより、本ノート内で導入した用語である。
scaled dot-product score は
$$
\widetilde{s}_{i,j}^{(r)}
=
\frac{s_{i,j}^{(r)}}{\sqrt{d_k}}
$$
であり、(生の) attention score を $\sqrt{d_k}$ で割った値である。
どちらも softmax 前のスコアであり、attention weight そのものではない。
$\sqrt{d_k}$ は、Key 行ベクトルおよび Query 行ベクトルの次元 $d_k$ の平方根である。
ここで、
$$
\mathbf{q}_i^{(r)},\mathbf{k}_j^{(r)}\in\mathbb{R}^{1\times d_k}
$$
であるから、$\mathbf{q}_i^{(r)}$ と $\mathbf{k}_j^{(r)}$ はどちらも $d_k$ 個の成分をもつ行ベクトルである。
そのため、内積
$$
\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top
$$
は $d_k$ 個の積の和である。そのため、$d_k$ が大きいと、この内積の値の大きさが大きくなりやすい。
そこで、scaled dot-product attention では、この内積を
$$
\sqrt{d_k}
$$
で割る。すなわち、
$$
\widetilde{s}_{i,j}^{(r)}
=
\frac{
\mathbf{q}_i^{(r)}(\mathbf{k}_j^{(r)})^\top
}{
\sqrt{d_k}
}
$$
とする。この $\sqrt{d_k}$ は、softmax に入力される値が大きくなりすぎることを抑えるためのスケーリング係数である。
$ $
原論文では、Scaled Dot-Product Attention を $\operatorname{softmax}(QK^\top/\sqrt{d_k})V$ と定義し、
$d_k$ が大きいと内積が大きくなって softmax が極端になり、勾配が小さくなりやすいため $\sqrt{d_k}$ で割るとされている。
$ $
もう少し確率論的な補足を言うと、成分が平均 $0$、分散 $1$ 程度だと仮定すると、内積は $d_k$ 個の項の和なので分散がおおよそ $d_k$ になる。
したがって、$\sqrt{d_k}$ で割ると分散がおおよそ $1$ に戻り、次元 $d_k$ によってスコアのスケールが大きくなりすぎることを防げる。
$n,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、
$$
\widetilde{s}_{i,j}^{(r)}\in\mathbb{R}
$$
を第 $r$ ヘッドにおける第 $i$ 位置から第 $j$ 位置への scaled dot-product score とする。
- 各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、
$$ \alpha_{i,j}^{(r)} := \frac{ \exp(\widetilde{s}_{i,j}^{(r)}) }{ \sum_{\ell=1}^{n}\exp(\widetilde{s}_{i,\ell}^{(r)}) } $$
と定める。すなわち、各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$ (\alpha_{i,1}^{(r)},\ldots,\alpha_{i,n}^{(r)}) = \operatorname{softmax} (\widetilde{s}_{i,1}^{(r)},\ldots,\widetilde{s}_{i,n}^{(r)}) $$
と定める。
この $\alpha_{i,j}^{(r)}$ を、第 $r$ ヘッドにおける第 $i$ 位置から第 $j$ 位置への attention weight という。
$ $ - このとき、各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、
$$ 0<\alpha_{i,j}^{(r)}\le 1 $$
であり、各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$ \sum_{j=1}^{n}\alpha_{i,j}^{(r)}=1 $$
である。
$m\in\mathbb{N}_{>0}$ とする。
集合 $\Delta_m$ を
$$
\Delta_m
:=
\left\{
(p_1,\ldots,p_m)\in\mathbb{R}^{1\times m}
\mid
\forall j\in\{1,\ldots,m\}\ (p_j>0)
\ \land\
\sum_{j=1}^{m}p_j=1
\right\}
$$
と定める。
$\mathbf{x}=(x_1,\ldots,x_m)\in\mathbb{R}^{1\times m}$ に対して、
$$
\operatorname{softmax}(\mathbf{x})
:=
\left(
\frac{\exp(x_1)}{\sum_{\ell=1}^{m}\exp(x_\ell)},
\ldots,
\frac{\exp(x_m)}{\sum_{\ell=1}^{m}\exp(x_\ell)}
\right)
$$
と定める。
このとき、写像
$$
\operatorname{softmax}:\mathbb{R}^{1\times m}\to\Delta_m
$$
を softmax 関数という。
すなわち、各 $j\in\{1,\ldots,m\}$ に対して、
$$
\operatorname{softmax}(\mathbf{x})_j
=
\frac{\exp(x_j)}{\sum_{\ell=1}^{m}\exp(x_\ell)}
$$
である(つまり、実数値の行ベクトルを正規化された正の行ベクトルへ写す写像である)。
$m,n\in\mathbb{N}_{>0}$ とする。$S\in\mathbb{R}^{m\times n}$ とする。
