大規模言語モデルの数学的原理③ | Attention Is All You Need
前回(
詳しくはコチラ
)は、Encoder 側の Multi-Head Self-Attention
$$
\operatorname{MultiHead}_{\mathrm{enc}}(Z)
$$
を定義した。
これは、入力表現列 $Z\in\mathbb{R}^{n\times d_{\mathrm{model}}}$ の各位置の表現を、自分自身を含む入力列全体の文脈に応じて更新する sub-layer である。
しかし、原論文の Encoder layer は、Multi-Head Self-Attention sub-layer だけで構成されるわけではない(※1)。
原論文の Encoder layer は、次の $2$ つの sub-layer からなる。
- Multi-Head Self-Attention
- Position-wise Feed-Forward Network
-さらに、原論文では、それぞれの sub-layer のまわりに residual connection を置き、
その後に layer normalization を行う。
すなわち、sub-layer の入力を $x\in\mathbb{R}^{n\times d_{\mathrm{model}}}$ とし、sub-layer 自体が定める写像を $\operatorname{Sublayer}(x)\in\mathbb{R}^{n\times d_{\mathrm{model}}}$ と書くと、
各 sub-layer の出力は、基本形として
$$
\operatorname{LayerNorm}(x+\operatorname{Sublayer}(x))
$$
の形で与えられる(※2)。
したがって、Encoder layer 全体を定義するためには、次に
$$
\operatorname{FFN},\quad
\text{residual connection},\quad
\operatorname{LayerNorm},\quad
\operatorname{AddNorm}
$$
を定義する必要がある。
※1. これを聞いて『(タイトルに反して)必要なのは Attention だけじゃないやんけ('Д')』
と思った方のために言っておくと、
$$
\begin{align}
&\quad \text{Attention Is All You Need}\\
&\text{(必要なのは Attention だけである)}
\end{align}
$$
は Transformer が attention sub-layer だけで構成されるという意味で言っているわけではない。
原論文における主張は、従来の系列変換モデルでよく用いられていた再帰構造や畳み込み構造を使わず、
『attention mechanism を中心として系列変換モデルを構成できるよ(´・ω・`)om』
という意味である。
$ $
※2. ただし、原論文の training 時には、sub-layer の出力に dropout を適用してから
residual connection と layer normalization を行う。
本稿では、まず dropout を省略した基本形を扱うことにする。
Feed-Forward Network は一般的な用語であり、
入力から出力へ一方向に情報が流れるニューラルネットワークを広く指す。
$ $
一方、Transformer 原論文における Position-wise Feed-Forward Network は、
各位置の表現ベクトルに対して同じ Feed-Forward Network を独立に適用する sub-layer である。
$ $
したがって、本稿で単に
$$
\operatorname{FFN}
$$
と書く場合には、特に断らない限り、
Transformer の各層で用いられる Position-wise Feed-Forward Network を指すことにする。
本稿では、Feed-Forward Network の基本となる Neural Network の数学的な構成から始めよう。
その後、大規模言語モデルの数学的原理④にて Neural Network の学習を記述するために、
損失関数、勾配降下法、Backpropagation を定義する。
$ $
次に、深いネットワークを学習しやすくするための residual connection と、
表現を正規化して学習を安定させるための Layer Normalization を定義する。
さらに、これらを組み合わせた Add & Norm を定義する。
$ $
最後に、Transformer で用いられる Position-wise Feed-Forward Network を定義し、
Encoder layer と Encoder stack を構成する。という流れで進めていく。
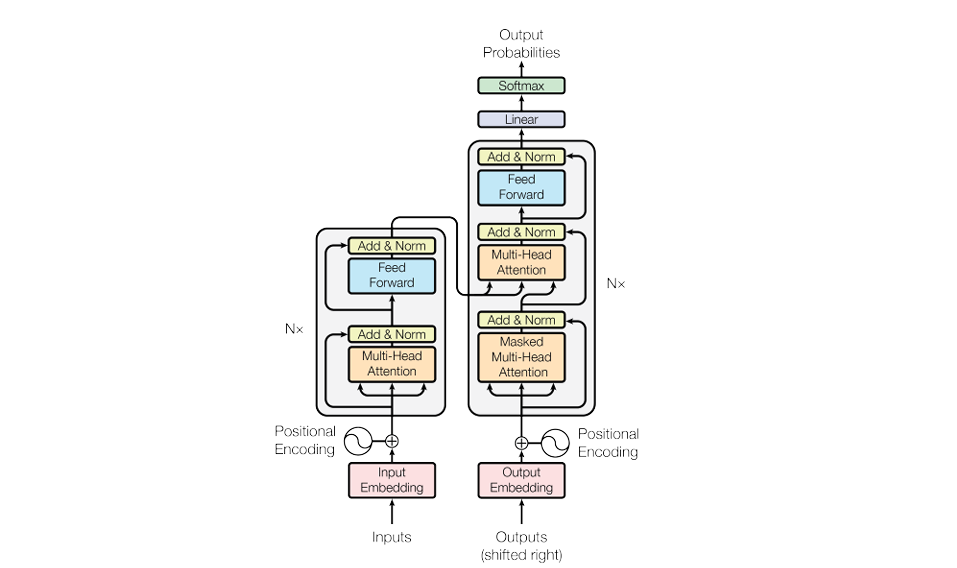 Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
Transformer Architecture (出典:Vaswani et al., "Attention Is All You Need," 2017)
AI の研究者ではないため(一応データサイエンティストではあるけど...)、
厳密な用語や実装上の詳細については原論文
Attention Is All You Need
を参照されたい。
Def.
$\text{Neural Network / Feed-Forward Network}$
$ $
$$
\begin{align}
&\text{Deep learning allows computational models that are composed of multiple processing layers}\\
&\text{to learn representations of data with multiple levels of abstraction.}\\
\end{align}
$$
$$
\begin{align}
&\text{(深層学習は、複数の処理層からなる計算モデルが、データの表現を複数の抽象度で学習できるようにする方法である。)}
\end{align}
$$
$$
\text{LeCun, Bengio, Hinton, Deep learning, Nature, 2015}
$$
$ $
Neural Network は、
重み、バイアス、活性化関数などをもつ計算単位を組み合わせて作られるモデル全般を指す広い用語である。
一方、Feed-Forward Network は、入力から出力へ向かって計算が一方向に進む Neural Network である。
典型的には、入力を
$$
\mathbf{h}^{(0)}:=\mathbf{x}
$$
とおき、各層の写像 $f_1,\ldots,f_L$ によって
$$
\mathbf{h}^{(\ell)}:=f_\ell(\mathbf{h}^{(\ell-1)})
\quad
(\ell=1,\ldots,L)
$$
と順に計算する。
このとき、全体の写像は
$$
F
=
f_L\circ f_{L-1}\circ\cdots\circ f_1
$$
で表される。
$ $
このように、入力から出力へ向かって層を順に合成して得られる Neural Network を Feed-Forward Network という。
したがって、Feed-Forward Network は Neural Network の一種である。
$ $
ただし、すべての Neural Network が Feed-Forward Network であるわけではない。
例えば、Recurrent Neural Network(RNN) のように、過去の状態や出力を次の計算に戻す構造をもつ Neural Network もある。
$d_{\mathrm{in}}\in\mathbb{N}_{>0}$ とする。
ニューラルネットワークの入力として扱う行ベクトル
$$
\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}
$$
を入力ベクトルという。ここで、$d_{\mathrm{in}}$ を入力次元という。
本稿では、Transformer の表記とそろえるため、ベクトルを行ベクトルとして扱う。
したがって、重み行列は右から掛ける。
自然言語処理では、文字列やトークンそのものを直接 $\mathbb{R}^{1\times d_{\mathrm{in}}}$ の元と見るのではなく、
埋め込みなどによって数値ベクトルに変換したものを入力ベクトルとして扱う。
$ $
Transformer では、各位置の表現ベクトルを行に並べた行列
$$
X\in\mathbb{R}^{n\times d_{\mathrm{model}}}
$$
を入力表現として扱う(
詳しくはコチラ
)。
このとき、各 $i\in\{1,\ldots,n\}$ に対して、第 $i$ 行
$$
\mathbf{x}_i:=X_{i,:}\in\mathbb{R}^{1\times d_{\mathrm{model}}}
$$
は第 $i$ 位置の入力ベクトルと見なせる。
$d_{\mathrm{in}},d_{\mathrm{out}}\in\mathbb{N}_{>0}$ とする。
入力ベクトルを
$$
\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}