このとき、行列 $\operatorname{softmax}_{\mathrm{row}}(S)\in\mathbb{R}^{m\times n}$ を、各 $i\in\{1,\ldots,m\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
\left(\operatorname{softmax}_{\mathrm{row}}(S)\right)_{i,j}
:=
\frac{\exp(S_{i,j})}{\sum_{\ell=1}^{n}\exp(S_{i,\ell})}
$$
によって定める。
$n,d_v,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ と各 $i,j\in\{1,\ldots,n\}$ に対して、
$$
\alpha_{i,j}^{(r)}\in\mathbb{R}
$$
を第 $r$ ヘッドにおける第 $i$ 位置から第 $j$ 位置への attention weight とする。
また、各 $r\in\{1,\ldots,h\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{v}_j^{(r)}\in\mathbb{R}^{1\times d_v}
$$
を第 $r$ ヘッドにおける第 $j$ 位置の Value 行ベクトルとする。
各 $r\in\{1,\ldots,h\}$ と各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{o}_i^{(r)}
:=
\sum_{j=1}^{n}\alpha_{i,j}^{(r)}\mathbf{v}_j^{(r)}
\in\mathbb{R}^{1\times d_v}
$$
と定める。
この $\mathbf{o}_i^{(r)}$ を、第 $r$ ヘッドにおける第 $i$ 位置の self-attention 出力行ベクトルという。
この定義は、mask を用いない full self-attention の定義である。
(ここまでの内容はエンコーダー側の説明であり、デコーダー側では、後続位置へ attention しないよう mask を用いる箇所がある。)
すなわち、第 $r$ ヘッドにおける第 $i$ 位置の self-attention 出力は、全位置の Value 行ベクトル
$$
\mathbf{v}_1^{(r)},\ldots,\mathbf{v}_n^{(r)}
$$
を、第 $i$ 位置から各位置への attention weight
$$
\alpha_{i,1}^{(r)},\ldots,\alpha_{i,n}^{(r)}
$$
によって重み付き和した行ベクトルである。
ここまで、成分ごとに説明してきた内容を行列でまとめて表現すると、
以下のように簡潔に表現できる('Д')。
$m,n,d_k,d_v\in\mathbb{N}_{>0}$ とする。
Query 行列、Key 行列、Value 行列をそれぞれ
$$
Q\in\mathbb{R}^{m\times d_k}
$$
$$
K\in\mathbb{R}^{n\times d_k}
$$
$$
V\in\mathbb{R}^{n\times d_v}
$$
とする。
このとき、写像
$$
\operatorname{Attention}:
\mathbb{R}^{m\times d_k}
\times
\mathbb{R}^{n\times d_k}
\times
\mathbb{R}^{n\times d_v}
\to
\mathbb{R}^{m\times d_v}
$$
を
$$
\operatorname{Attention}(Q,K,V)
:=
\operatorname{softmax}_{\mathrm{row}}
\left(
\frac{QK^\top}{\sqrt{d_k}}
\right)
V
$$
によって定める。
この写像を Scaled Dot-Product Attention という。
ここで、$\operatorname{softmax}_{\mathrm{row}}$ は、行列の各行に softmax を適用する操作である。
Query 行列、Key 行列、Value 行列を
$$
Q=
\begin{pmatrix}
\mathbf{q}_1\\
\vdots\\
\mathbf{q}_m
\end{pmatrix}
\in\mathbb{R}^{m\times d_k}
$$
$$
K=
\begin{pmatrix}
\mathbf{k}_1\\
\vdots\\
\mathbf{k}_n
\end{pmatrix}
\in\mathbb{R}^{n\times d_k}
$$
$$
V=
\begin{pmatrix}
\mathbf{v}_1\\
\vdots\\
\mathbf{v}_n
\end{pmatrix}
\in\mathbb{R}^{n\times d_v}
$$
とする。
このとき、
$$
QK^\top\in\mathbb{R}^{m\times n}
$$
であり、その第 $(i,j)$ 成分は、各 $i\in\{1,\ldots,m\}$ と各 $j\in\{1,\ldots,n\}$ に対して、
$$
(QK^\top)_{i,j}
=
\mathbf{q}_i\mathbf{k}_j^\top
$$
である。
したがって、
$$
\frac{QK^\top}{\sqrt{d_k}}
$$
の第 $(i,j)$ 成分は
$$
\frac{\mathbf{q}_i\mathbf{k}_j^\top}{\sqrt{d_k}}
$$
である。
これに各行ごとに softmax を適用して得られる行列を
$$
A:=
\operatorname{softmax}_{\mathrm{row}}
\left(
\frac{QK^\top}{\sqrt{d_k}}
\right)
\in\mathbb{R}^{m\times n}
$$
とおく。
この行列 $A$ を attention weight 行列という。
$A$ の第 $(i,j)$ 成分を $\alpha_{i,j}$ と書けば、
$$
A_{i,j}=\alpha_{i,j}
$$
である。
このとき、
$$
\operatorname{Attention}(Q,K,V)=AV
$$
であり、
$$
AV\in\mathbb{R}^{m\times d_v}
$$
である。
さらに、その第 $i$ 行は、各 $i\in\{1,\ldots,m\}$ に対して、
$$
(AV)_{i,:}
=
\sum_{j=1}^{n}\alpha_{i,j}\mathbf{v}_j
$$
である。
したがって、
$$
\operatorname{softmax}_{\mathrm{row}}
\left(
\frac{QK^\top}{\sqrt{d_k}}
\right)V
$$
は、各 Query 位置に対して、各 Value 行ベクトルを attention weight によって重み付き和する操作を、まとめて行列で書いたものである。
$n,d_{\mathrm{model}},d_k,d_v,h\in\mathbb{N}_{>0}$ とする。
入力表現を
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
とする。
各 $r\in\{1,\ldots,h\}$ に対して、Query 変換行列、Key 変換行列、Value 変換行列を
$$
W_r^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k}
$$
$$
W_r^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
とする。
このとき、第 $r$ ヘッドの Query 行列、Key 行列、Value 行列をそれぞれ
$$
Q^{(r)}:=ZW_r^Q\in\mathbb{R}^{n\times d_k}
$$
$$
K^{(r)}:=ZW_r^K\in\mathbb{R}^{n\times d_k}
$$
$$
V^{(r)}:=ZW_r^V\in\mathbb{R}^{n\times d_v}
$$
と定める。
すなわち、各 $i\in\{1,\ldots,n\}$ に対して、
$$
\mathbf{q}_i^{(r)}:=Q^{(r)}_{i,:},\quad
\mathbf{k}_i^{(r)}:=K^{(r)}_{i,:},\quad
\mathbf{v}_i^{(r)}:=V^{(r)}_{i,:}
$$
とおくと、
$$
Q^{(r)}
=
\begin{pmatrix}
\mathbf{q}_1^{(r)}\\
\vdots\\
\mathbf{q}_n^{(r)}
\end{pmatrix}
$$
$$
K^{(r)}
=
\begin{pmatrix}
\mathbf{k}_1^{(r)}\\
\vdots\\
\mathbf{k}_n^{(r)}
\end{pmatrix}
$$
$$
V^{(r)}
=
\begin{pmatrix}
\mathbf{v}_1^{(r)}\\
\vdots\\
\mathbf{v}_n^{(r)}
\end{pmatrix}
$$
である。
すなわち、$Q^{(r)}$ は第 $r$ ヘッドの Query 行ベクトルを行に並べた行列であり、
$K^{(r)}$ は第 $r$ ヘッドの Key 行ベクトルを行に並べた行列であり、$V^{(r)}$ は第 $r$ ヘッドの Value 行ベクトルを行に並べた行列である。
$n,d_{\mathrm{model}},d_k,d_v,h\in\mathbb{N}_{>0}$ とする。
入力表現を
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
とする。
各 $r\in\{1,\ldots,h\}$ に対して、
$$
W_r^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_r^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_r^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
とする。
同じ入力表現 $Z$ から
$$
Q^{(r)}:=ZW_r^Q,\quad
K^{(r)}:=ZW_r^K,\quad
V^{(r)}:=ZW_r^V
$$
を定める。このとき、
$$
O^{(r)}
:=
\operatorname{Attention}(Q^{(r)},K^{(r)},V^{(r)})
$$
すなわち、
$$
O^{(r)}
=
\operatorname{softmax}_{\mathrm{row}}
\left(
\frac{Q^{(r)}(K^{(r)})^\top}{\sqrt{d_k}}
\right)
V^{(r)}
\in\mathbb{R}^{n\times d_v}
$$
を計算する操作を、第 $r$ ヘッドの Self-Attention という。
すなわち、Query 行列、Key 行列、Value 行列が同じ系列 $Z$ から作られる attention を Self-Attention という。
$h=1$ の場合、添字 $r=1$ を省略して、
$$
W_Q:=W_1^Q,\quad
W_K:=W_1^K,\quad
W_V:=W_1^V
$$
と書くことがある。
このとき、
$$
Q=ZW_Q,\quad
K=ZW_K,\quad
V=ZW_V
$$
であり、
$$
\operatorname{Attention}(Q,K,V)
=
\operatorname{softmax}_{\mathrm{row}}
\left(
\frac{QK^\top}{\sqrt{d_k}}
\right)V
$$
である。
ここまでで、第 $r$ ヘッドの Self-Attention 出力
$$
O^{(r)}
=
\operatorname{Attention}(Q^{(r)},K^{(r)},V^{(r)})