$$
とする。
- 行列
$$ W\in\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}} $$
を重み行列という。 - また、行ベクトル
$$ \mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}} $$
をバイアス行ベクトルという。
学習過程で更新の対象となるものを学習パラメータという。
ニューラルネットワークにおいては、重み行列 $W$ とバイアス行ベクトル $\mathbf{b}$ は学習パラメータである。
$ $
無論、学習パラメータは、重み行列やバイアス行ベクトルに限られない。
例えば、Transformer における Query 変換行列、Key 変換行列、Value 変換行列
$$
W^Q,\quad W^K,\quad W^V
$$
や、出力変換行列
$$
W^O
$$
も学習パラメータである。
また、Layer Normalization におけるスケールパラメータとシフトパラメータも、学習パラメータとして扱われる。
重み行列 $W$ は、入力ベクトルの各成分をどのように組み合わせて出力側の各成分を作るかを定める。
バイアス行ベクトル $\mathbf{b}$ は、その出力に加えられる平行移動の成分を定める。
$ $
したがって、重み行列 $W$ とバイアス行ベクトル $\mathbf{b}$ を用いると、写像
$$
\mathbf{x}\mapsto \mathbf{x}W+\mathbf{b}
$$
が定まる。これは、ニューラルネットワークの層を定義する基本的な部品である。
$d_{\mathrm{in}},d_{\mathrm{out}}\in\mathbb{N}_{>0}$ とする。
重み行列
$$
W\in\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}}
$$
とバイアス行ベクトル
$$
\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
を固定する。
写像
$$
A_{W,\mathbf{b}}:\mathbb{R}^{1\times d_{\mathrm{in}}}\to\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
を、各 $\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ に対して
$$
A_{W,\mathbf{b}}(\mathbf{x})
:=
\mathbf{x}W+\mathbf{b}
$$
で定める。
この写像 $A_{W,\mathbf{b}}$ を、重み行列 $W$ とバイアス行ベクトル $\mathbf{b}$ によるアフィン写像という。
ここでは、
$$
\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}},\quad
W\in\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}},\quad
\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
である。
まず、$\mathbf{x}$ は $1$ 行 $d_{\mathrm{in}}$ 列の行ベクトルであり、$W$ は $d_{\mathrm{in}}$ 行 $d_{\mathrm{out}}$ 列の行列である。
したがって、$\mathbf{x}$ の列数と $W$ の行数がどちらも $d_{\mathrm{in}}$ で一致するので、行列積
$$
\mathbf{x}W
$$
は定義される。
また、行列積の型は
$$
(1\times d_{\mathrm{in}})(d_{\mathrm{in}}\times d_{\mathrm{out}})
=
1\times d_{\mathrm{out}}
$$
であるから、
$$
\mathbf{x}W\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
である。
さらに、
$$
\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
であるため、$\mathbf{x}W$ と $\mathbf{b}$ は同じ型の行ベクトルである。
したがって、成分ごとの和
$$
\mathbf{x}W+\mathbf{b}
$$
が定義され、
$$
\mathbf{x}W+\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
である。
$d_{\mathrm{in}},d_{\mathrm{out}}\in\mathbb{N}_{>0}$ とする。
また、
$$
W\in\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}},\quad
\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
とする。
- まず、写像
$$ L_W:\mathbb{R}^{1\times d_{\mathrm{in}}}\to\mathbb{R}^{1\times d_{\mathrm{out}}} $$
を、各 $\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ に対して
$$ L_W(\mathbf{x}):=\mathbf{x}W $$
で定める。
このとき、任意の $\mathbf{x},\mathbf{y}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ と任意の $\lambda,\mu\in\mathbb{R}$ に対して、
$$ \begin{align} L_W(\lambda\mathbf{x}+\mu\mathbf{y}) &= (\lambda\mathbf{x}+\mu\mathbf{y})W\\ &= \lambda\mathbf{x}W+\mu\mathbf{y}W\\ &= \lambda L_W(\mathbf{x})+\mu L_W(\mathbf{y}) \end{align} $$
である。
したがって、$L_W$ は線形写像である。
すなわち、バイアス $\mathbf{b}$ がない場合、写像
$$ \mathbf{x}\mapsto \mathbf{x}W $$
は線形写像である。
$ $ - 次に、写像
$$ A_{W,\mathbf{b}}:\mathbb{R}^{1\times d_{\mathrm{in}}}\to\mathbb{R}^{1\times d_{\mathrm{out}}} $$
を、各 $\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ に対して
$$ A_{W,\mathbf{b}}(\mathbf{x}):=\mathbf{x}W+\mathbf{b} $$
で定める。
この写像は、線形写像 $L_W$ と平行移動
$$ \mathbf{z}\mapsto \mathbf{z}+\mathbf{b} $$
の合成として表される。したがって、$A_{W,\mathbf{b}}$ はアフィン写像である。
$ $
一方、$\mathbf{b}\ne\mathbf{0}_{1\times d_{\mathrm{out}}}$ とする。
線形写像は零ベクトルを零ベクトルに写すので、もし $A_{W,\mathbf{b}}$ が線形写像ならば、
$$ A_{W,\mathbf{b}}(\mathbf{0}_{1\times d_{\mathrm{in}}}) = \mathbf{0}_{1\times d_{\mathrm{out}}} $$
でなければならない。
しかし、
$$ A_{W,\mathbf{b}}(\mathbf{0}_{1\times d_{\mathrm{in}}}) = \mathbf{0}_{1\times d_{\mathrm{in}}}W+\mathbf{b} = \mathbf{b} $$
である。
いま $\mathbf{b}\ne\mathbf{0}_{1\times d_{\mathrm{out}}}$ であるから、
$$ A_{W,\mathbf{b}}(\mathbf{0}_{1\times d_{\mathrm{in}}}) \ne \mathbf{0}_{1\times d_{\mathrm{out}}} $$
である。
したがって、$A_{W,\mathbf{b}}$ は線形写像ではない。
-以上より、バイアス $\mathbf{b}$ がない場合、写像
$$
\mathbf{x}\mapsto \mathbf{x}W
$$
は線形写像である。
一方、バイアス $\mathbf{b}$ が $\mathbf{0}$ でない場合、写像
$$
\mathbf{x}\mapsto \mathbf{x}W+\mathbf{b}
$$
は線形写像ではなく、アフィン写像である。
$m\in\mathbb{N}_{>0}$ とする。
- ニューラルネットワークにおいて、アフィン写像の出力に適用する実数値関数
$$ \sigma:\mathbb{R}\to\mathbb{R} $$
を、本稿では、スカラー値に対する活性化関数という。 - スカラー値に対する活性化関数
$$ \sigma:\mathbb{R}\to\mathbb{R} $$
を固定する。このとき、写像
$$ \sigma^{[m]}:\mathbb{R}^{1\times m}\to\mathbb{R}^{1\times m} $$
を、任意の行ベクトル
$$ \mathbf{u}=(u_1,\ldots,u_m)\in\mathbb{R}^{1\times m} $$
に対して
$$ \sigma^{[m]}(\mathbf{u}) := (\sigma(u_1),\ldots,\sigma(u_m)) $$
で定める。
活性化関数を用いる主な理由は、ニューラルネットワークに非線形性を導入するためである。
もし各層で用いる活性化関数が線形写像であるなら、各層はアフィン写像のままである。
さらに、線形な活性化関数だけでなく、アフィンな活性化関数だけを用いる場合にも、
各層はアフィン写像のままである。
$ $
また、アフィン写像の合成は再びアフィン写像である。
したがって、複数の層を重ねても、全体としては $1$ つのアフィン写像で表される。
このため、層をいくら深くしても、入力から出力への写像としては、
$1$ つのアフィン写像で表せる範囲を超えない。
$ $
特に、入力も出力も $1$ 次元の場合には、そのグラフは直線になる。
より一般に、入力が $\mathbb{R}^{1\times d}$ の元であり、
出力が $\mathbb{R}$ の元である場合、全体の写像がアフィン写像なら、そのグラフは $\mathbb{R}^{d+1}$ 内の超平面である。
$ $
このため、ニューラルネットワークでは、
$\mathbf{u}\in\mathbb{R}^{1\times m}$ に対して、非線形な活性化関数 $\sigma$ を用いて
$$
\mathbf{u}
\mapsto
\sigma^{[m]}(\mathbf{u})
$$
という操作を行うことにより、非線形な表現を獲得する。
特に、隠れ層では通常、ReLU などの非線形な活性化関数を用いる。
$ $
ただし、恒等関数のような線形関数も、出力層などでは活性化関数として扱われることがある。
したがって、非線形性を導入することは活性化関数を用いる主な目的であるが、活性化関数の定義そのものには含めない。
スカラー値に対する活性化関数には多くの種類がある。
以下では、代表的なものを列挙する(基本的かつ重要な関数は赤字にした)。
- 恒等関数
$$ \sigma(t):=t $$
恒等関数は、入力をそのまま返す関数である。出力層などで用いられることがある。
ただし、隠れ層の活性化関数がすべて恒等関数である場合、複数の層を合成しても全体としてはアフィン写像にしかならない。
$ $ - ステップ関数
$$ \sigma(t):= \begin{cases} 0 & (t<0)\\ 1 & (t\ge 0) \end{cases} $$
ステップ関数は、古典的なパーセプトロンの説明で用いられることがある。
ただし、$t=0$ 付近で不連続であり、勾配に基づく学習には扱いにくい。
$ $ - 符号関数
$$ \sigma(t):= \begin{cases} -1 & (t<0)\\ 0 & (t=0)\\ 1 & (t>0) \end{cases} $$
符号関数は、入力の符号だけを返す関数である。
ただし、通常の深層学習における隠れ層の活性化関数としてはあまり用いられない。
$ $ - Sigmoid 関数
$$ \sigma(t):=\frac{1}{1+\exp(-t)} $$
Sigmoid 関数は、実数を $0$ と $1$ の間の値へ写す関数である。
$ $ - 双曲線正接関数$\tanh$
$$ \sigma(t):=\tanh(t) $$
双曲線正接関数は、実数を $-1$ と $1$ の間の値へ写す関数である。
$ $ - Arctan 関数
$$ \sigma(t):=\arctan(t) $$
Arctan 関数は、実数を有界な範囲へ写す滑らかな関数である。
$ $ - Softsign 関数
$$ \sigma(t):=\frac{t}{1+|t|} $$
Softsign 関数は、Sigmoid 関数や $\tanh$ 関数と同じく、有界な値を返す活性化関数の一種である。
$ $ - ReLU【特に重要】
$$ \operatorname{ReLU}(t):=\max\{0,t\} $$
ReLU は、現在よく用いられる代表的な活性化関数である。
$t<0$ では $0$ を返し、$t\ge 0$ では $t$ を返す。
$ $ - Leaky ReLU
$\alpha>0$ とする。
$$ \sigma(t):= \begin{cases} \alpha t & (t<0)\\ t & (t\ge 0) \end{cases} $$
Leaky ReLU は、ReLU の負の側にも小さな傾きを持たせた関数である。
$ $ - Parametric ReLU
$\alpha$ を学習パラメータとする。
$$ \sigma(t):= \begin{cases} \alpha t & (t<0)\\ t & (t\ge 0) \end{cases} $$
Parametric ReLU は、Leaky ReLU の負の側の傾き $\alpha$ を学習によって調整する活性化関数である。
$ $ - Randomized Leaky ReLU
$\alpha$ をある範囲からランダムに選ぶ係数とする。
$$ \sigma(t):= \begin{cases} \alpha t & (t<0)\\ t & (t\ge 0) \end{cases} $$
Randomized Leaky ReLU は、負の側の傾きを確率的に変える ReLU 系の活性化関数である。
$ $ - ReLU6
$$ \sigma(t):=\min\{\max\{0,t\},6\} $$
ReLU6 は、ReLU の出力を上から $6$ で打ち切る関数である。
$ $ - Thresholded ReLU
$\theta\in\mathbb{R}$ とする。
$$ \sigma(t):= \begin{cases} t & (t>\theta)\\ 0 & (t\le \theta) \end{cases} $$
Thresholded ReLU は、しきい値 $\theta$ 以下の入力を $0$ にする関数である。
$ $ - HardTanh
$$ \sigma(t):= \begin{cases} -1 & (t<-1)\\ t & (-1\le t\le 1)\\ 1 & (t>1) \end{cases} $$
HardTanh は、$\tanh$ 関数を区分線形的に近似したような関数である。
$ $ - Softplus
$$ \sigma(t):=\log(1+\exp(t)) $$
Softplus は、ReLU を滑らかにしたような関数である。
$ $ - ELU
$\alpha>0$ とする。
$$ \sigma(t):= \begin{cases} t & (t>0)\\ \alpha(\exp(t)-1) & (t\le 0) \end{cases} $$
ELU は、負の入力に対して指数関数を用いる活性化関数である。
$ $ - CELU
$\alpha>0$ とする。
$$ \sigma(t):= \begin{cases} t & (t>0)\\ \alpha\left(\exp\left(\frac{t}{\alpha}\right)-1\right) & (t\le 0) \end{cases} $$
CELU は、ELU の変種であり、$\alpha$ に応じて指数部分を調整することで、
$t=0$ における微分可能性を保つように定められた活性化関数である。
$ $ - SELU
定数 $\lambda>0$、$\alpha>0$ を標準的な SELU の定数とする。
$$ \sigma(t) := \lambda \begin{cases} t & (t>0)\\ \alpha(\exp(t)-1) & (t\le 0) \end{cases} $$
SELU は、ELU に特定のスケール係数 $\lambda$ を加えた活性化関数である。
$ $ - GELU
$$ \sigma(t):=t\Phi(t) $$
ここで、$\Phi$ は標準正規分布の分布関数である。
GELU は、Transformer 系のモデルでもよく用いられる活性化関数である。
近似式として
$$ \sigma(t)\approx \frac{1}{2}t \left( 1+\tanh\left( \sqrt{\frac{2}{\pi}} \left(t+0.044715t^3\right) \right) \right) $$
が用いられることもある。
$ $ - SiLU
$$ \sigma(t):=t\cdot \frac{1}{1+\exp(-t)} $$
SiLU は、入力 $t$ と Sigmoid 関数の値を掛け合わせた活性化関数である。
Swish とも呼ばれることがある。
$ $ - Swish
$\beta\in\mathbb{R}$ とする。
$$ \sigma(t):=t\cdot \frac{1}{1+\exp(-\beta t)} $$
Swish は、SiLU をパラメータ $\beta$ で一般化した活性化関数と見なせる。
$\beta=1$ の場合、SiLU と一致する。
$ $ - Hard SiLU
$$ \sigma(t):=t\cdot \frac{\min\{\max\{t+3,0\},6\}}{6} $$
Hard SiLU は、SiLU を計算しやすい区分線形関数で近似したものである。
Hard Swish とも呼ばれる。
$ $ - Mish
$$ \sigma(t):=t\tanh(\log(1+\exp(t))) $$