\in
\mathbb{R}^{n\times d_v}
$$
を定義した。
ただし、これは Multi-Head Attention 全体の出力ではなく、$1$ つの head の出力である。
Multi-Head Attention では、各 head の出力
$$
O^{(1)},\ldots,O^{(h)}
$$
を列方向に結合し、さらに学習行列 $W^O$ をかけることで、再び $d_{\mathrm{model}}$ 次元の表現列を得る。
$\text{Multi-Head Attention\ (Encoder)}$
$ $
$$
\text{必要なのは Attention だけである(*´ω`)}
$$
$ $
$n,d_v,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ に対して、
$$
O^{(r)}\in\mathbb{R}^{n\times d_v}
$$
とする。
このとき、各 $O^{(r)}$ を列ブロックとして横に並べた行列を
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
:=
\begin{pmatrix}
O^{(1)} & O^{(2)} & \cdots & O^{(h)}
\end{pmatrix}
\in
\mathbb{R}^{n\times hd_v}
$$
と定める。
すなわち、各 $i\in\{1,\ldots,n\}$、各 $r\in\{1,\ldots,h\}$、各 $a\in\{1,\ldots,d_v\}$ に対して、
$$
\left(
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
\right)_{i,(r-1)d_v+a}
=
O^{(r)}_{i,a}
$$
である。
各 $r\in\{1,\ldots,h\}$ に対して、
$$
O^{(r)}\in\mathbb{R}^{n\times d_v}
$$
であるとする。このとき、各 $O^{(r)}$ を列ブロックとして横に並べた行列
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
:=
\begin{pmatrix}
O^{(1)} & O^{(2)} & \cdots & O^{(h)}
\end{pmatrix}
$$
は、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
\in
\mathbb{R}^{n\times hd_v}
$$
を満たす。
実際、各 $O^{(r)}$ は $n$ 行 $d_v$ 列の行列である。
したがって、横に並べると行数は変わらず $n$ のままであり、列数は
$$
d_v+d_v+\cdots+d_v
=
hd_v
$$
となる。
ゆえに、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
\in
\mathbb{R}^{n\times hd_v}
$$
である。
$d_{\mathrm{model}},d_v,h\in\mathbb{N}_{>0}$ とする。
各 head の出力を列ブロックとして横に並べた後に用いる学習行列
$$
W^O\in\mathbb{R}^{hd_v\times d_{\mathrm{model}}}
$$
を、本稿では出力変換行列という。
原論文では、Multi-Head Attention について
$$
\text{These are concatenated and once again projected, resulting in the final values}
$$
と述べられている。この $\text{once again projected}$ に対応する学習行列が
$$
W^O\in\mathbb{R}^{hd_v\times d_{\mathrm{model}}}
$$
である。ただし、原論文では $W^O$ に特別な名称は明示されていないようである。
本稿では、この $W^O$ を output projection matrix または出力変換行列と呼ぶことにする。
$ $
ただし、原論文における projection は、学習される線形変換、すなわち learned linear projection の意味であり、線形代数における射影行列を意味しない。
すなわち、線形代数でいう射影行列は通常 $P^2=P$ を満たす正方行列であるが、ここでの $W^O$ は一般には正方行列でもなく、冪等性も仮定しない。
Multi-Head Attention では、各 head がそれぞれ異なる Query、Key、Value の線形変換を用いて attention を計算する。
そのため、第 $r$ ヘッドの出力
$$
O^{(r)}\in\mathbb{R}^{n\times d_v}
$$
は、第 $r$ ヘッドが捉えた文脈情報を表す行列である。
各 head の出力を列ブロックとして横に並べると、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
\in
\mathbb{R}^{n\times hd_v}
$$
となる。
しかし、この段階では、各 head の出力を単に横に並べただけであり、各 head から得られた情報をどのように組み合わせるかはまだ学習されていない。
そこで、学習行列
$$
W^O\in\mathbb{R}^{hd_v\times d_{\mathrm{model}}}
$$
を右から掛けることで、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})W^O
\in
\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を得る。
この $W^O$ は、複数の head から得られた情報を混ぜ合わせ、Transformer の次の sub-layer や次の層で扱える $d_{\mathrm{model}}$ 次元の表現へ変換する役割をもつ。