Mish は、Softplus と $\tanh$ を組み合わせた滑らかな活性化関数である。
$ $ - Exponential 関数
$$ \sigma(t):=\exp(t) $$
Exponential 関数を活性化関数として用いることもある。
ただし、出力が急速に大きくなるため、用途は限定される。
ベクトル値に対する活性化関数には多くの種類がある。
以下では、代表的なものを列挙する(基本的かつ重要な関数は赤字にした)。
- Softmax 関数【重要】
$m\in\mathbb{N}_{>0}$ とする。
$\mathbf{u}=(u_1,\ldots,u_m)\in\mathbb{R}^{1\times m}$ に対して、
$$ \operatorname{softmax}(\mathbf{u})_j := \frac{\exp(u_j)} {\sum_{\ell=1}^{m}\exp(u_\ell)} \quad (j\in\{1,\ldots,m\}) $$
と定める。
Softmax 関数は、実数値ベクトルを正の成分をもつ確率ベクトルへ変換する関数である。
分類問題の出力層や attention weight の計算で用いられる。
$ $ - LogSoftmax 関数
$m\in\mathbb{N}_{>0}$ とする。
$\mathbf{u}=(u_1,\ldots,u_m)\in\mathbb{R}^{1\times m}$ に対して、
$$ \operatorname{LogSoftmax}(\mathbf{u})_j := \log \left( \frac{\exp(u_j)} {\sum_{\ell=1}^{m}\exp(u_\ell)} \right) $$
と定める。
LogSoftmax 関数は、Softmax の対数を返す関数である。
$ $ - Gated Linear Unit
$m\in\mathbb{N}_{>0}$ とする。
$\mathbf{a},\mathbf{b}\in\mathbb{R}^{1\times m}$ に対して、
$$ \operatorname{GLU}(\mathbf{a},\mathbf{b}) := \mathbf{a}\odot \operatorname{sigmoid}^{[m]}(\mathbf{b}) $$
と定める。
ここで、$\odot$ は成分ごとの積である(いわゆるアダマール積ってやつ(*´Д`))。
GLU は、入力の一部を gate として用いる活性化関数である。
$ $ - Maxout
$k\in\mathbb{N}_{>0}$ とする。関数
$$ a_1,\ldots,a_k:\mathbb{R}^{1\times d}\to\mathbb{R} $$
をアフィン関数とする。
このとき、
$$ \sigma(\mathbf{x}) := \max_{r\in\{1,\ldots,k\}} a_r(\mathbf{x}) $$
の形で定まる関数を Maxout という。
Maxout は、複数のアフィン関数の最大値を出力する活性化の一種である。
(厳密には「ベクトル値に対する活性化関数」ではなく「ベクトル入力をもつスカラー値関数」である)。
上のうち、Sigmoid、$\tanh$、ReLU、Leaky ReLU、Softplus、ELU、GELU、SiLU、Mish などは、
実数から実数への関数
$$
\sigma:\mathbb{R}\to\mathbb{R}
$$
として定義できる。
このような関数は、任意の $m\in\mathbb{N}_{>0}$ に対して、成分ごとの拡張
$$
\sigma^{[m]}:\mathbb{R}^{1\times m}\to\mathbb{R}^{1\times m}
$$
を定める。
一方、Softmax、LogSoftmax、GLU、Maxout などは、単純に同じ関数を各成分へ独立に適用する写像ではない。
したがって、本稿で「成分ごとに適用する活性化関数」という場合には、主に
$$
\sigma:\mathbb{R}\to\mathbb{R}
$$
として定義できる活性化関数を指す。
以下に記す Sigmoid 関数と深層学習の歴史は重要なので、知っておくと良い('Д')。
- Sigmoid 関数は、古典的なニューラルネットワークでよく用いられてきた活性化関数である。
Sigmoid 関数は、各 $t\in\mathbb{R}$ に対して
$$ \operatorname{sigmoid}(t) := \frac{1}{1+\exp(-t)} $$
で定義される。この関数は、任意の実数を $0$ と $1$ の間の値へ写す。
すなわち、
$$ 0<\operatorname{sigmoid}(t)<1 $$
である。
そのため、Sigmoid 関数の出力は、ニューロンがどの程度発火しているかを表す量や、
$2$ 値分類における確率のような量として解釈しやすい。
$ $
歴史的には、初期のニューラルネットワークでは、
ステップ関数のようなしきい値関数が用いられることがあった。
しかし、ステップ関数は不連続であり、通常の意味で微分できない点をもつため、(微分を使う)勾配に基づく学習とは相性がよくない。
$ $
一方、Sigmoid 関数は滑らかで微分可能である。
実際、
$$ \operatorname{sigmoid}'(t) = \operatorname{sigmoid}(t) \left( 1-\operatorname{sigmoid}(t) \right) $$
が成り立つ。
この性質により、Sigmoid 関数は誤差逆伝播法と組み合わせやすく、古典的な多層ニューラルネットワークで広く用いられた。
$ $ - しかし、深いネットワークを学習する場合、Sigmoid 関数には重要な問題がある。
$t$ が大きな正の値または大きな負の値になると、Sigmoid 関数の値はそれぞれ $1$ または $0$ に限りなく近づく。
このとき、微分係数
$$ \operatorname{sigmoid}'(t) = \operatorname{sigmoid}(t) \left( 1-\operatorname{sigmoid}(t) \right) $$
は $0$ に近づく。
したがって、誤差逆伝播法で勾配を後ろの層から前の層へ伝えるとき、
Sigmoid 関数の微分係数が何度も掛け合わされると、勾配が非常に小さくなりやすい。
この現象は 勾配消失 と呼ばれる。
$ $
また、Sigmoid 関数の出力は常に正であり、値域は
$$ (0,1) $$
である。そのため、出力が $0$ を中心としていない。
このことも、勾配降下法による最適化を扱いにくくする要因の $1$ つである。
この点では、値域が
$$ (-1,1) $$
である $\tanh$ 関数 の方が、隠れ層の活性化関数としては扱いやすい場合がある。
$ $ - その後、深層学習では ReLU が広く用いられるようになった。
ReLU は、各 $t\in\mathbb{R}$ に対して
$$ \operatorname{ReLU}(t) := \max\{0,t\} $$
で定義される。
ReLU は $t>0$ の範囲で微分係数が $1$ であるため、Sigmoid 関数のように正の側で飽和しない。
このため、深いネットワークでは、Sigmoid 関数よりも ReLU の方が学習しやすいことが多い。
-以上をまとめると、Sigmoid 関数は、微分可能で確率的解釈もしやすい活性化関数として、
古典的なニューラルネットワークで重要な役割を果たした。
$ $
しかし、深いネットワークでは飽和による勾配消失が問題になりやすいため、
現在の隠れ層では ReLU やその変種が用いられることが多い。
$ $
一方で、Sigmoid 関数が不要になったわけではない。
現在でも、$2$ 値分類の出力層や、ゲート構造をもつニューラルネットワークでは、Sigmoid 関数が用いられることがある。
Sigmoid 関数は、各 $t\in\mathbb{R}$ に対して
$$
\operatorname{sigmoid}(t)
=
\frac{1}{1+\exp(-t)}
$$
で定義される。
一方、$m\in\mathbb{N}_{>0}$ に対して、Softmax 関数は
$$
\operatorname{softmax}:\mathbb{R}^{1\times m}\to\mathbb{R}^{1\times m}
$$
であり、各
$$
\mathbf{z}=(z_1,\ldots,z_m)\in\mathbb{R}^{1\times m}
$$
に対して
$$
\operatorname{softmax}(\mathbf{z})_j
:=
\frac{\exp(z_j)}{\sum_{k=1}^{m}\exp(z_k)}
$$
で定義される。
Softmax 関数は、複数の実数値スコアを、和が $1$ である正のベクトルへ変換する関数である。
そのため、多クラス分類の出力層や、attention weight の計算で用いられる。
$ $
Sigmoid 関数と Softmax 関数は別々の関数であるが、$2$ クラスの場合には密接な関係がある。
- 実際、$t\in\mathbb{R}$ に対して、$2$ 次元ベクトル
$$ (t,0)\in\mathbb{R}^{1\times 2} $$
を考える。
このとき、
$$ \operatorname{softmax}(t,0)_1 = \frac{\exp(t)}{\exp(t)+\exp(0)} = \frac{\exp(t)}{\exp(t)+1} $$
である。
さらに、分子分母を $\exp(t)$ で割ると、
$$ \operatorname{softmax}(t,0)_1 = \frac{1}{1+\exp(-t)} = \operatorname{sigmoid}(t) $$
となる。
また、第 $2$ 成分は
$$ \operatorname{softmax}(t,0)_2 = \frac{1}{\exp(t)+1} = 1-\operatorname{sigmoid}(t) $$
である。
したがって、
$$ \operatorname{softmax}(t,0) = \left( \operatorname{sigmoid}(t), 1-\operatorname{sigmoid}(t) \right) $$
が成り立つ。
この意味で、Sigmoid 関数は $2$ クラス Softmax の特殊な場合と見ることができる。
$ $ - より一般に、$2$ つのスコア $a,b\in\mathbb{R}$ に対して、
$$ \operatorname{softmax}(a,b)_1 = \frac{\exp(a)}{\exp(a)+\exp(b)} $$
である。
分子分母を $\exp(a)$ で割ると、
$$ \operatorname{softmax}(a,b)_1 = \frac{1}{1+\exp(b-a)} = \frac{1}{1+\exp(-(a-b))} = \operatorname{sigmoid}(a-b) $$
となる。
したがって、$2$ クラス Softmax の第 $1$ 成分は、$2$ つのスコアの差 $a-b$ に Sigmoid 関数を適用したものと一致する。
同様に、
$$ \operatorname{softmax}(a,b)_2 = \operatorname{sigmoid}(b-a) = 1-\operatorname{sigmoid}(a-b) $$
である。
$ $
-このように、$2$ クラス分類では、出力を $1$ 個のスコア $t$ として
$$
\operatorname{sigmoid}(t)
$$
を用いる書き方と、出力を $2$ 個のスコア $(a,b)$ として
$$
\operatorname{softmax}(a,b)
$$
を用いる書き方は、数学的に対応している。
$ $
ただし、Softmax は出力成分全体を正規化して、成分の和が $1$ になるようにする関数である。
一方、Sigmoid は各実数を独立に $0$ と $1$ の間へ写す関数である。
$ $
したがって、多クラス分類で「ちょうど $1$ つのクラスが正しい」と仮定する場合には Softmax が自然である。
一方、複数のラベルが同時に正しくなり得る多ラベル分類では、各ラベルごとに Sigmoid 関数を適用することがある。
$d_{\mathrm{in}}\in\mathbb{N}_{>0}$ とする。
重み列ベクトル
$$
\mathbf{w}\in\mathbb{R}^{d_{\mathrm{in}}\times 1}
$$
とバイアス
$$
b\in\mathbb{R}
$$
と活性化関数
$$
\sigma:\mathbb{R}\to\mathbb{R}
$$
を固定する。
写像
$$
\nu:\mathbb{R}^{1\times d_{\mathrm{in}}}\to\mathbb{R}
$$
を、各 $\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ に対して
$$
\nu(\mathbf{x})
:=
\sigma(\mathbf{x}\mathbf{w}+b)
$$
で定める。ただし、$\mathbf{x}\mathbf{w}\in\mathbb{R}^{1\times 1}$ は、その唯一の成分によって実数と同一視する。
この写像 $\nu$ を、$1$ つのニューロンまたはユニットという。
定義より、ニューロンは入力ベクトル
$$
\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}
$$
に対して、重み列ベクトル
$$
\mathbf{w}\in\mathbb{R}^{d_{\mathrm{in}}\times 1}
$$
との積を取り、バイアス
$$
b\in\mathbb{R}
$$
を加えた後、活性化関数
$$
\sigma:\mathbb{R}\to\mathbb{R}
$$
を適用する写像である。
$ $
入力ベクトルと重み列ベクトルを成分表示して、
$$
\mathbf{x}
=
(x_1,\ldots,x_{d_{\mathrm{in}}})
\in\mathbb{R}^{1\times d_{\mathrm{in}}}
$$
$$
\mathbf{w}
=
\begin{pmatrix}
w_1\\
\vdots\\
w_{d_{\mathrm{in}}}
\end{pmatrix}
\in\mathbb{R}^{d_{\mathrm{in}}\times 1}
$$
と書く。
このとき、
$$
\mathbf{x}\mathbf{w}
=
(x_1,\ldots,x_{d_{\mathrm{in}}})
\begin{pmatrix}
w_1\\
\vdots\\
w_{d_{\mathrm{in}}}
\end{pmatrix}
=
\sum_{j=1}^{d_{\mathrm{in}}}x_jw_j
$$
である。
したがって、ニューロンの出力は
$$
\nu(\mathbf{x})
=
\sigma
\left(
\sum_{j=1}^{d_{\mathrm{in}}}x_jw_j+b
\right)
$$
である。
つまり、ニューロンは、入力の各成分 $x_j$ に対応する重み $w_j$ を掛け、
それらを足し合わせ、バイアス $b$ を加えた値に活性化関数 $\sigma$ を適用する。
例えば、
$$
d_{\mathrm{in}}=3
$$
とし、入力ベクトルを
$$
\mathbf{x}=(2,-1,3)\in\mathbb{R}^{1\times 3}
$$
とする。
また、重み列ベクトルとバイアスを
$$
\mathbf{w}
=
\begin{pmatrix}
1\\
2\\
-1
\end{pmatrix}
\in\mathbb{R}^{3\times 1},
\quad
b=4
$$
とする。
活性化関数として ReLU
$$
\operatorname{ReLU}(t)=\max\{0,t\}
$$
を用いる。
このとき、まずアフィン写像部分は
$$
\begin{align}
\mathbf{x}\mathbf{w}+b
&=
(2,-1,3)
\begin{pmatrix}
1\\
2\\
-1
\end{pmatrix}
+4
\\
&=
2\cdot 1+(-1)\cdot 2+3\cdot(-1)+4
\\
&=
2-2-3+4
\\
&=
1
\end{align}
$$
である。
したがって、ニューロンの出力は
$$
\begin{align}
\nu(\mathbf{x})
&=
\operatorname{ReLU}(\mathbf{x}\mathbf{w}+b)
\\
&=
\operatorname{ReLU}(1)
\\
&=
1
\end{align}
$$
である。
この例では、入力ベクトル $\mathbf{x}$ に対して、重み付き和とバイアスを計算した値が $1$ であり、
それに ReLU を適用しても $1$ のままである。
複数のニューロンを横に並べると、出力は行ベクトルになる。
$m\in\mathbb{N}_{>0}$ とし、各 $k\in\{1,\ldots,m\}$ に対して、第 $k$ ニューロンの重み列ベクトルを
$$
\mathbf{w}_k\in\mathbb{R}^{d_{\mathrm{in}}\times 1}
$$
とし、バイアスを
$$
b_k\in\mathbb{R}
$$
とする。
これらを列として並べて
$$
W:=
\begin{pmatrix}
\mathbf{w}_1 & \cdots & \mathbf{w}_m
\end{pmatrix}
\in\mathbb{R}^{d_{\mathrm{in}}\times m}
$$
と定め、また
$$
\mathbf{b}:=(b_1,\ldots,b_m)\in\mathbb{R}^{1\times m}
$$
と定める。
このとき、複数のニューロンをまとめた写像は
$$
\mathbf{x}
\mapsto
\sigma^{[m]}(\mathbf{x}W+\mathbf{b})
$$
という形で書ける。
ここで、$\sigma^{[m]}$ は、スカラー値に対する活性化関数 $\sigma$ を行ベクトルの各成分に適用する写像である。
$d_{\mathrm{in}},d_{\mathrm{out}}\in\mathbb{N}_{>0}$ とする。
重み行列
$$
W\in\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}}
$$
とバイアス行ベクトル
$$
\mathbf{b}\in\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
と活性化関数
$$
\sigma:\mathbb{R}\to\mathbb{R}
$$
を固定する。
また、$\sigma$ の成分ごとの拡張
$$
\sigma^{[d_{\mathrm{out}}]}:\mathbb{R}^{1\times d_{\mathrm{out}}}\to\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