言い換えると、$W^O$ は、各 head が別々に見つけた文脈情報を統合し、Multi-Head Attention 全体の出力表現を作るための学習される線形変換である。
$n,d_{\mathrm{model}},d_k,d_v,h\in\mathbb{N}_{>0}$ とする。
各 $r\in\{1,\ldots,h\}$ に対して、
$$
W_r^Q\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_r^K\in\mathbb{R}^{d_{\mathrm{model}}\times d_k},\quad
W_r^V\in\mathbb{R}^{d_{\mathrm{model}}\times d_v}
$$
とし、さらに
$$
W^O\in\mathbb{R}^{hd_v\times d_{\mathrm{model}}}
$$
とする。
入力表現
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
に対して、各 $r\in\{1,\ldots,h\}$ について、
$$
Q^{(r)}:=ZW_r^Q,\quad
K^{(r)}:=ZW_r^K,\quad
V^{(r)}:=ZW_r^V
$$
と定める。
さらに、各 $r\in\{1,\ldots,h\}$ に対して、
$$
O^{(r)}
:=
\operatorname{Attention}(Q^{(r)},K^{(r)},V^{(r)})
\in
\mathbb{R}^{n\times d_v}
$$
と定める。
このとき、写像
$$
\operatorname{MultiHead}_{\mathrm{enc}}:
\mathbb{R}^{n\times d_{\mathrm{model}}}
\to
\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を
$$
\operatorname{MultiHead}_{\mathrm{enc}}(Z)
:=
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})W^O
$$
によって定める。
この写像を、Encoder 側の Multi-Head Self-Attention という。
各 head の出力は
$$
O^{(r)}\in\mathbb{R}^{n\times d_v}
$$
である。
したがって、$h$ 個の head の出力を列ブロックとして横に並べると、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})
\in
\mathbb{R}^{n\times hd_v}
$$
となる。
一方、Transformer の各 sub-layer では residual connection を用いるため、sub-layer の入力と出力の次元をそろえる必要がある。
入力表現は
$$
Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
であるため、Multi-Head Attention の出力も
$$
\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
に属する形にする必要がある。
そこで、結合後の行列に
$$
W^O\in\mathbb{R}^{hd_v\times d_{\mathrm{model}}}
$$
を右からかけることで、
$$
\operatorname{Concat}(O^{(1)},\ldots,O^{(h)})W^O
\in
\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を得る。
この $W^O$ は、各 head から得られた情報を混ぜ合わせ、Transformer 内で用いる $d_{\mathrm{model}}$ 次元の表現へ変換するための学習行列である。
Single-head Self-Attention では、$1$ 組の Query、Key、Value から
$$
\operatorname{Attention}(Q,K,V)
$$
を $1$ 回だけ計算する。
一方、Multi-Head Self-Attention では、各 head ごとに異なる学習行列
$$
W_r^Q,\quad W_r^K,\quad W_r^V
$$
を用いて、複数の Self-Attention を並列に計算する。
すなわち、各 head は
$$
O^{(r)}
=
\operatorname{Attention}(Q^{(r)},K^{(r)},V^{(r)})
$$
を計算する。
その後、これらを列方向に結合し、最後に $W^O$ をかける。
この意味で、Multi-Head Self-Attention は、複数の Self-Attention head を束ねた attention sub-layer である。
原論文では Multi-Head Attention は
$$
\operatorname{MultiHead}(Q,K,V)
=
\operatorname{Concat}(\operatorname{head}_1,\ldots,\operatorname{head}_h)W^O
$$
と書かれている。
また、各 head は
$$
\operatorname{head}_r
=
\operatorname{Attention}(QW_r^Q,KW_r^K,VW_r^V)
$$
で定義される。
Encoder 側では、Query、Key、Value が同じ Encoder 側の系列表現から作られる。
したがって、本稿で定義した
$$
\operatorname{MultiHead}_{\mathrm{enc}}(Z)
$$
は、原論文の Encoder 側に現れる
$$
\text{Multi-Head Attention}
$$
に対応する。
参考文献


この記事を高評価した人
この記事に送られたバッジ
投稿者