を考える。
写像
$$
L_{W,\mathbf{b},\sigma}:
\mathbb{R}^{1\times d_{\mathrm{in}}}
\to
\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
を、各 $\mathbf{x}\in\mathbb{R}^{1\times d_{\mathrm{in}}}$ に対して
$$
L_{W,\mathbf{b},\sigma}(\mathbf{x})
:=
\sigma^{[d_{\mathrm{out}}]}(\mathbf{x}W+\mathbf{b})
$$
で定める。
この写像 $L_{W,\mathbf{b},\sigma}$ を、重み行列 $W$、バイアス行ベクトル $\mathbf{b}$、活性化関数 $\sigma$ による全結合層という。
出力層などでは、活性化関数を明示的に入れず、
$$
L_{W,\mathbf{b}}(\mathbf{x})=\mathbf{x}W+\mathbf{b}
$$
とすることもある。
この場合は、恒等関数
$$
\operatorname{id}_{\mathbb{R}}(t):=t
$$
を活性化関数として用いていると見なせる。
全結合層は、複数のニューロンを横に並べたものと見なせる。
入力ベクトルを
$$
\mathbf{x}
=
(x_1,\ldots,x_{d_{\mathrm{in}}})
\in\mathbb{R}^{1\times d_{\mathrm{in}}}
$$
とする。
また、重み行列を成分表示して
$$
W
=
(w_{i,j})
\in
\mathbb{R}^{d_{\mathrm{in}}\times d_{\mathrm{out}}}
$$
とし、バイアス行ベクトルを
$$
\mathbf{b}
=
(b_1,\ldots,b_{d_{\mathrm{out}}})
\in
\mathbb{R}^{1\times d_{\mathrm{out}}}
$$
とする。
このとき、まずアフィン写像部分
$$
\mathbf{x}W+\mathbf{b}
$$
を計算する。
$\mathbf{x}W$ の第 $j$ 成分は、各 $j\in\{1,\ldots,d_{\mathrm{out}}\}$ に対して
$$
(\mathbf{x}W)_j
=
\sum_{i=1}^{d_{\mathrm{in}}}x_iw_{i,j}
$$
である。
したがって、
$$
(\mathbf{x}W+\mathbf{b})_j
=
\sum_{i=1}^{d_{\mathrm{in}}}x_iw_{i,j}+b_j
$$
である。
よって、全結合層の出力
$$
L_{W,\mathbf{b},\sigma}(\mathbf{x})
=
\sigma^{[d_{\mathrm{out}}]}(\mathbf{x}W+\mathbf{b})
$$
の第 $j$ 成分は
$$
\left(L_{W,\mathbf{b},\sigma}(\mathbf{x})\right)_j
=
\sigma
\left(
\sum_{i=1}^{d_{\mathrm{in}}}x_iw_{i,j}+b_j
\right)
$$
である。
つまり、第 $j$ 出力成分は、入力成分
$$
x_1,\ldots,x_{d_{\mathrm{in}}}
$$
を重み
$$
w_{1,j},\ldots,w_{d_{\mathrm{in}},j}
$$
によって重み付き和し、バイアス $b_j$ を加え、その値に活性化関数 $\sigma$ を適用したものである。
この意味で、全結合層では、各出力ユニットがすべての入力成分と結合している。
$L\in\mathbb{N}_{>0}$ とする。$d_0,d_1,\ldots,d_L\in\mathbb{N}_{>0}$ とする。
各 $\ell\in\{1,\ldots,L\}$ に対して、重み行列とバイアス行ベクトルを
$$
W_\ell\in\mathbb{R}^{d_{\ell-1}\times d_\ell},
\quad
\mathbf{b}_\ell\in\mathbb{R}^{1\times d_\ell}
$$
とする。
また、各 $\ell\in\{1,\ldots,L\}$ に対して、活性化関数を
$$
\sigma_\ell:\mathbb{R}\to\mathbb{R}
$$
とし、その成分ごとの拡張を
$$
\sigma_\ell^{[d_\ell]}:\mathbb{R}^{1\times d_\ell}\to\mathbb{R}^{1\times d_\ell}
$$
とする。
- 入力を
$$ \mathbf{h}^{(0)}:=\mathbf{x}\in\mathbb{R}^{1\times d_0} $$
とし、各 $\ell\in\{1,\ldots,L\}$ に対して
$$ \mathbf{a}^{(\ell)} := \mathbf{h}^{(\ell-1)}W_\ell+\mathbf{b}_\ell \in\mathbb{R}^{1\times d_\ell} $$
$$ \mathbf{h}^{(\ell)} := \sigma_\ell^{[d_\ell]}(\mathbf{a}^{(\ell)}) \in\mathbb{R}^{1\times d_\ell} $$
と再帰的に定める。 - このとき、写像
$$ f_\theta:\mathbb{R}^{1\times d_0}\to\mathbb{R}^{1\times d_L} $$
を
$$ f_\theta(\mathbf{x}) := \mathbf{h}^{(L)} $$
で定める。この写像 $f_\theta$ を、深さ $L$ の Feed-Forward Network という。 - ここで、
$$ \theta:=((W_\ell,\mathbf{b}_\ell))_{\ell=1}^{L} $$
を、この Feed-Forward Network の学習パラメータ族という。
Feed-Forward Network では、計算が
$$
\mathbf{h}^{(0)}
\to
\mathbf{h}^{(1)}
\to
\cdots
\to
\mathbf{h}^{(L)}
$$
のように入力側から出力側へ一方向に進む。
この意味で feed-forward という。
上の定義では、各層の活性化関数
$$
\sigma_\ell:\mathbb{R}\to\mathbb{R}
$$
は、あらかじめ固定された関数であると考えている。
この場合、学習によって更新される対象は、各層の重み行列
$$
W_\ell\in\mathbb{R}^{d_{\ell-1}\times d_\ell}
$$
とバイアス行ベクトル
$$
\mathbf{b}_\ell\in\mathbb{R}^{1\times d_\ell}
$$
である。
したがって、この場合には、学習パラメータ族を
$$
\theta:=((W_\ell,\mathbf{b}_\ell))_{\ell=1}^{L}
$$
と書いてよい。
$ $
ただし、活性化関数そのものが学習によって更新されるパラメータを含む場合には、
そのパラメータも学習パラメータ族に含める必要がある。
$ $
例えば、第 $\ell$ 層の活性化関数として Parametric ReLU
$$
\sigma_{\alpha_\ell}(t)
:=
\begin{cases}
\alpha_\ell t & (t<0)\\
t & (t\ge 0)
\end{cases}
$$
を用い、$\alpha_\ell$ も学習によって更新する場合には、$\alpha_\ell$ も学習パラメータである。
このとき、学習パラメータ族は、例えば
$$
\theta:=((W_\ell,\mathbf{b}_\ell,\alpha_\ell))_{\ell=1}^{L}
$$
のように書く。
つまり、$\theta$ は単に重み行列とバイアス行ベクトルだけを表す記号ではなく、
そのモデルにおいて学習によって更新されるすべてのパラメータをまとめた記号である。
$ $
本稿では、特に断らない限り、活性化関数は固定されているものとし、
$$
\theta:=((W_\ell,\mathbf{b}_\ell))_{\ell=1}^{L}
$$
と書くことにする。
例えば、
$$
L=2,\quad d_0=2,\quad d_1=3,\quad d_2=1
$$
とする。
このとき、入力は $2$ 次元の行ベクトルであり、第 $1$ 層の出力は $3$ 次元の行ベクトル、第 $2$ 層の出力は $1$ 次元の行ベクトルである。
入力を
$$
\mathbf{x}=(1,2)\in\mathbb{R}^{1\times 2}
$$
とする。
また、第 $1$ 層の重み行列とバイアス行ベクトルを
$$
W_1
=
\begin{pmatrix}
1 & 0 & -1\\
2 & 1 & 1
\end{pmatrix}
\in\mathbb{R}^{2\times 3}
$$
$$
\mathbf{b}_1=(0,1,-2)\in\mathbb{R}^{1\times 3}
$$
とする。
第 $2$ 層の重み行列とバイアス行ベクトルを
$$
W_2
=
\begin{pmatrix}
1\\
-1\\
2
\end{pmatrix}
\in\mathbb{R}^{3\times 1}
$$
$$
\mathbf{b}_2=(1)\in\mathbb{R}^{1\times 1}
$$
とする。
活性化関数として、第 $1$ 層では ReLU
$$
\sigma_1(t):=\operatorname{ReLU}(t)=\max\{0,t\}
$$
を用い、第 $2$ 層では恒等関数
$$
\sigma_2(t):=t
$$
を用いる。
$ $
- まず、
$$ \mathbf{h}^{(0)}:=\mathbf{x}=(1,2) $$
である。
$ $ - 第 $1$ 層のアフィン写像部分は
$$ \begin{align} \mathbf{a}^{(1)} &= \mathbf{h}^{(0)}W_1+\mathbf{b}_1 \\ &= (1,2) \begin{pmatrix} 1 & 0 & -1\\ 2 & 1 & 1 \end{pmatrix} + (0,1,-2) \\ &= (1\cdot 1+2\cdot 2,\quad 1\cdot 0+2\cdot 1,\quad 1\cdot(-1)+2\cdot 1) + (0,1,-2) \\ &= (5,2,1)+(0,1,-2) \\ &= (5,3,-1) \end{align} $$
である。
したがって、第 $1$ 層の出力は
$$ \begin{align} \mathbf{h}^{(1)} &= \sigma_1(\mathbf{a}^{(1)}) \\ &= \operatorname{ReLU}(5,3,-1) \\ &= (5,3,0) \end{align} $$
である。
$ $ - 次に、第 $2$ 層のアフィン写像部分は
$$ \begin{align} \mathbf{a}^{(2)} &= \mathbf{h}^{(1)}W_2+\mathbf{b}_2 \\ &= (5,3,0) \begin{pmatrix} 1\\ -1\\ 2 \end{pmatrix} + (1) \\ &= (5\cdot 1+3\cdot(-1)+0\cdot 2)+(1) \\ &= (2)+(1) \\ &= (3) \end{align} $$
である。
第 $2$ 層の活性化関数は恒等関数であるから、
$$ \begin{align} \mathbf{h}^{(2)} &= \sigma_2^{[1]}(\mathbf{a}^{(2)}) \\ &= \sigma_2^{[1]}((3)) \\ &= (3) \end{align} $$
である。
$ $ - ゆえに、この Feed-Forward Network の出力は
$$ f_\theta(\mathbf{x}) = \mathbf{h}^{(2)} = (3) $$
である。
-このように、Feed-Forward Network では、第 $1$ 層で得られた出力
$$
\mathbf{h}^{(1)}
$$
が第 $2$ 層の入力として用いられる。
つまり、計算は
$$
\mathbf{h}^{(0)}
\to
\mathbf{h}^{(1)}
\to
\mathbf{h}^{(2)}
$$
のように、入力側から出力側へ一方向に進む。
$L\in\mathbb{N}_{>0}$ とする。$d_0,d_1,\ldots,d_L\in\mathbb{N}_{>0}$ とする。
本稿では、入力
$$
\mathbb{R}^{1\times d_0}
$$
そのものは層として数えず、各 $\ell\in\{1,\ldots,L\}$ に対して、写像
$$
L_\ell:\mathbb{R}^{1\times d_{\ell-1}}\to\mathbb{R}^{1\times d_\ell}
$$
を層とする。
Feed-Forward Network
$$
f_\theta:\mathbb{R}^{1\times d_0}\to\mathbb{R}^{1\times d_L}
$$
が
$$
f_\theta
=
L_L\circ L_{L-1}\circ\cdots\circ L_1
$$
で表されているとする。
- このとき、最後の層
$$ L_L $$
を出力層という。 - また、$L\ge 2$ のとき、
$$ L_1,\ldots,L_{L-1} $$
を隠れ層または中間層という。 - $L=1$ のとき、この Feed-Forward Network は隠れ層をもたない。
回帰問題では、出力層をアフィン写像のままにすることがある。
すなわち、出力層を
$$
L_L(\mathbf{h})
=
\mathbf{h}W_L+\mathbf{b}_L
$$
の形にすることがある。
$ $
分類問題では、出力層から得られる実数値ベクトルを logits として扱い、
その後に softmax 関数などを適用して、各クラスに対応する確率ベクトルを得ることがある。
$ $
ただし、文脈によっては、この softmax 関数まで含めて出力層と呼ぶこともある。
Prop&Proof
$L\in\mathbb{N}_{>0}$ とする。$d_0,d_1,\ldots,d_L\in\mathbb{N}_{>0}$ とする。
各 $\ell\in\{1,\ldots,L\}$ に対して、
$$
W_\ell\in\mathbb{R}^{d_{\ell-1}\times d_\ell},
\quad
\mathbf{b}_\ell\in\mathbb{R}^{1\times d_\ell}
$$
とする。
また、各 $\ell\in\{1,\ldots,L\}$ に対して、活性化関数 $\sigma_\ell:\mathbb{R}\to\mathbb{R}$ がアフィン関数であり、ある $c_\ell,r_\ell\in\mathbb{R}$ によって
$$
\sigma_\ell(t)=c_\ell t+r_\ell
\quad
(t\in\mathbb{R})
$$
と書けるとする。
入力を
$$
\mathbf{h}^{(0)}:=\mathbf{x}\in\mathbb{R}^{1\times d_0}
$$
とし、各 $\ell\in\{1,\ldots,L\}$ に対して
$$
\mathbf{a}^{(\ell)}
:=
\mathbf{h}^{(\ell-1)}W_\ell+\mathbf{b}_\ell
\in\mathbb{R}^{1\times d_\ell}
$$
$$
\mathbf{h}^{(\ell)}
:=
\sigma_\ell^{[d_\ell]}(\mathbf{a}^{(\ell)})
\in\mathbb{R}^{1\times d_\ell}
$$
と定める。
このとき、ある
$$
W_*\in\mathbb{R}^{d_0\times d_L},
\quad
\mathbf{b}_*\in\mathbb{R}^{1\times d_L}
$$
が存在して、任意の $\mathbf{x}\in\mathbb{R}^{1\times d_0}$ に対して
$$
\mathbf{h}^{(L)}
=
\mathbf{x}W_*+\mathbf{b}_*
$$
が成り立つ。
すなわち、この多層ネットワーク全体はアフィン写像である。
各 $\ell\in\{1,\ldots,L\}$ に対して、
$$
\sigma_\ell(t)=c_\ell t+r_\ell
\quad
(t\in\mathbb{R})
$$
である。
したがって、任意の $\mathbf{u}=(u_1,\ldots,u_{d_\ell})\in\mathbb{R}^{1\times d_\ell}$ に対して、
$$
\begin{align}
\sigma_\ell^{[d_\ell]}(\mathbf{u})
&=
(\sigma_\ell(u_1),\ldots,\sigma_\ell(u_{d_\ell}))\\
&=
(c_\ell u_1+r_\ell,\ldots,c_\ell u_{d_\ell}+r_\ell)\\
&=
c_\ell\mathbf{u}+r_\ell\mathbf{1}_{1\times d_\ell}
\end{align}
$$
が成り立つ。ただし、
$$
\mathbf{1}_{1\times d_\ell}:=(1,\ldots,1)\in\mathbb{R}^{1\times d_\ell}
$$
とする。
- 各層をアフィン写像として書き直す。
各 $\ell\in\{1,\ldots,L\}$ に対して、
$$ \mathbf{h}^{(\ell)} = \sigma_\ell^{[d_\ell]}(\mathbf{a}^{(\ell)}) $$
であり、
$$ \mathbf{a}^{(\ell)} = \mathbf{h}^{(\ell-1)}W_\ell+\mathbf{b}_\ell $$
である。よって、
$$ \begin{align} \mathbf{h}^{(\ell)} &= \sigma_\ell^{[d_\ell]} \left( \mathbf{h}^{(\ell-1)}W_\ell+\mathbf{b}_\ell \right)\\ &= c_\ell \left( \mathbf{h}^{(\ell-1)}W_\ell+\mathbf{b}_\ell \right) + r_\ell\mathbf{1}_{1\times d_\ell}\\ &= \mathbf{h}^{(\ell-1)}(c_\ell W_\ell) + \left( c_\ell\mathbf{b}_\ell+r_\ell\mathbf{1}_{1\times d_\ell} \right) \end{align} $$
である。ここで、
$$ \widetilde{W}_\ell:=c_\ell W_\ell \in\mathbb{R}^{d_{\ell-1}\times d_\ell} $$
および
$$ \widetilde{\mathbf{b}}_\ell := c_\ell\mathbf{b}_\ell+r_\ell\mathbf{1}_{1\times d_\ell} \in\mathbb{R}^{1\times d_\ell} $$
とおく。
このとき、
$$ \mathbf{h}^{(\ell)} = \mathbf{h}^{(\ell-1)}\widetilde{W}_\ell + \widetilde{\mathbf{b}}_\ell $$
である。
したがって、各層はアフィン写像である。
$ $ - ネットワーク全体をアフィン写像として表す。
各 $r\in\{1,\ldots,L\}$ に対して、ある
$$ W_*^{(r)}\in\mathbb{R}^{d_0\times d_r}, \quad \mathbf{b}_*^{(r)}\in\mathbb{R}^{1\times d_r} $$
が存在して、
$$ \mathbf{h}^{(r)} = \mathbf{x}W_*^{(r)}+\mathbf{b}_*^{(r)} $$
が成り立つことを数学的帰納法で示す。
i) まず $r=1$ のとき、
$$ \mathbf{h}^{(1)} = \mathbf{h}^{(0)}\widetilde{W}_1+\widetilde{\mathbf{b}}_1 = \mathbf{x}\widetilde{W}_1+\widetilde{\mathbf{b}}_1 $$
である。
したがって、
$$ W_*^{(1)}:=\widetilde{W}_1, \quad \mathbf{b}_*^{(1)}:=\widetilde{\mathbf{b}}_1 $$
とおけばよい。
$ $
ii) 次に、ある $r\in\{1,\ldots,L-1\}$ に対して、
$$ \mathbf{h}^{(r)} = \mathbf{x}W_*^{(r)}+\mathbf{b}_*^{(r)} $$
が成り立つと仮定する。
$ $
iii) このとき、
$$ \begin{align} \mathbf{h}^{(r+1)} &= \mathbf{h}^{(r)}\widetilde{W}_{r+1} + \widetilde{\mathbf{b}}_{r+1}\\ &= \left( \mathbf{x}W_*^{(r)}+\mathbf{b}_*^{(r)} \right) \widetilde{W}_{r+1} + \widetilde{\mathbf{b}}_{r+1}\\ &= \mathbf{x} \left( W_*^{(r)}\widetilde{W}_{r+1} \right) + \left( \mathbf{b}_*^{(r)}\widetilde{W}_{r+1} + \widetilde{\mathbf{b}}_{r+1} \right) \end{align} $$
である。ここで、
$$ W_*^{(r+1)} := W_*^{(r)}\widetilde{W}_{r+1} $$
および
$$ \mathbf{b}_*^{(r+1)} := \mathbf{b}_*^{(r)}\widetilde{W}_{r+1} + \widetilde{\mathbf{b}}_{r+1} $$
と定める。
型を確認すると、
$$ W_*^{(r)}\in\mathbb{R}^{d_0\times d_r}, \quad \widetilde{W}_{r+1}\in\mathbb{R}^{d_r\times d_{r+1}} $$
であるから、
$$ W_*^{(r+1)} \in \mathbb{R}^{d_0\times d_{r+1}} $$
である。また、
$$ \mathbf{b}_*^{(r)}\in\mathbb{R}^{1\times d_r}, \quad \widetilde{W}_{r+1}\in\mathbb{R}^{d_r\times d_{r+1}}, \quad \widetilde{\mathbf{b}}_{r+1}\in\mathbb{R}^{1\times d_{r+1}} $$
であるから、
$$ \mathbf{b}_*^{(r+1)} \in \mathbb{R}^{1\times d_{r+1}} $$
である。したがって、
$$ \mathbf{h}^{(r+1)} = \mathbf{x}W_*^{(r+1)} + \mathbf{b}_*^{(r+1)} $$
が成り立つ。
以上より、数学的帰納法によって、任意の $r\in\{1,\ldots,L\}$ に対して、
$$ \mathbf{h}^{(r)} = \mathbf{x}W_*^{(r)} + \mathbf{b}_*^{(r)} $$
が成り立つ。
$ $ - $r=L$ とする。
$r=L$ の場合、ある
$$ W_*^{(L)}\in\mathbb{R}^{d_0\times d_L}, \quad \mathbf{b}_*^{(L)}\in\mathbb{R}^{1\times d_L} $$
が存在して、
$$ \mathbf{h}^{(L)} = \mathbf{x}W_*^{(L)} + \mathbf{b}_*^{(L)} $$
が成り立つ。
そこで、
$$ W_*:=W_*^{(L)}, \quad \mathbf{b}_*:=\mathbf{b}_*^{(L)} $$
とおけば、
$$ W_*\in\mathbb{R}^{d_0\times d_L}, \quad \mathbf{b}_*\in\mathbb{R}^{1\times d_L} $$
であり、任意の $\mathbf{x}\in\mathbb{R}^{1\times d_0}$ に対して、
$$ \mathbf{h}^{(L)} = \mathbf{x}W_*+\mathbf{b}_* $$
が成り立つ。
したがって、この多層ネットワーク全体はアフィン写像である。
$$ \Box$$
この命題より、アフィン活性化関数だけを用いる多層ネットワークは、全体として $1$ つのアフィン写像で表される。
特に、線形活性化関数はアフィン活性化関数の特別な場合であるから、
線形活性化関数だけを用いる多層ネットワークも、全体として $1$ つのアフィン写像で表される。
したがって、層をいくら深くしても、入力から出力への写像としては $1$ つのアフィン写像で表せる範囲を超えない。
$ $
そのため、隠れ層に非線形な活性化関数を用いることは、ニューラルネットワークの表現力を高めるうえで重要である。
関連する結果として、普遍近似定理などで調べると良い(/・ω・)/
関数 $\sigma:\mathbb{R}\to\mathbb{R}$ を、各 $t\in\mathbb{R}$ に対して
$$
\sigma(t):=\frac{1}{1+\exp(-t)}
$$
で定める。
このとき、$\sigma$ は $\mathbb{R}$ 上で微分可能であり、任意の $t\in\mathbb{R}$ に対して
$$
\sigma'(t)
=
\sigma(t)(1-\sigma(t))
$$
が成り立つ。
指数関数 $\exp$ は $\mathbb{R}$ 上で微分可能である。
また、任意の $t\in\mathbb{R}$ に対して
$$
\exp(-t)>0
$$
であるから、
$$
1+\exp(-t)>0
$$
である。
したがって、関数
$$
\sigma(t)=\frac{1}{1+\exp(-t)}
$$
は $\mathbb{R}$ 上で微分可能である。
$ $
任意に $t\in\mathbb{R}$ をとる。
まず、合成関数の微分より、
$$
\begin{align}
\sigma'(t)
&=
\frac{d}{dt}
\left(
1+\exp(-t)
\right)^{-1}
\\
&=
-
\left(
1+\exp(-t)
\right)^{-2}
\cdot
\frac{d}{dt}
\left(
1+\exp(-t)
\right)
\\
&=
-
\left(
1+\exp(-t)
\right)^{-2}
\cdot
\left(
-\exp(-t)
\right)
\\
&=
\frac{\exp(-t)}
{\left(1+\exp(-t)\right)^2}
\end{align}
$$
である。
一方、$\sigma(t)$ の定義より、
$$
\sigma(t)
=
\frac{1}{1+\exp(-t)}
$$
である。また、
$$
\begin{align}
1-\sigma(t)
&=
1-\frac{1}{1+\exp(-t)}
\\
&=
\frac{1+\exp(-t)-1}{1+\exp(-t)}
\\
&=
\frac{\exp(-t)}{1+\exp(-t)}
\end{align}
$$
である。
したがって、
$$
\begin{align}
\sigma(t)(1-\sigma(t))
&=
\frac{1}{1+\exp(-t)}
\cdot
\frac{\exp(-t)}{1+\exp(-t)}
\\
&=
\frac{\exp(-t)}
{\left(1+\exp(-t)\right)^2}
\end{align}
$$
である。
以上より、
$$
\sigma'(t)
=
\frac{\exp(-t)}
{\left(1+\exp(-t)\right)^2}
=
\sigma(t)(1-\sigma(t))
$$
である。
$t\in\mathbb{R}$ は任意であったから、任意の $t\in\mathbb{R}$ に対して
$$
\sigma'(t)
=
\sigma(t)(1-\sigma(t))
$$
が成り立つ。
$$ \Box$$
参考文献


この記事を高評価した人
この記事に送られたバッジ
投稿者


